Una de las mejores herramientas para visualizar las relaciones existentes entre múltiples variables son los gráficos de correlación. Gráficos con los que se puede analizar más fácilmente la relaciones. Seaborn, una de las principales bibliotecas de visualización de datos en Python, cuenta con dos funciones mediante las cuales se puede construir estos tipos de gráficos: mapas de calor (heatmap) y gráficos de pares (pairplot). En esta entrada, se mostrará algunas de las opciones que existen para crear gráficos de correlación en Seaborn e interpretar la información proporcionada por estos.
Importar un conjunto de datos
Seaborn cuenta con múltiples conjuntos de datos, los cuales se pueden importar fácilmente con la función load_dataset(). Para facilitar el seguimiento de los ejemplos se usa el conjunto de datos tips que se puede cargar en un DataFrame con el siguiente código.
import seaborn as sns
# Cargar el conjunto de datos "tips" de Seaborn
tips = sns.load_dataset("tips")
# Imprimir los últimos registros del conjunto de datos
print(tips.tail())total_bill tip sex smoker day time size 239 29.03 5.92 Male No Sat Dinner 3 240 27.18 2.00 Female Yes Sat Dinner 2 241 22.67 2.00 Male Yes Sat Dinner 2 242 17.82 1.75 Male No Sat Dinner 2 243 18.78 3.00 Female No Thur Dinner 2
Mapas de calor (Heatmaps)
Los mapas de casos son un método eficaz para visualizar las matrices de correlación. En estas gráficas cada uno de los valores de la matriz se muestra en una celda con un color diferente. Las celdas en las que se observa un valor de correlación cercano a 1, lo que indica una correlación positiva fuerte, se muestran en tonos cálidos (rojos). Por otro lado, las celdas en las que el valor de correlación es cercano a -1, lo que indica una correlación negativa fuerte, se muestran en tonos fríos (azules). Mientras que los valores cercanos a 0, lo que indica una relación nula, se muestran en tonos intermedios.

En Seaborn se puede usar la función heatmap() para representar un mapa de calor a partir de los datos de una matriz de correlación. Para obtener la matriz para el conjunto de datos tips se puede emplear el método corr() disponible en todos los DataFrames de Pandas. A continuación, se puede ver cómo generar el mapa de calor.
# Crear una matriz de correlación para el conjunto de datos "tips" correlation_matrix = tips.corr(numeric_only=True) # Crear un mapa de calor para visualizar la matriz de correlación sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm", center=0)

En este caso se puede apreciar la existencia de una alta correlación entre las tres columnas numéricas. La propina muestra una alta correlación con la factura total y el tamaño de la mesa. Un resultado que es bastante razonable.
Para ver un gráfico con correlaciones positivas y negativas se puede usar otro conjunto de datos, por ejemplo, planets. Este conjunto de datos contiene los datos de exoplanetas como el periodo orbital, la masa, la distancia y el año de descubrimiento. Si se repite el ejercicio se consigue la siguiente gráfica.
# Cargar el conjunto de datos "planets" de Seaborn
planets = sns.load_dataset("planets")
# Imprimir los últimos registros del conjunto de datos
print(planets.tail())
# Crear una matriz de correlación para el conjunto de datos "planets"
correlation_matrix = planets.corr(numeric_only=True)
# Crear un mapa de calor para visualizar la matriz de correlación
sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm", center=0)method number orbital_period mass distance year 1030 Transit 1 3.941507 NaN 172.0 2006 1031 Transit 1 2.615864 NaN 148.0 2007 1032 Transit 1 3.191524 NaN 174.0 2007 1033 Transit 1 4.125083 NaN 293.0 2008 1034 Transit 1 4.187757 NaN 260.0 2008

En este caso ya se puede observar cómo no existe una correlación clara entre la mayoría de las características del conjunto de datos. Pero lo que se puede apreciar es que los valores cercanos a cero son grises, los positivos rojos y los negativos azules.
Gráficos de pares (Pairplot)
Los gráficos de pares permiten visualizar la relación entre múltiples variables mediante el uso de diagramas de dispersión. Además de la dispersión de cada una de las características mediante el uso de histogramas. En estas gráficas se crea una matriz en la que se muestra en cada celda el gráfico de dispersión de una variable frente a otra y, en la diagonal principal, un histograma o gráfico de densidad.
Seaborn cuenta con la función pairplot() para la creación de este tipo de gráficos. El único parámetro necesario para crear la gráfica es el conjunto de datos. Una gráfica de ejemplo se puede crear con el conjunto de datos tips.
# Crear una matriz de dispersión para el conjunto de datos "tips" sns.pairplot(data=tips)
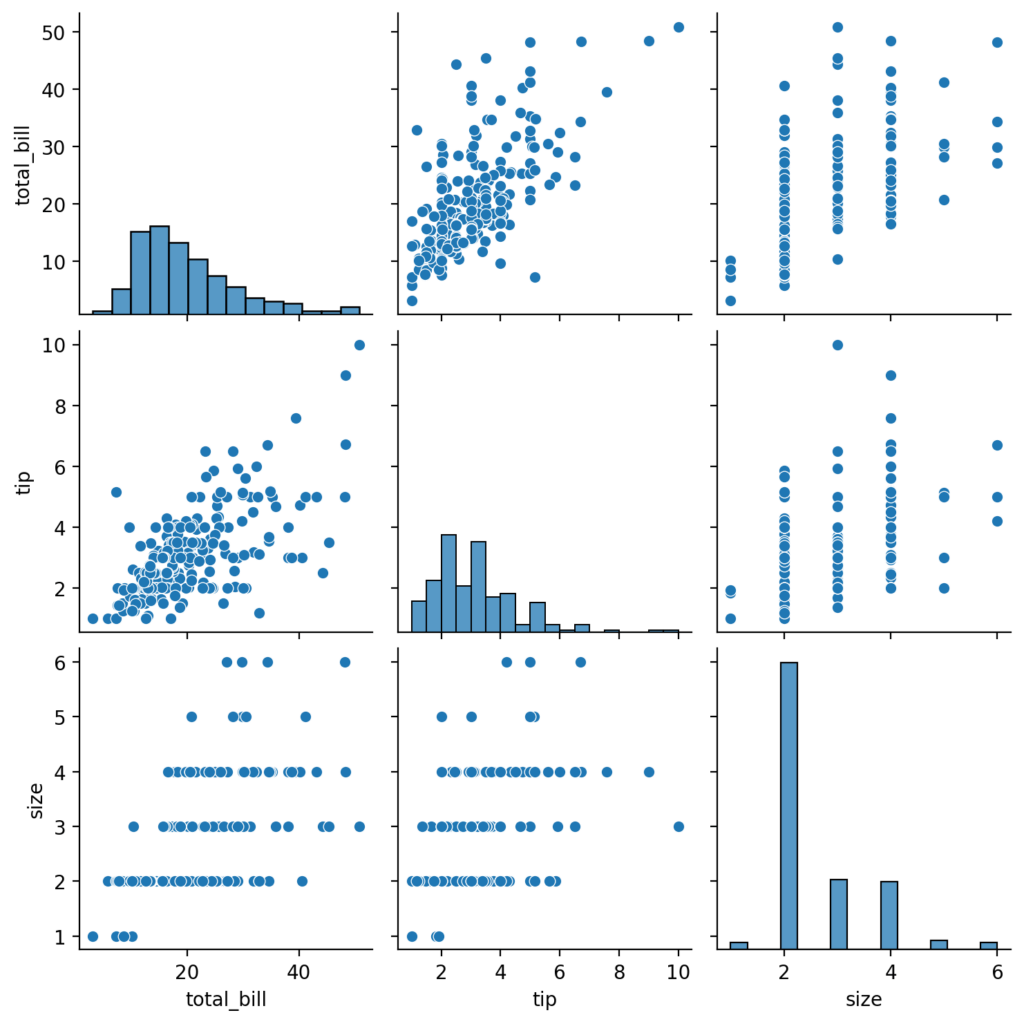
En esta gráfica se puede ver claramente la existencia de una relación lineal entre la propina y la factura total. Mientras que las relaciones entre la propina y el tamaño de la mesa o el tamaño de la mesa y la factura total son menos claras.
Conclusiones
Los gráficos de correlación en Seaborn son una fantástica herramienta para visualizar las relaciones entre las variables en un conjunto de datos. En esta entrada se han analizado las relaciones en dos conjuntos de datos. Mediante el uso de mapas de calor y gráficos de pares se ha podido visualizar las correlaciones entre las variables de los conjuntos de datos tips y planets de Seaborn. Estos gráficos son especialmente útiles para comprender las relaciones y patrones en los datos antes de realizar análisis más detallados.
Me ayudo mucho esta ifnormacionn para mi tarea y entender