
Identificar los registros de una lista que no se encuentra en otra es una tarea tediosa. Especialmente cuando los registros no se encuentran ordenados. Por ejemplo, si se desea comparar la lista de los asistentes a dos eventos para identificar los que son nuevos, los que repiten y los que no repiten. Cuando las dos datos se encuentran en un archivo Excel la comparación de los registros de listas se puede realizar con el truco que se muestra a continuación. Incluso mostrando lo resultados de una forma visual.
Identificar los nuevos registros
En la captura de pantalla se puede ver una hoja Excel con la lista de asistentes a un evento en 2017 y la lista del 2018. El listado de los asistentes se ha generado en la web Mockaroo. En la captura de pantalla se puede identificar rápidamente los usuarios del 2017 que no repiten y los usuarios nuevos en 2018.
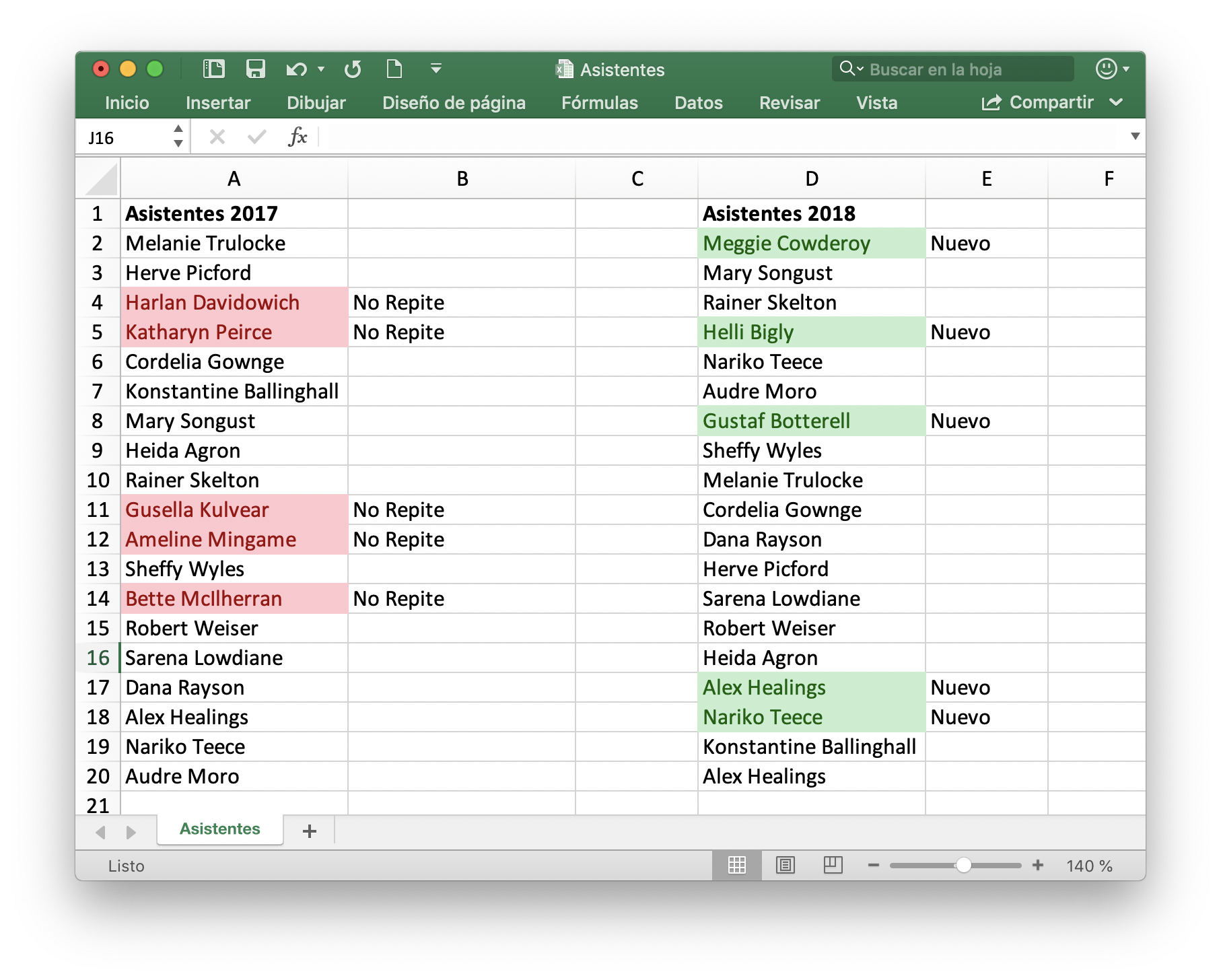
En la columna B se calcula los asistentes del 2017 que no repiten en 2018. Para esto se emplea la función de Excel CONTAR.SI comprobado si el usuario se encuentra en la segunda lista, es decir, la celda B2 es:
=SI(CONTAR.SI($D$2:$D$20;A2)=0;"No Repite";"")
Para identificar a los usuarios nuevos se utiliza el mismo método. Pero en este caso se comprueba si los usuarios de la segunda lista aparecen en la primera. Así en la celda E2 se utiliza la siguiente expresión:

=SI(CONTAR.SI($A$2:$A$20;D2)=0;"Nuevo";"")
Comparación de los registros de listas mediante formatos condicionales
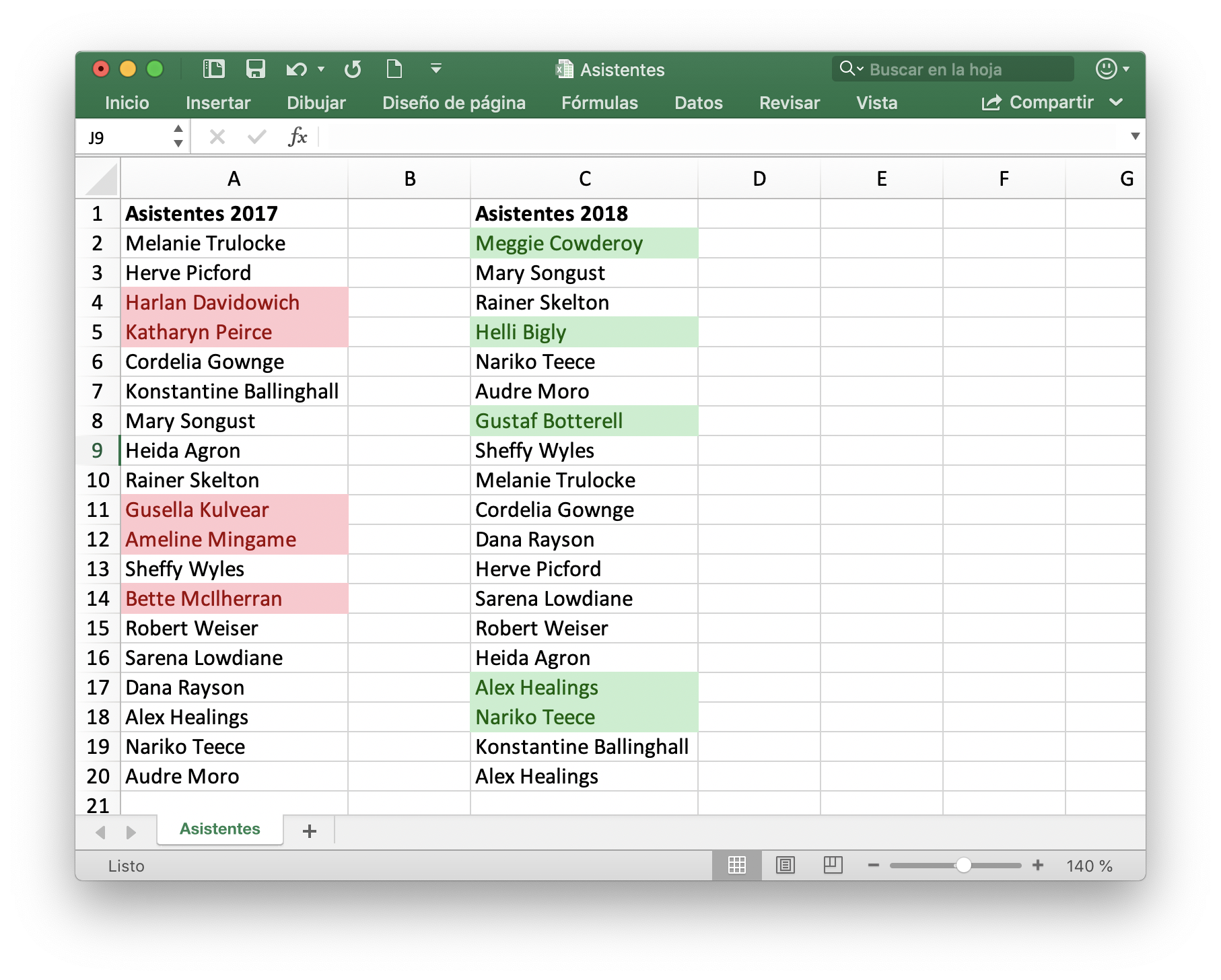
La utilización de formatos condicionales permite identificar más fácilmente los nuevos asistentes o de los que no repiten. Marcando estos con un color diferente y haciendo que la hoja sea más sencilla.
Para aplicar el formato condicional se ha de seleccionar las celdas a las que se desea aplicar. En la barra “Inicio” se ha de acceder al menú “Formato condicional” y en este al submenú “Nueva regla”. Apareciendo la siguiente ventana.
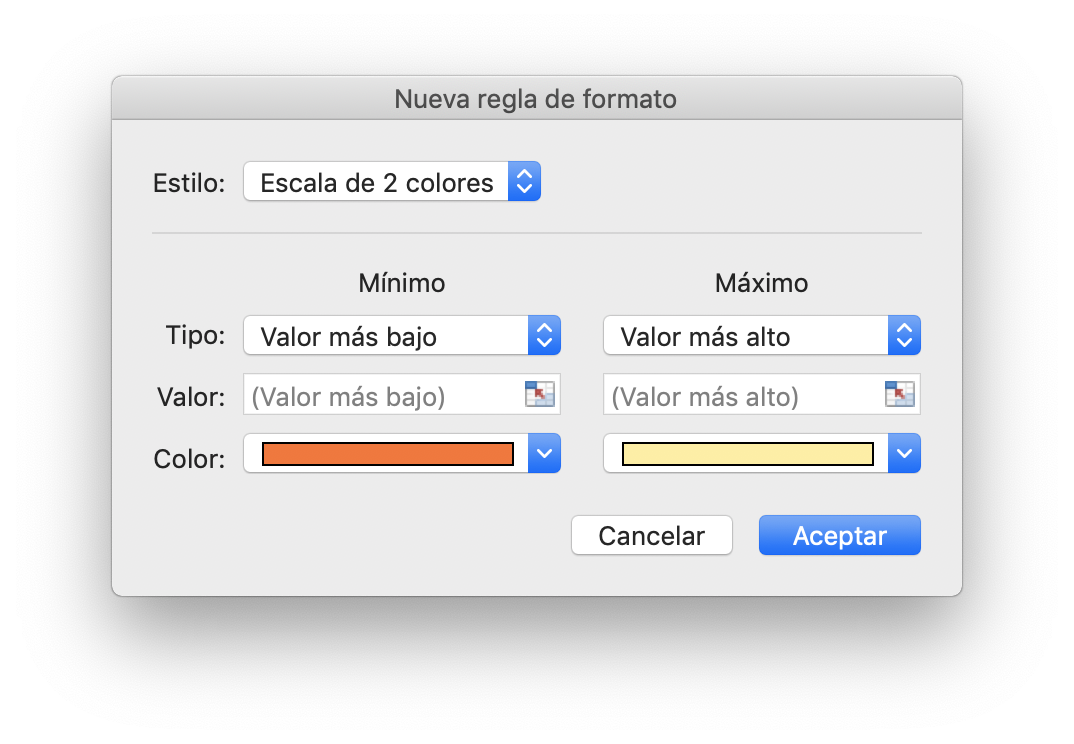
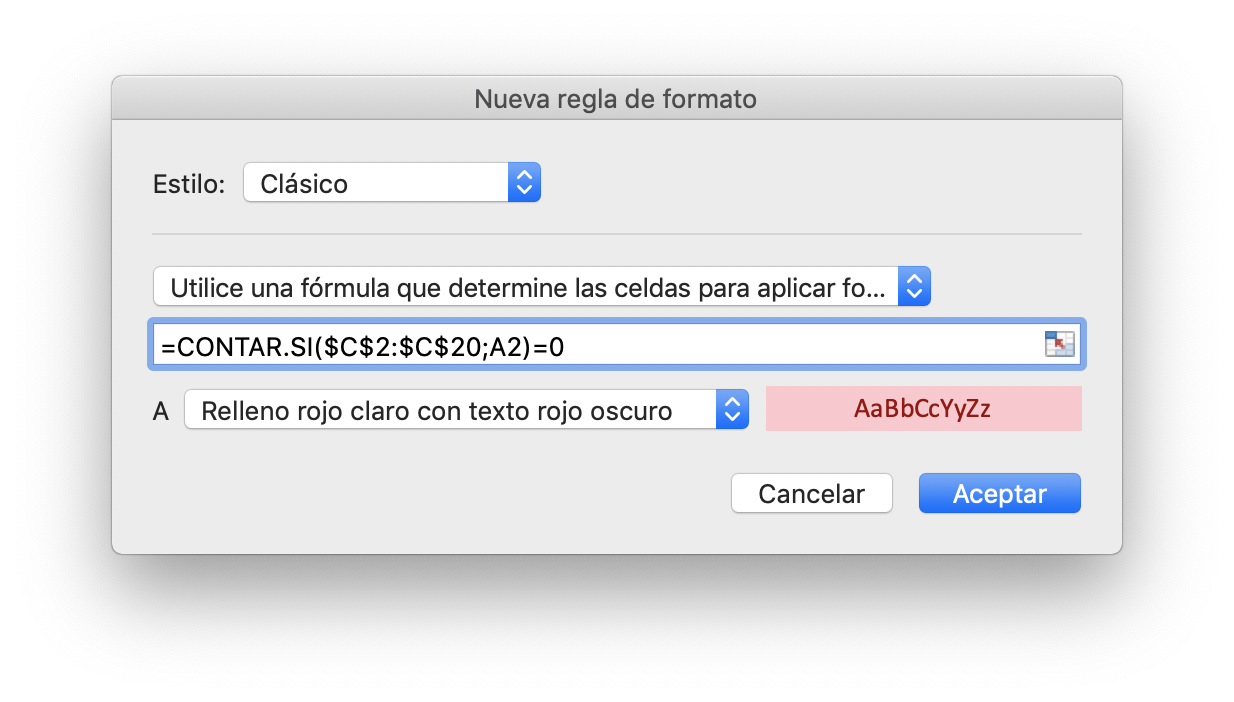
En esta ventana se ha de seleccionar el estilo “Clásico”. Posteriormente se ha de seleccionar la opción “Utilice una fórmula que determine las celdas para aplicar formato.” e introducir la fórmula en la casilla. La será una de las utilizadas anteriormente en las funciones `SI`. Finalmente se ha de seleccionar el formato a utilizar.
Así la hoja de cálculo queda de la forma.
Conclusiones
Se ha visto una forma visual de comparar dos listas con Excel. Incluyendo una forma de resaltar visualmente los resultados mediante la utilización de formatos condicionales. En ciertas ocasiones, como el ejemplo mostrado, este truco puede ser bastante útil.
Imágenes: Pixabay (stux)
Deja una respuesta