
En esta entrada se va a implementar una red neuronal desde cero, sin utilizar librerías como Theano (http://deeplearning.net/software/theano/) o TensorFlow (https://www.tensorflow.org). La finalidad de este ejercicio poder comprender mejor cómo funcionan las redes neuronales antes de implementar soluciones más complejas mediante alguna librerías.
Fundamentos de la red neuronal
Las redes neuronales son modelos computacionales mediante los que se pretender reproducir la forma en la que trabajan los cerebros biológicos. En su implementación se utilizan conjuntos de unidades básicas de procesamiento, a las que se les denomina neuronas, organizadas en capas y conectadas entre sí. Cada una de las neuronas agrega sus entradas y realiza una operación sobre ella mediante una función de activación. Los enlaces entre las neuronas trasmiten estos resultados ponderado por un peso que puede incrementar o inhibir la respuesta que llega a la neurona de la siguiente capa. Un esquema se puede ver en la siguiente figura.
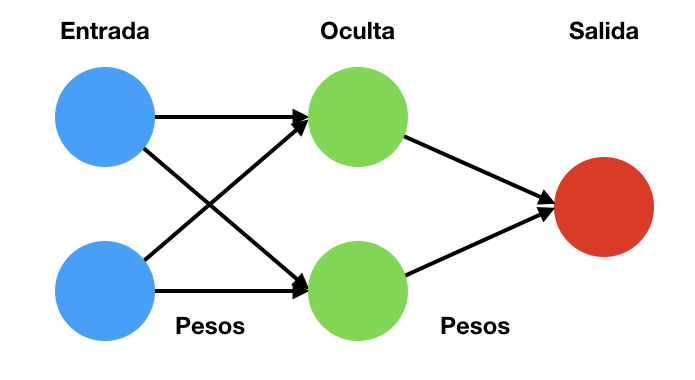
En este esquema se pueden ver que una red neuronal se compone de
- Una capa de entrada
- Una cantidad variables de capas ocultas, en el ejemplo de la figura solamente existe una
- Una capa de salida
- El conjunto de pesos entre las diferentes capas
Además, es necesario definir una función de activación para las neuronas. Esta función de activación no tiene porque ser necesariamente la misma en todas las capas, pudiéndose usar diferentes. Una de las más utilizadas es la función sigmoide que viene definida por la siguiente fórmula:

f(x) = \frac{1}{1-e^{-x}}
Creación de una red neuronal
A partir de lo explicado hasta ahora se puede construir una red neuronal como la que se ha dibujado en la figura. Para ello es necesario obtener los valores de entrada y dos conjuntos de pesos. La respuesta de una red neuronal así definida se puede calcular empleado la siguiente función:
def predict(X, weights_1, weights_2):
layer = sigmoid(np.dot(X, weights_1))
output = sigmoid(np.dot(layer, weights_2))
return output, layer donde la función sigmoid es
def sigmoid(x):
return 1.0/(1+ np.exp(-x))Aplicación de la red neuronal
A modo de ejemplo se puede entrenar un modelo sencillo, por ejemplo, la función lógica XOR que se define como:
| A | B | A XOR B |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
En Python, los parámetros de entrada y la respuesta se pueden escribir como
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) y = np.array([[0], [1], [1], [0]])
Inicialmente los pesos se pueden iniciar de forma aleatoria
weights_1 = np.random.rand(X.shape[1], 2) weights_2 = np.random.rand(2, 1)
donde los presos de la primera capa son un matiz de 2×2, por los dos valores de entrada y por las dos neuronas de la capa intermedia. La segunda capa tiene una matriz de 2×1, por las dos neuronas de la capa intermedia y la única neurona que se ha utiliza en la capa de salida.
En este punto la configuración de la red neuronal ya está definida. Los resultados que se obtendría con la función predict dependerán de los pesos. En la configuración aleatoria actual los valores obtenidos serán completamente erróneos. El proceso de ajuste de estos pesos es el proceso de entrenamiento de la red neuronal.
Entrenamiento mediante propagación hacia atrás
Generalmente, el entrenamiento de las redes neuronales se realiza con un proceso que se llama propagación de hacia atrás (backpropagation). Este es un proceso iterativo en el que inicialmente se obtienen las predicciones de la red con los valores actuales y, posteriormente se corrigen con los pesos propagando el error que se comete hacia atrás. Para esto se ha de definir una función de error, una de las más sencillas es el error cuadrático medio que se define mediante la expresión:
SSE = \frac{1}{N} \sum_{i=1}^N (y_i - \hat(y_i))^2
donde y son los valores y \hat{y} son las predicciones
Ahora que ya se cuenta con una función de error se han de propagar los resultados por la red asignando el error correspondiente a cada uno de los pesos para actualizar estos y minimizar el error de la predicción. Para ello es necesario obtener la derivada la de función de error respecto a los pesos. Al observar la expresión de la función de esfuerzo no se observan los pesos directamente en la misma, por lo que es necesario aplicar la regla de la cadena de cara a obtener los resultados. Esto se puede hacer mediante:
\frac{\partial SSE}{\partial W} = \frac{\partial SSE}{\partial \hat{y}} \frac{\partial \hat{y}}{\partial Wx} \frac{\partial Wx}{\partial W}
donde Wson los pesos y x los valores de entrada. Esto hace que se tenga
\frac{\partial SSE}{\partial W} = 2(y - \hat{y}) Wx(1 - Wx)
Esto se puede implementar en las siguientes líneas:
def backprop(X, y, weights_1, weights_2, learning_rate = 0.1):
output, layer = response(X, weights_1, weights_2)
d_weights_2 = np.dot(layer.T, (2*(y - output) * sigmoid_derivative(output)))
d_weights_1 = np.dot(X.T, (np.dot(2*(y - output) * sigmoid_derivative(output), weights_2.T) * sigmoid_derivative(layer)))
weights_1 += d_weights_1 * learning_rate
weights_2 += d_weights_2 * learning_rate
return ((y - output) **2).sum(), weights_1, weights_2Ahora simplemente se ha de ejecutar este código iterativamente hasta que se obtiene el un resultado:
for i in range(10000):
e, weights_1, weights_2 = backprop(X, y, weights_1, weights_2)
error.append(e)En este punto los resultados son
[[0.07477346], [0.94025856], [0.93999809], [0.0499691 ]
Lo que son unos resultados muy próximos a los esperados. Por otro lado, se puede crear una figura en la que se muestra el error en función del número de iteraciones para comprobar la forma en la que aprende la red.

Conclusiones
En esta entrada se ha implementado una red neuronal básica sin la necesidad de utilizar una librería como Theano o TensorFlow. Al realizar todos los pasos para necesarios para la implementación se comprende mejor el funcionamiento básico de estos algoritmos.
Deja una respuesta