
Seaborn es una librería para Python que permite generar fácilmente elegantes gráficos. Seaborn esta basada en matplotlib y proporciona una interfaz de alto nivel que es realmente sencilla de aprender. Dada su gran popularidad se encuentra instalada por defecto en la distribución Anaconda.
La representación de datos es una tarea clave del análisis de datos. La utilización de una gráfica adecuada puede hacer que los resultados y conclusiones se comuniquen de una forma adecuada o no. Conocer y manejar diferentes herramientas es clave para poder seleccionar la gráfica adecua en cada ocasión. En esta entrada se va a repasar básicamente las funciones que ofrece la librería Seaborn.
Tabla de contenidos
Importación de los datos
Para utilizar la librería Seaborn en primer lugar se han de cargar un conjunto de datos. Para ello se puede utilizar el conjunto de datos de propinas que se encuentra en la propia librería. Para ello se ha de importar el método load_dataset y cargar el conjunto de datos 'tips'. En este conjunto de datos observar diferentes registros de propinas en los que se encuentra la factura total, la propina, el genero del cliente, si es fumador o no, el día de la semana, la franja horaria y el número de comensales. El código para necesario para la importación y los primeros 5 registros se muestran a continuación.

from seaborn import load_dataset
tips = load_dataset("tips")
tips.head()| total_bill | tip | sex | smoker | day | time | size |
| 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
Gráfico de dispersión con Seaborn
Uno de los primeros gráficos que se pueden realizar con estos datos es un gráfico de dispersión. Mediante el cual se puede ver la relación entre dos variables como puede ser la factura y la propina. Este tipo de gráfico se puede obtener mediante el método lmplot al que se le ha de indicar la característica para el cada uno de los ejes y el conjunto de datos. Un ejemplo y el resultado se muestra a continuación:
from seaborn import lmplot
lmplot('total_bill', 'tip', data=tips, fit_reg=False)
En el ejemplo se puede ver una opción fit_reg a la que se ha asignado el valor falso, esto es necesario dado que por defecto realiza la regresión lineal. en caso de que este sea el tipo de gráfico deseado simplemente se ha de omitir esta opción, como en el siguiente ejemplo.
lmplot('total_bill', 'tip', data=tips)
La gráfica así obtenida incluye además de los datos incluye la regresión lineal y el intervalo de confianza. El intervalo de confianza se puede fijar con la propiedad ci, pudiendo indicar el intervalo deseado o None para que se omita. Esta ultima opción es la que se muestra a continuación.
lmplot('total_bill', 'tip', data=tips, ci=None)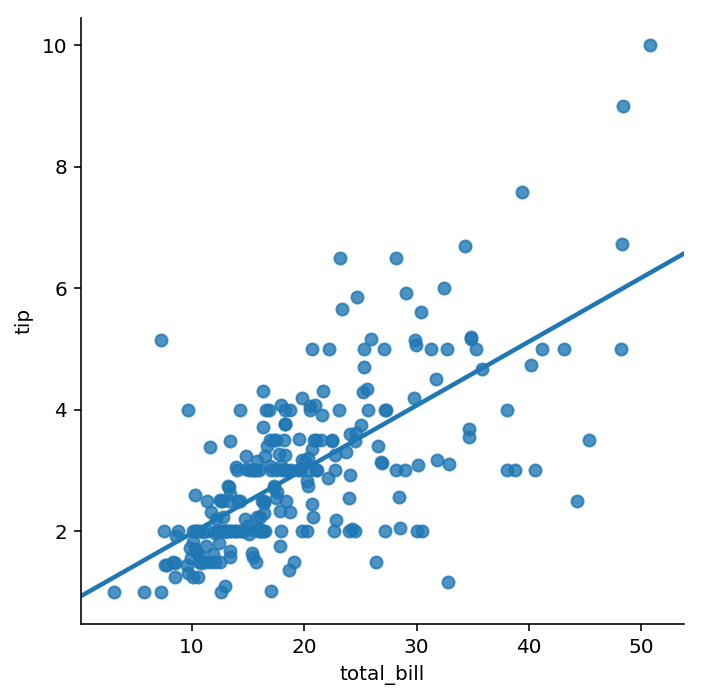
Una característica interesante se lmplot es la posibilidad de representar más de una regresión a la vez. Para ello solamente se le ha de utilizar la propiedad hue a la que le ha de indicar el nombre de la columna de dataframe que se desea utilizar para separar. Por ejemplo, se puede comprobar si el comportamiento de los fumadores y no fumadores es diferente.
lmplot(x="total_bill", y="tip", hue="smoker", data=tips)

Donde se puede apreciar el comportamiento de ambos es ligeramente diferente.
Diagrama de desinad
Los diagramas de densidad se pueden utilizar para ver cómo se comporta distribuciones de datos. En Seaborn este tipo de diamgramas se puede obtener con el método kdeplot. En el conjunto de datos de ejemplo puede ser de interés comprobar cómo se distribuye los valores de la factura, para lo que se puede utilizar el siguiente ejemplo.
from seaborn import kdeplot kdeplot(tips.total_bill)
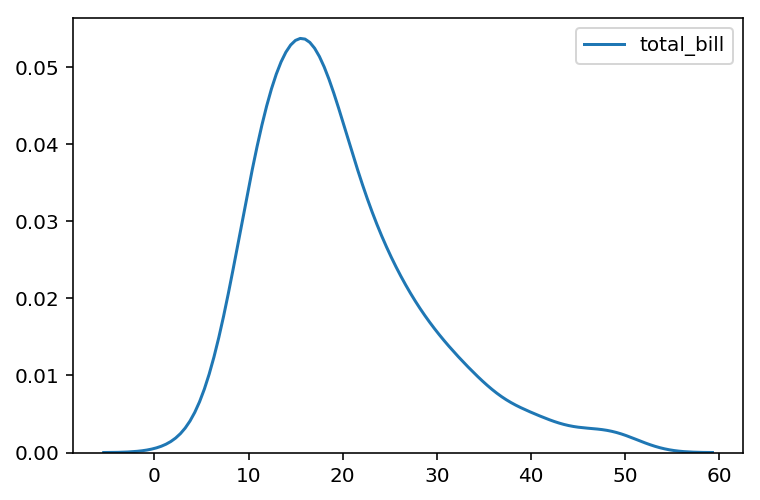
Este tipo de gráficas también se puede obtener en dos dimensiones, para lo que solamente se ha de inyectar dos columnas de datos en la función. Por ejemplo, para ver la distribución de propinas y la factura se puede conseguir con:
kdeplot(tips.tip, tips.total_bill)

Histograma
Otra forma de representar distribuciones de datos es mediante la utilización de histogramas. Para conseguir este tipo de figuras se puede utilizar el método distplot. El cual se usa prácticamente igual que el anterior.
from seaborn import distplot distplot(tips.total_bill)

Si no se desea que el histograma incluya también el diagrama de desinad se ha de indicar asignando el valor falso a la opción kde. Esto es lo que se muestra a continuación:
distplot(tips.total_bill, kde=False)

Alternativamente lo que puede eliminar es el histograma configurando la opción hist a falso.
distplot(tips.total_bill, hist=False
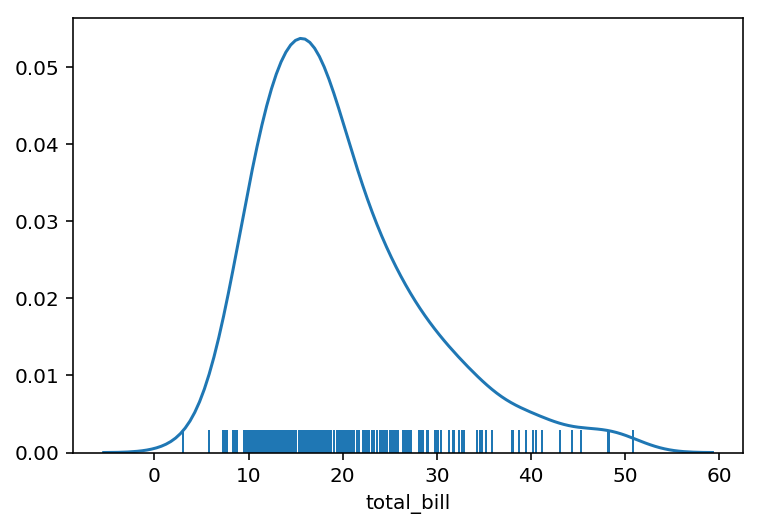
distplot permite agregar también un gráfico de alfombra, para lo que se ha inyectar el valor true a la propiedad rug. Siendo aconsejable eliminar la opción del histograma en este caso.
distplot(tips.total_bill, rug=True, hist=False)
Finalmente se puede hacer el gráfico vertical, para lo que se ha de propiedad vertical ha de ser verdadera.
distplot(tips.total_bill, vertical=True)
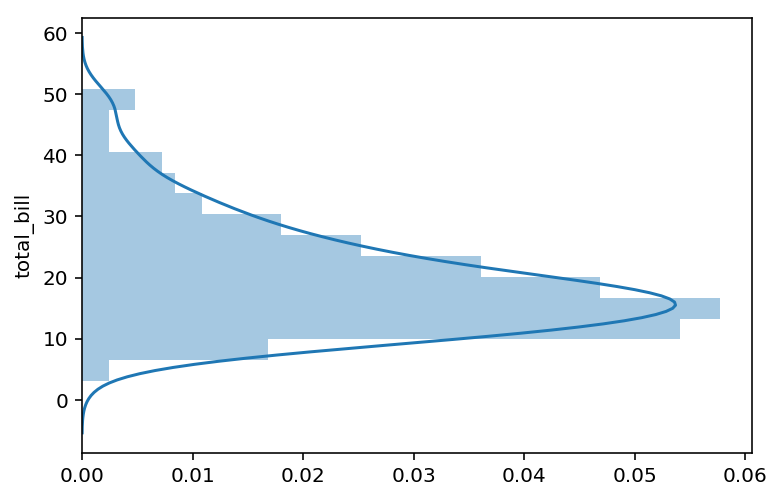
Boxplot
La dispersión de datos se puede comprobar también mediante los gráficos de tipo boxplot. Lo que se pueden obtener mediante el método boxplot, en su versión más sencilla solamente se ha de introducir la columna con los datos a representar.
from seaborn import boxplot boxplot(tips.total_bill)

La orientación horizontal puede no ser del gusto de muchos usuarios, para que la representación sea vertical simplemente se ha mediante la propiedad orient.
boxplot(tips.total_bill, orient="v")

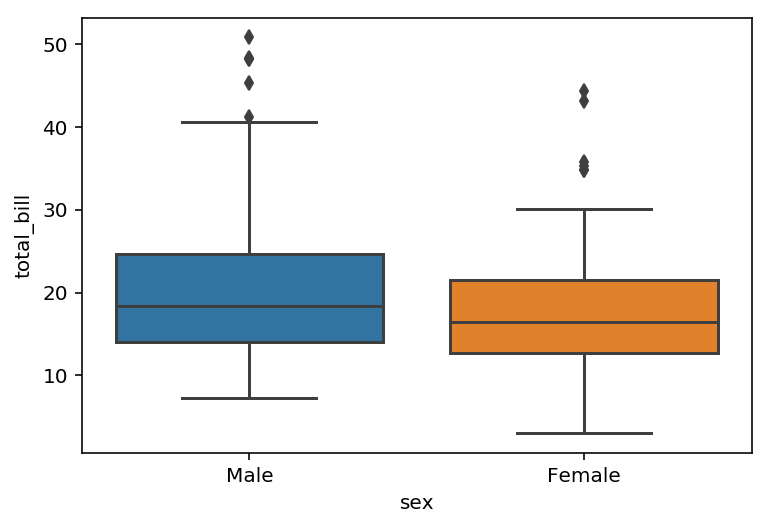
Representar más de una gráfico tipo boxplot permite comparar la dispersión de los datos al poder ver los resultados de forma conjunta. Al igual que el los gráficos de es posible indicar una columna en base a la que dividir los datos de un dataframe. Este comportamiento se puede conseguir indicando un dataframe y el nombre de una columna para el eje x y otra para el y.
boxplot(x="sex", y="total_bill", data=tips)
De forma análoga a los gráficos de dispersión en serabon también se puede dividir las gráficas boxplot en base una tercera columna. Así es posible poder analizar el comportamiento de más de un conjunto de datos. Para ello se ha de utilizar la propiedad hue.
boxplot(x="sex", y="total_bill", hue="smoker", data=tips)

Violin
serabon también incluye los gráficos de tipo violín como alternativa a los boxplot. Esto se utilizan se generan con el método violinplot y su funcionamiento es exactamente igual a los anteriores. Por ejemplo, se puede reproducir el ultimo análisis realizado con esta nueva figura.
from seaborn import violinplot violinplot(x="sex", y="total_bill", hue="smoker", data=tips)

Conclusiones
En esta entrada se han visto los tipos de gráficos más importantes que existen en la librería serabon. Una librería que permite obtener fácilmente elegantes representaciones de conjuntos de datos en Python.
El listado completo de las gráficas disponibles en Seaborn se puede consultar en la documentación de la propia librería.
Excelente presentación muy ameno el aprendizaje
¡Muchas gracias! He revisado demasiados foros, webs, videos jeje y ninguno me había explicado tan bien. 🥺
Excelente artículo! Me ayudo mucho!