En una publicación anterior se vieron algunos de los problemas que muestran los gráficos de dispersión cuando se cuentan con grandes conjuntos de datos, proponiendo en aquella ocasión el uso de los gráficos de Hexbin como alternativa. Otros gráficos que se pueden emplear en estas situaciones son los gráficos de densidad. Unos gráficos en los que se dibujan los contornos en los que la densidad es igual, los cuales se pueden ilustrar con una escala de colores, mostrando de esta forma las áreas donde la densidad de datos es similar.
Gráficos de densidad en Python con Seaborn
Para crear un gráfico de densidad en Python se puede usar la librería Seaborn, en la cual se puede encontrar la función kdeplot(). Antes de crear uno de estos gráficos se puede recordar el problema que presentan los gráficos de dispersión cuando el conjunto de datos es demasiado grande. Para lo que se puede usar el código similar al hablar de los gráficos de Hexbin.
import numpy as np import matplotlib.pyplot as plt # Generar datos aleatorios np.random.seed(1) x = np.dot(np.random.random(size = (2, 2)), np.random.normal(size = (2, 500))).T # Crear el gráfico de dispersión plt.scatter(x[:, 0], x[:, 1]) # Mostrar el gráfico plt.show()

En este ejemplo primero se ha generado un conjunto de datos aleatorios con 500 registros y creado una gráfica de dispersión con ellos. Tal como se puede apreciar en la gráfica, en las zonas donde la densidad de datos es alta los puntos se superponen, lo que puede dar lugar a confusión. Una alternativa en este caso es crear un gráfico de densidad tal como se muestra a continuación.

import seaborn as sns # Crear gráfico de densidad sns.kdeplot(x=x[:, 0], y=x[:, 1])

Un código en el que solamente se ha importado Seaborn y llamado a la función kdeplot() con los datos para los ejes. La gráfica resultante muestra una serie de líneas que representan zonas de igual densidad. Pudiendo apreciar más claramente cómo se reparte esta.
Relleno de las zonas de densidad con una escala de colores
La función kdeplot() de Seaborn cuenta con la propiedad fill que se puede utilizar para indicar si se desea que las zonas se rellene con una escala de colores. Por defecto, como se ha visto en la sección anterior, no se rellena las zonas. Para conseguir que estas se rellenen solamente se debe asignar el valor True a la propiedad.
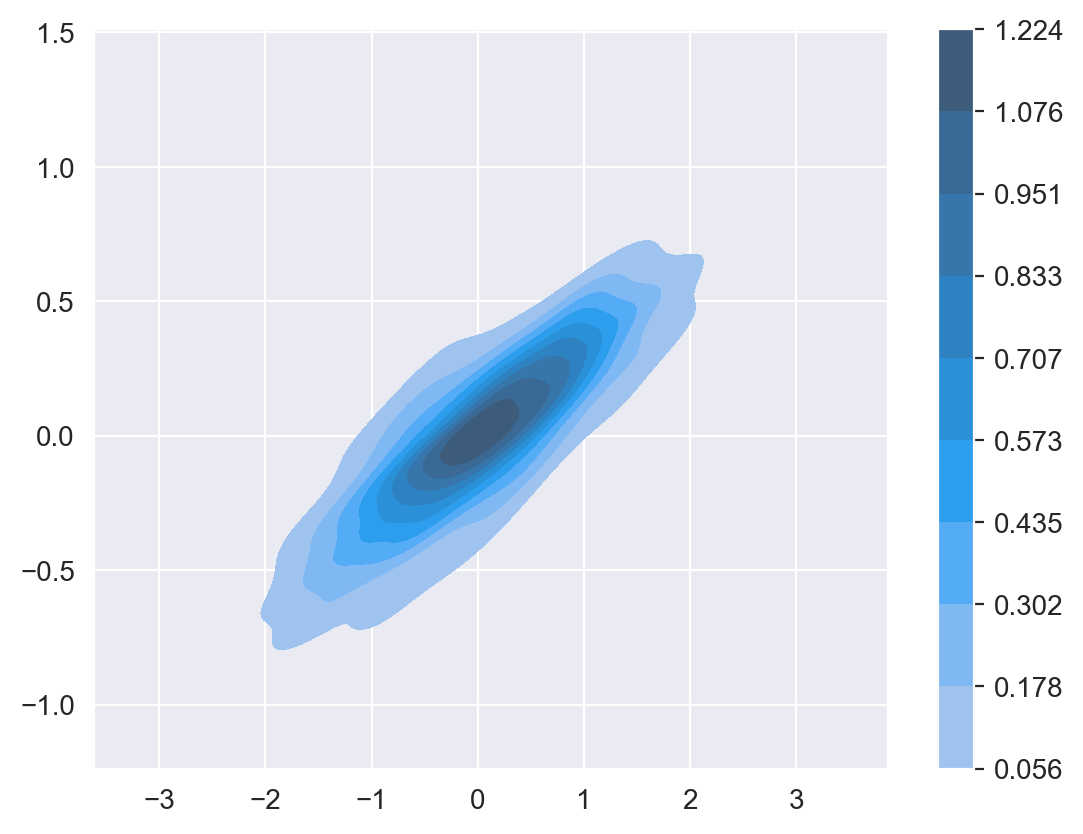
# Crear gráfico de densidad com relleno sns.kdeplot(x=x[:, 0], y=x[:, 1], fill=True, cbar=True)

Cuando se usa una escala de colores para rellenar las zonas de igual densidad puede ser interesante cambiar el valor de la propiedad cbar para indicar que se muestre la escala de colores. Lo que puede ser de gran ayuda para interpretar mejor los datos. Esto es lo que se muestra en el siguiente código.
Como resultado se obtiene una gráfica en la que se puede ver claramente que en la zona central la densidad de puntos está en torno a 1.2 y cuáles son los valores en cada una de las zonas.
Ventajas de los gráficos de densidad
Los gráficos de densidad cuentan con algunas ventajas respeto a los gráficos de hexbin y dispersión para algunos conjuntos de datos tales como:
- Mejor visualización de la distribución: los gráficos de densidad permiten visualizar la distribución de una variable unidimensional de manera más clara que los gráficos de hexbin y dispersión. Mientras que los gráficos de hexbin y dispersión pueden ser útiles para identificar patrones en datos bidimensionales, el gráfico de densidad permite visualizar la distribución de una variable en su totalidad.
- Ofrece más información a la hora de comparar distribuciones: El gráfico de densidad también es útil para comparar la distribución de dos o más variables. Mientras que los gráficos de hexbin y dispersión se centran en la relación entre dos variables, el gráfico de densidad permite comparar la distribución de varias variables en un solo figura.
- Menor probabilidad de sobreexplotación: en los conjuntos de datos con una alta densidad de puntos las gráficas de dispersión pueden sufrir de sobreexplotación, lo que se traduce una mayor dificultad a la hora de interpretar los patrones. Por otro lado, los gráficos de densidad pueden mostrar de manera clara conjunto de datos grandes o con alta densidad de puntos.
Conclusiones
Los gráficos de densidad son una herramienta para la visualización de datos que puede ser de gran ayuda cuando los gráficos de dispersión no son suficientemente precisos. Ofreciendo una mejor interpretación de la distribución de los valores en un plano.
Deja una respuesta