
El volumen de datos que las organizaciones generan y deben manejar crece día a día: transacciones, registros de acceso, dispositivos IoT, interacciones en redes sociales o simplemente los logs de las aplicaciones. Para poder extraer valor de toda esta información es necesario contar con sistemas capaces de almacenar, organizar y procesar grandes volúmenes de datos de forma eficiente y segura. Ese es precisamente el objetivo de los Data Lakes.
En esta entrada veremos, paso a paso, cómo crear tu propio Data Lake en Azure utilizando el servicio Azure Data Lake Storage Gen2, el corazón de muchas arquitecturas modernas de datos. Además, al final incluimos un listado de buenas prácticas que te ayudarán a mantener una estructura sólida, escalable y segura.
Tabla de contenidos
Qué es un Data Lake
Un Data Lake (o lago de datos) es un repositorio centralizado que permite almacenar datos en su forma original, sin necesidad de estructurarlos previamente. A diferencia de los Data Warehouses, que requieren definir esquemas y estructuras antes de cargar los datos, un Data Lake admite cualquier tipo de información: desde archivos CSV o JSON hasta imágenes, vídeos, documentos o logs de servidores.
Esto resulta especialmente útil en entornos donde la exploración y el análisis son continuos. Por ejemplo, un equipo de científicos de datos puede almacenar grandes volúmenes de datos brutos para entrenar modelos de machine learning, mientras que otro equipo puede transformarlos o agregarlos para la creación de informes de negocio.

En Azure, el servicio que con el que se puede implementar este concepto es Azure Data Lake Storage Gen2 (ADLS Gen2). Está construido sobre Azure Blob Storage, pero incorpora características adicionales diseñadas para el análisis masivo de datos, como una jerarquía de directorios nativa, control de permisos granular y optimización para frameworks distribuidos como Apache Spark o Hadoop.
Si quieres profundizar más, puedes consultar la entrada que publicamos recientemente sobre cómo se complementan los Data Lake y Data Warehouse en una organización moderna.
Requisitos previos
Antes de comenzar con el tutorial, asegúrate de cumplir los siguientes requisitos:
- Contar con una suscripción activa de Microsoft Azure con acceso al Portal de Azure.
- Disponer de un usuario con permisos para crear recursos (al menos Contributor en el ámbito donde crearás el Resource Group).
- Conocer la política de seguridad y cumplimiento de tu organización (regiones permitidas, restricciones de acceso público, cifrado, retención, etc.).
Si todavía no tienes acceso a una suscripción de Azure, puedes crear una cuenta gratuita que incluye 200 USD de crédito durante 30 días. Es más que suficiente para seguir este tutorial y probar otros servicios de la plataforma.
Creación de un grupo de recursos
En Microsoft Azure, un grupo de recursos (resource group) es una unidad lógica que permite organizar y administrar los recursos relacionados como un proyecto único. Como primer paso para crear un Data Lake en Azure, es contar con un grupo de recursos. Si aún no tienes uno, deberás crear uno nuevo.
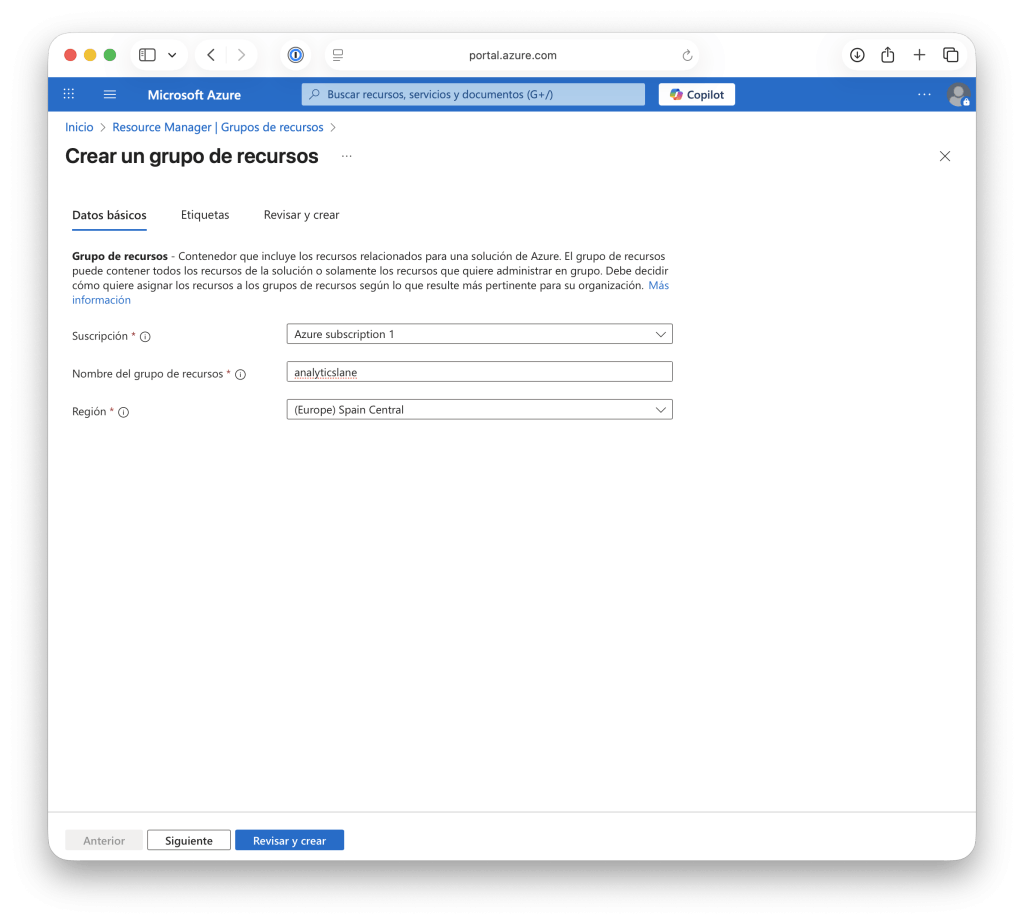
Para hacerlo, accede al portal de Azure y dirígete a la sección Grupos de recursos, luego haz clic en Crear. A continuación, deberás indicar los siguientes valores:
- La suscripción de Azure que vas a utilizar.
- El nombre del grupo de recursos (por ejemplo,
analyticslane). - La región donde se creará el recurso. Normalmente se recomienda elegir la más cercana a la ubicación de los usuarios o aquella definida por la política de tu organización.
Una vez completados los campos, selecciona Revisar y crear para verificar la configuración y, finalmente, haz clic en Crear.
Creación del recurso base en Azure
El siguiente paso para construir tu Data Lake es crear una cuenta de almacenamiento en Azure. Este será el “contenedor” principal donde residirán los datos. Desde el portal de Azure, sigue esta ruta: Crear un recurso → Almacenamiento → Cuenta de almacenamiento.
En esta página deberás definir los parámetros básicos del recurso:
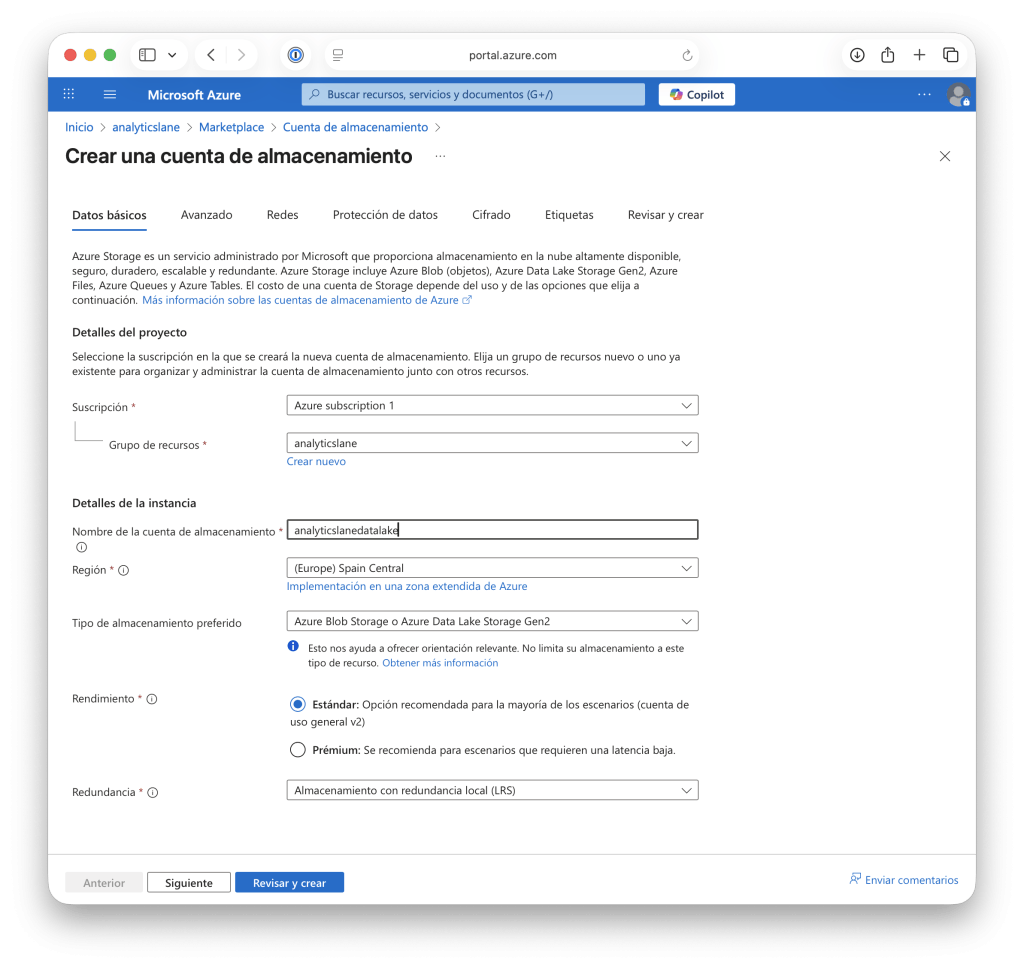
- Nombre de la cuenta: debe ser único para todo Azure, ya que se usará para acceder al recurso. Se recomienda usar un prefijo que identifique el proyecto, por ejemplo, para nuestro Data Lake usaremos:
analyticslanedatalake. - Región: selecciona la más cercana a tus usuarios o sistemas de origen, entre las permitidas por la política de la organización, para reducir la latencia.
- Tipo de rendimiento: Standard suele ser suficiente para la mayoría de los escenarios; el tipo Premium (con un coste mayor) esta recomendado solo si necesitas baja latencia o trabajas con archivos muy pequeños.
- Redundancia: utiliza LRS (solo local) para entornos de prueba y GRS (con redundancia geográfica y un mayor coste) para entornos de producción.
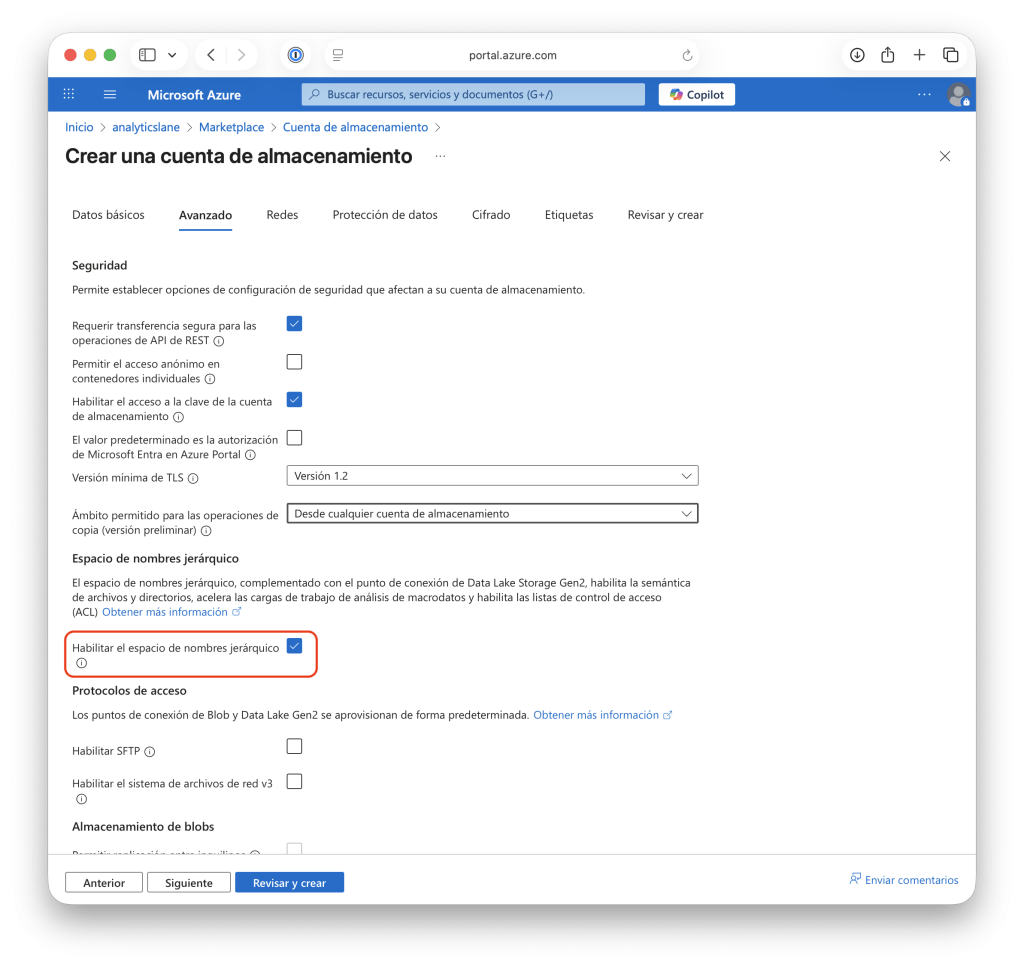
- En la pestaña Avanzado, activa la opción Habilitar el espacio de nombres jerárquicos, que es lo que convierte la cuenta en un Data Lake. Esta opción permite gestionar rutas y permisos a nivel de carpeta.
Cuando hayas completado todos los pasos, selecciona Revisar y crear, y luego haz clic en Crear. En pocos minutos, Azure desplegará la cuenta y tendrás una base completamente escalable y segura, capaz de almacenar terabytes o incluso petabytes de datos.
Estructura interna del Data Lake
Tener un Data Lake sin una estructura clara puede convertirlo rápidamente en un “pantano de datos” (data swamp), donde resulta difícil saber qué datos existen, su nivel de procesamiento y cómo utilizarlos. Por eso, es fundamental organizar el Data Lake en capas lógicas que reflejen el nivel de procesamiento y madurez de los datos.
Una práctica común es estructurar el Data Lake en tres capas principales, que suelen incluir:
- Raw (Bruta): contiene los datos tal como llegan desde las fuentes —APIs, sensores, logs, etc.— sin tratar. El objetivo es preservar la forma original de los datos para futuras referencias o reprocesamientos.
- Processed (Procesada): en esta capa los datos ya se encuentran limpios, filtrados y estandarizados. Por ejemplo, sin duplicados, con nombres de columnas consistentes y formatos de fecha unificados.
- Curated (Curada o de Consumo): es la capa más cercana al negocio y al análisis. Los datos suelen estar agregados, combinados y listos para su uso en dashboards, informes o modelos de machine learning.
Puedes implementar esta jerarquía utilizando contenedores o carpetas dentro de tu Data Lake. Por ejemplo:
/raw/sales/2025/10/ /processed/sales/2025/10/ /curated/sales/2025/10/
Esta organización permite que el flujo de datos sea transparente y fácil de mantener: primero se cargan los datos en raw, luego se procesan en processed, y finalmente se almacenan los datos finales en curated para su consumo. Además, una estructura clara como esta facilita la automatización con herramientas como Azure Data Factory, que pueden mover y transformar archivos entre capas siguiendo reglas predefinidas.
Control de acceso y seguridad
La seguridad es uno de los pilares más importantes en cualquier entorno de datos. Un Data Lake puede contener información sensible —como datos financieros, personales o estratégicos—, por lo que es fundamental definir quién puede acceder y con qué permisos a cada dato.
En Azure, el control de acceso y la seguridad se gestionan principalmente mediante tres mecanismos:
- Roles de Azure (RBAC): permiten asignar permisos globales sobre la cuenta de almacenamiento. Por ejemplo, el rol Storage Blob Data Contributor otorga acceso de lectura y escritura a todos los contenedores de la cuenta.
- Listas de Control de Acceso (ACLs): permiten definir permisos a nivel de carpeta o archivo, lo que es ideal en entornos colaborativos donde distintos equipos requieren acceso a diferentes áreas del lago.
- Azure Active Directory (AAD): gestiona la autenticación de usuarios y servicios, evitando el uso de contraseñas y facilitando la administración centralizada.
Una buena práctica es asignar identidades administradas a los servicios que interactúan con el Data Lake (por ejemplo, Azure Databricks o Data Factory). De esta manera, los servicios se autentican automáticamente sin necesidad de almacenar credenciales en el código o en configuraciones externas.
Además, se recomienda habilitar cifrado en reposo (Encryption at Rest) y cifrado en tránsito (Encryption in Transit) para proteger los datos tanto cuando están almacenados como durante su transferencia entre equipos.
Carga y exploración de datos
Una vez configurado el Data Lake y definidos los permisos, llega el momento de cargar los datos. Azure ofrece varias herramientas según tus necesidades específicas y el volumen de información:
- Azure Portal: útil para pruebas rápidas. Permite subir archivos manualmente desde el navegador.
- Azure Storage Explorer: aplicación gratuita de escritorio que facilita la gestión de archivos, carpetas y permisos.
- Azure Data Factory o Synapse Pipelines: ideales para crear flujos automatizados de ingestión de datos desde múltiples orígenes, como bases de datos SQL, APIs o archivos FTP.
- CLI o SDK de Azure: permiten automatizar la carga desde scripts o integrarlos en pipelines de CI/CD.
Una vez cargados los datos, puedes explorarlos con herramientas analíticas como Azure Synapse Analytics, Databricks o incluso Power BI, conectándote directamente al Data Lake mediante el conector ADLS Gen2.
Esta integración es una de las grandes ventajas del ecosistema de Azure: el Data Lake no es solo almacenamiento, sino una fuente viva de datos que puede ser utilizada en tiempo real para análisis, modelado o visualización.
En una futura entrada veremos cómo cargar datos en un Data Lake desde Python, aprovechando su potencial para automatización y análisis avanzado.
Buenas prácticas para un Data Lake en Azure
Antes de finalizar, es importante recordar algunas buenas prácticas al crear y mantener un Data Lake en Azure:
- Usa una nomenclatura coherente para recursos, carpetas y archivos. Esto facilita la automatización y la trazabilidad.
- Aplica una estructura por capas (
raw,processed,curated) y organiza los datos por dominio o fuente. - Documenta tus datasets: incluye metadatos sobre origen, fecha, formato y transformaciones aplicadas.
- Automatiza siempre que sea posible: evita cargas manuales y utiliza pipelines reproducibles.
- Habilita control de versiones y auditoría para rastrear qué cambios se hicieron y cuándo.
- Aplica políticas de acceso de mínimo privilegio y evita el uso de claves de acceso compartidas.
- Monitorea el uso y el costo del almacenamiento usando las herramientas de métricas y alertas de Azure.
- Crea entornos separados para desarrollo, pruebas y producción, ya sea mediante cuentas distintas o mediante prefijos en las rutas.
Seguir estas prácticas te ayudará a mantener un Data Lake ordenado, seguro y escalable, evitando que se convierta en un “pantano de datos” (data swamp).
Conclusiones
Crear un Data Lake en Azure es un paso clave dentro de cualquier estrategia moderna de datos. Con unos pocos pasos puedes disponer de una plataforma segura, escalable y flexible, capaz de centralizar toda la información de tu organización y servir como base para análisis avanzados, modelos de machine learning o la creación de informes.
En la siguiente entrada exploraremos cómo automatizar la carga y transformación de datos hacia este Data Lake usando Python, construyendo un flujo de ingestión completo y reproducible.
Nota: La imagen de este artículo fue generada utilizando un modelo de inteligencia artificial.
Deja una respuesta