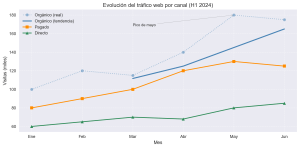
Tienes los datos de tráfico web de los últimos cinco meses desglosados por canal: orgánico, pagado y directo. Quieres saber cuál está creciendo más rápido y si hay algún mes en que algo cambió. Un gráfico de barras te mostraría los valores puntuales, pero no la historia que hay detrás. Para eso necesitas un gráfico de líneas.En esta entrada aprenderás a construir gráficos … [Leer más...] acerca de Cómo comparar tendencias con gráficos de líneas en Matplotlib: guía práctica paso a paso
Python
Python es un lenguaje de programación interpretado con una filosofía basada en la legibilidad del código. Un lenguaje que gracias posee un gran ecosistema de librerías para la ciencia de datos. Por lo que es uno de los más populares en la actualidad entre los científicos de datos. Además, es uno de los lenguajes más deseados y adorados por los programadores según las encuestas de Stack Overflow.
Python es un lenguaje de programación interpretado de propósito general que obliga al uso de una sintaxis clara, gracias a la cual el código es altamente legible. Siendo un lenguaje potente y fácil de aprender. Además, permite utilizar múltiples paradigmas de programación. Lo que permite usar desde programación orientada a objetos, pasando por programación imperativa o funcional.
Los paquetes de Python más utilizados por los científicos son:
- NumPy: permite el tratamiento de datos basados en matrices,
- Pandas: ideal para la manipulación de datos heterogéneos mediante objetos DataFrame,
- SciPy: implementa tareas habituales en computación científica,
- Matplotlib: facilita la visualización de datos y scikit-learn creación de modelos de aprendizaje automático.
Las publicaciones de esta sección versan sobre estas librerías y las bases del lenguaje.
Subplots en Matplotlib: cómo organizar múltiples gráficos en una sola figura
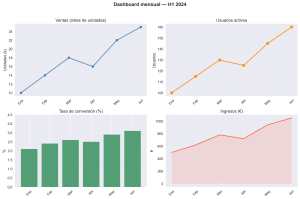
Llevas un rato analizando datos y tienes cuatro gráficos abiertos en ventanas separadas: ventas, usuarios, conversión e ingresos. Para comparar cualquier par de ellos tienes que cambiar de ventana, recordar lo que acabas de ver y volver. Tu cerebro está haciendo el trabajo que debería hacer el gráfico.La solución es tan simple como reunirlos todos en una sola figura usando … [Leer más...] acerca de Subplots en Matplotlib: cómo organizar múltiples gráficos en una sola figura
Cómo comparar datos con barras en Matplotlib: agrupadas, apiladas y porcentuales
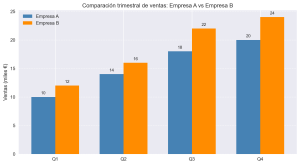
Tienes los datos de ventas de tres productos en dos años distintos y quieres saber cuál creció más. Podrías hacer dos gráficos separados… pero tu cerebro tardaría el doble en extraer conclusiones. La solución es un gráfico de barras comparativo, y en esta entrada verás exactamente cómo construirlo en Python con Matplotlib, paso a paso.En concreto, veremos tres técnicas … [Leer más...] acerca de Cómo comparar datos con barras en Matplotlib: agrupadas, apiladas y porcentuales
Faker en Python: qué es, para qué sirve y cómo generar datos sintéticos realistas

Tanto en el desarrollo de software como en la ciencia de datos existe un problema recurrente: necesitamos datos, pero no podemos usar datos reales. A veces porque aún no existen —por ejemplo, durante las primeras fases de desarrollo de una aplicación— y otras porque los datos disponibles contienen información sensible que no puede utilizarse libremente. Sin embargo, para probar … [Leer más...] acerca de Faker en Python: qué es, para qué sirve y cómo generar datos sintéticos realistas
Cómo ejecutar JavaScript desde Python: Guía práctica con js2py

Aunque Python y JavaScript son lenguajes muy distintos en su propósito y ecosistema, no es raro encontrarnos en situaciones en las que necesitamos integrar ambos. Tal vez queremos reutilizar una función compleja escrita en JavaScript, o simplemente acceder a una librería que no existe (o no está tan madura) en el ecosistema Python. En esos casos, poder ejecutar código … [Leer más...] acerca de Cómo ejecutar JavaScript desde Python: Guía práctica con js2py
Cómo enviar correos desde Python utilizando Brevo: Automatiza tus notificaciones con scripts eficientes

En un artículo anterior vimos cómo enviar correos desde PowerShell utilizando Brevo, una plataforma de comunicación que permite enviar correos electrónicos, SMS y mensajes de WhatsApp desde aplicaciones y scripts. Esta solución es especialmente útil para automatizar notificaciones en procesos automáticos, logs y tareas de mantenimiento.En este tutorial abordaremos el mismo … [Leer más...] acerca de Cómo enviar correos desde Python utilizando Brevo: Automatiza tus notificaciones con scripts eficientes
Análisis de Redes con Python

Durante nuestra serie sobre análisis de redes en R, exploramos en profundidad diversas métricas de centralidad utilizando el paquete igraph. En esta entrada, veremos cómo reproducir esos mismos análisis en Python mediante la biblioteca networkx.El objetivo es ofrecer una visión paralela que permita a los lectores comparar ambos entornos —R y Python— y elegir el más adecuado … [Leer más...] acerca de Análisis de Redes con Python
Cómo exportar un DataFrame de Pandas a Markdown en Python

La biblioteca Pandas se ha consolidado como una herramienta fundamental en Python para el tratamiento y análisis de datos tabulares. Por ello, es muy común trabajar con objetos DataFrame cuando se manipulan datos que luego se desean compartir, ya sea en informes, documentación técnica o publicaciones web. Una de las formas más fáciles de compartir la información es exportando … [Leer más...] acerca de Cómo exportar un DataFrame de Pandas a Markdown en Python
Cómo iterar sobre diccionarios usando bucles for en Python

Uno de los aspectos más destacables de Python es su facilidad para manejar estructuras de datos complejas de forma intuitiva. Entre ellas, los diccionarios ocupan un lugar fundamental. Debido a que permiten almacenar pares clave-valor de manera eficiente, son ampliamente utilizados en ciencia de datos, desarrollo web, automatización de tareas, inteligencia artificial y … [Leer más...] acerca de Cómo iterar sobre diccionarios usando bucles for en Python
¿Cómo comprobar si un archivo existe en Python sin generar excepciones?

Uno de los aspectos fundamentales al trabajar con archivos es saber si un archivo existe antes de intentar acceder a él. Comprobar su existencia no solo hace que el código sea más robusto, sino también más limpio, legible y fácil de mantener.En Python —como en muchos otros lenguajes— intentar abrir o manipular un archivo que no existe puede generar errores que interrumpen … [Leer más...] acerca de ¿Cómo comprobar si un archivo existe en Python sin generar excepciones?
¿Cómo puedo fusionar dos diccionarios en Python?

A la hora de trabajar con Python, uno de los tipos de datos más utilizados es el diccionario (dict). Algo que se debe a su capacidad para almacenar los datos en formato clave-valor de una forma eficiente, siendo la solución ideal para representar las configuraciones, realizar recuento de elementos y para estructuras complejas, entre muchas otras tareas. Por eso, la necesidad de … [Leer más...] acerca de ¿Cómo puedo fusionar dos diccionarios en Python?
Entornos virtuales en Python con Poetry

Al desarrollar software, es fundamental mantener los entornos de trabajo controlados y reproducibles. Esto permite detectar y corregir errores con mayor facilidad. En Python, los entornos virtuales permiten aislar las dependencias de un proyecto y evitar conflictos entre diferentes versiones de librerías. Gracias a esto, la gestión de dependencias y el proceso de publicación de … [Leer más...] acerca de Entornos virtuales en Python con Poetry