
En muchas ocasiones nos podemos encontrar con que los conjuntos de datos no se encuentran agregados en una única tabla. Por ejemplo, los datos personales de los clientes y las transacciones estos han realizado. En estas situaciones la consolidación de los datos se puede realizar tengo una base de datos con SQL. Pero esto no es necesario, la consolidación también se puede realizar directamente en pandas. En esta entrada se explicará cómo unir y combinar dataframes con pandas.
Creación de un conjunto de datos de ejemplo
En primer lugar, antes de explicar los métodos para combinar data frames se ha de crear el conjunto de datos ejemplo. Esto se puede realizar escribiendo directamente los datos. Un dataframe con los datos personales que los clientes se pueden generar con el siguiente código.
import pandas as pd
clients = {'first_name' : ['Oralie' ,'Imojean' ,'Michele', 'Ailbert', 'Stevy'],
'last_name' : ['Fidgeon' ,'Benet' ,'Woodlands', 'Risdale', 'MacGorman'],
'age' : [30 ,21 ,29 ,22, 24]}
clients = pd.DataFrame(clients, columns = ['first_name', 'last_name', 'age'])
clients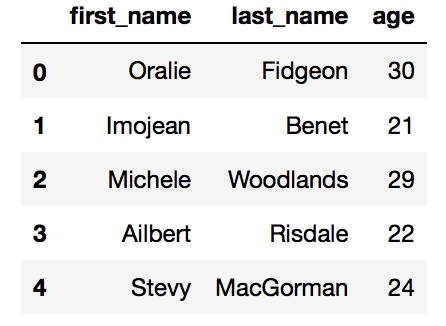
Por otro lado, las transacciones se pueden generar mediante el siguiente conjunto de instrucciones.

invoices = {'invoice_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
'client_id' : [3, 2, 7, 2, 7, 3, 1, 4 ,2, 3, 6, 2],
'amount': [77.91, 24.36, 74.65, 19.75, 27.46, 17.13, 45.77, 81.7, 14.41, 52.69, 32.03, 12.78]}
invoices = pd.DataFrame(invoices, columns = ['invoice_id', 'client_id', 'amount'])
invoices
A continuación, se van a utilizar estos dos conjuntos de datos para enseñar a combinar objetos dataframe en pandas.
Concatenar nuevos registros
Al revisar el conjunto de datos de clientes nos podemos dar cuenta de la falta de uno. Para solucionar este problema simplemente se ha de agregar el registro, para los que se puede utilizar el método concat de pandas. El uso es tremendamente sencillo, simplemente se ha de indicar los datos a concatenar. Esto es lo que se muestra el siguiente ejemplo.
new_clients = pd.DataFrame({'first_name' : ['Rebe'],
'last_name' : ['MacCrossan'],
'age' : [21]},
columns = ['first_name', 'last_name', 'age'])
clients = pd.concat([clients, new_clients])
clients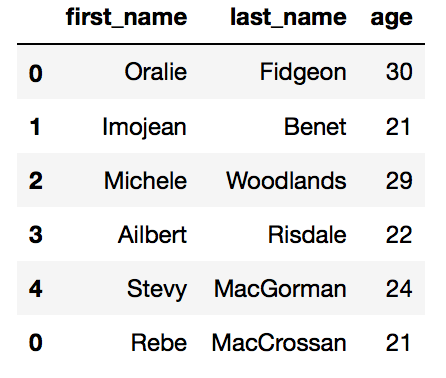
Puede apreciarse que se conserva los índices originales. Eso puede ser un problema que se puede solucionar actualizando los valores tal como se muestra a continuación.
clients.index = range(clients.shape[0])
Una vez solucionado este problema se puede apreciar que no se dispone del identificador de los clientes. Esto también se puede solucionar mediante el método concat. Aunque en esta ocasión, al ser necesario concatenar los valores horizontalmente, se ha de indicar el eje con la opción axis. Esto es lo que se muestra el siguiente código.
ids = pd.DataFrame({'client_id': [1, 2, 3, 4, 5, 6]}, columns = ['client_id'])
clients = pd.concat([ids, clients], axis=1,)
clients
Unión de los dataframes
Después de haber completado la tabla con los datos de los clientes se puede unir esta con la de las transacciones. Para esto se puede utilizar el método merge de pandas. A este método se le ha de indicar las dos variables y la columna utilizará para la unión. El ejemplo eso se realiza mediante la columna client_id. La unión de las dos tablas se puede realizar con la siguiente línea.
pd.merge(clients, invoices, on='client_id')
Cuando el nombre del identificador utilizado para unir las tablas no es el mismo las dos se puede indicar ambos. La forma de realizar esto se muestra a continuación.
pd.merge(clients, invoices, left_on='client_id', right_on='client_id')
Utilizando las opciones por defecto se combinan los registros que están tanto en la lista de clientes, La lista de transacciones. Se puede apreciar que clientes sin transacción Y transacciones en cliente. El tipo de unión utilizada se puede indicar utilizando el parámetro how, existiendo cuatro formas de realizar esta: inner, outer, left y right. El valor por defecto es inner. Para obtener todos los registros se ha de utilizar la opción outer.
pd.merge(clients, invoices, on='client_id', how='outer')

Finalmente si en los data frames existen columnas con el mismo nombre se puede indicar un sufijo para identificar el origen de cada una. De esta manera se puede identificar el origen de cada una de ellas.
pd.merge(clients, clients, on='client_id', suffixes=('_1', '_2'))
Conclusiones
En esta entrada se han visto los métodos disponibles en pandas para unir y concatenar dataframes. Estos métodos son muy útiles para procesar los datos si la necesidad de recurrir a herramientas externas.
Imágenes: Pixabay
Excelente ejemplo, gracias por compartirlo. tienes ejemplo para agrupar groupby ?
Actualmente algunas existen entradas publicadas en las que se usa gropuBy a nivel de ejemplo, pero no hablo específicamente del método en sí. Por ejemplo, puedes consultar: