
El formato JSON (JavaScript Object Notation) se ha convertido en el estándar de facto para almacenar y transmitir datos estructurados. Es ligero, fácil de leer tanto para personas como para máquinas, y es compatible con prácticamente todos los lenguajes de programación modernos.
Ahora bien, si queremos almacenar este tipo de datos en una base de datos SQL Server, habitualmente surge una pregunta: ¿es necesario transformar los datos en tablas tradicionales?
La respuesta es no necesariamente. Desde SQL Server 2016, el motor de base de datos incluye soporte nativo para JSON, lo que permite almacenarlo directamente en campos de tipo NVARCHAR y aprovechar una serie de funcionalidades integradas de la base de datos, entre las que se pueden destacar:
- Consultar propiedades específicas como si fueran columnas.
- Modificar valores dentro del JSON sin sobrescribir todo el documento.
- Convertir datos tabulares a JSON limpio.
- Descomponer arrays en filas para realizar análisis más avanzados.
En esta entrada se explicará cómo almacenar y manipular datos JSON en SQL Server de forma eficiente, mostrando ejemplos prácticos de cómo leer propiedades, extraer información, modificar valores y generar resultados en formato JSON directamente desde tus consultas SQL.
Tabla de contenidos
Por qué usar JSON en SQL Server
En los sistemas relacionales tradicionales, los datos se organizan en tablas con columnas bien definidas y relaciones claras entre ellas. Este enfoque funciona muy bien cuando la estructura de los datos es estable. Sin embargo, en muchos escenarios actuales los datos no son completamente estáticos, por lo que es habitual trabajar con información semiestructurada o que cambia de forma con el tiempo. En esos casos, JSON se convierte en una alternativa ideal.

Algunos ejemplos donde JSON es especialmente útil en SQL Server son:
- Datos con estructura variable: cuando una integración externa devuelve hoy un número, pero mañana un objeto con propiedades adicionales.
- Metadatos dinámicos: entidades que contienen información opcional o personalizada que no justifica crear columnas adicionales o tablas auxiliares.
- Registros de logs o trazas: JSON es perfecto para almacenar eventos con estructura flexible, sin modificar el esquema cada vez que se añade un nuevo campo.
- Configuraciones y plantillas: muchos sistemas usan JSON para describir reglas, comportamientos o parámetros dinámicos.
Además, JSON es un formato auto-descriptivo que se integra naturalmente con lenguajes como JavaScript, Python o C#, lo que facilita el intercambio de datos entre las aplicaciones y la base de datos sin necesidad de transformaciones complejas.
Cómo almacenar JSON en SQL Server
A diferencia de otras bases de datos relacionales como PostgreSQL, SQL Server no dispone de un tipo de dato JSON nativo. Sin embargo, desde SQL Server 2016 se pueden almacenar y procesar JSON utilizando columnas de tipo NVARCHAR(MAX), un enfoque que ofrece flexibilidad y compatibilidad total con las funciones JSON que el propio motor de SQL Server incorpora.
Por ejemplo, podemos crear una tabla Operaciones que almacene un identificador y un campo con el contenido JSON de cada operación:
CREATE TABLE Operaciones (
Id INT IDENTITY PRIMARY KEY,
JsCalcResults NVARCHAR(MAX) NOT NULL
);Una vez creada la tabla, podemos insertar registros con datos JSON directamente:
INSERT INTO Operaciones (JsCalcResults) VALUES (N'
{
"_calculator": {
"resultadosTotal": 1000,
"impuestos": 210,
"detalles": {
"base": 790,
"iva": 210
}
}
}');Importante: Es aconsejable incluir siempre la letra
Nantes de la cadena JSON. Esto indica que la cadena es Unicode (NVARCHAR) y evita problemas con caracteres especiales o acentos.
Con esto, ya tenemos un JSON almacenado en la base de datos, listo para ser consultado y manipulado con las funciones nativas que veremos a continuación.
Extraer valores de un JSON con JSON_VALUE y JSON_QUERY
Insertar JSON en una columna NVARCHAR es relativamente simple: básicamente, un JSON es solo una cadena de texto. Pero lo verdaderamente útil es que SQL Server permite consultar y manipular su contenido como si fueran campos de una tabla.
Para ello, se utilizan principalmente dos funciones:
JSON_VALUE()→ extrae valores escalares (texto, números, booleanos).JSON_QUERY()→ extrae objetos o arrays completos.
Ambas funciones utilizan rutas JSON con notación de punto ($.propiedad.subpropiedad) para acceder a los valores deseados dentro del documento.
Extraer valores escalares con JSON_VALUE
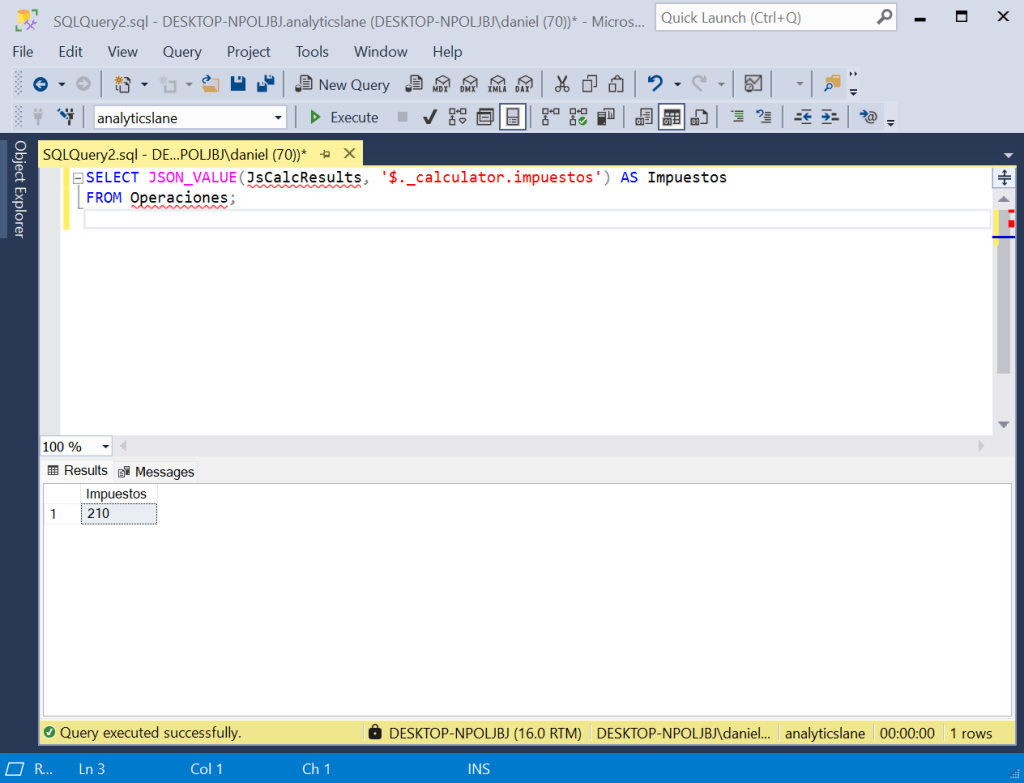
Cuando es necesario acceder a una propiedad cuyo valor sea un número o una cadena de texto, se puede usar la función JSON_VALUE(). Por ejemplo, para acceder a la propiedad _calculator.impuestos del JSON que se ha subido previamente a la base de datos, se puede usar la siguiente consulta:
SELECT JSON_VALUE(JsCalcResults, '$._calculator.impuestos') AS Impuestos FROM Operaciones;
El resultado de esta consulta se puede ver en la siguiente captura de pantalla.
Nota: El uso de la función
JSON_VALUE()sobre un objeto o un array completo produce como resultado un valorNULL. En esos casos se debe usar la funciónJSON_QUERY(), que se mostrará en la siguiente sección.
Extraer objetos con JSON_QUERY
Cuando la propiedad que se quiere obtener es un objeto o un array, la función que se debe utilizar es JSON_QUERY. A diferencia de JSON_VALUE, que devuelve valores escalares, JSON_QUERY devuelve subdocumentos JSON completos. Por ejemplo, en el JSON de ejemplo tenemos un objeto detalles al que se puede acceder mediante una consulta como la siguiente:
SELECT JSON_QUERY(JsCalcResults, '$._calculator.detalles') AS Detalles FROM Operaciones;
El resultado de esta operación se puede ver en la siguiente captura de pantalla.
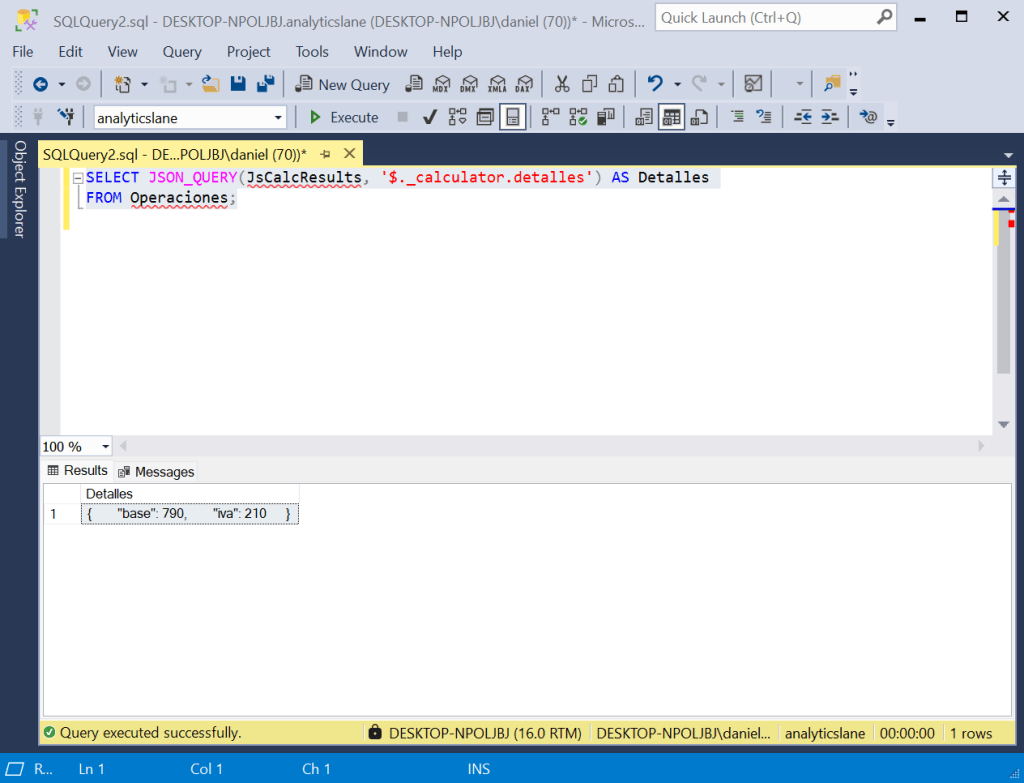
En este caso, el resultado es un fragmento del JSON original con el contenido del objeto detalles.
Esto permite recuperar secciones complejas del documento, mantener su estructura y manipularlas más adelante según sea necesario.
Construir un JSON a partir de propiedades (FOR JSON PATH)
FOR JSON PATH es una de las funcionalidades más potentes de SQL Server para generar documentos JSON directamente desde las consultas. Con ella, se pueden crear estructuras jerárquicas sin necesidad de procesarlas luego en el backend o en la capa de aplicación.
Por ejemplo, se puede construir un objeto JSON a partir de los campos de la tabla con una simple consulta:
SELECT
250 AS impuestos,
360 AS resultadosTotal
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER;El resultado será un documento JSON limpio y bien formado, listo para enviarse a una API o consumirse desde una aplicación cliente.
Filtrar en base a los valores dentro de un JSON
Otra gran ventaja del soporte que ofrece SQL Server para documentos JSON es la posibilidad de filtrar registros según los valores internos del documento. Para ello, se puede usar JSON_VALUE() directamente dentro de las cláusulas WHERE.
Por ejemplo, se puede buscar todas las operaciones con un valor de impuestos superior a 100 mediante una consulta como la siguiente:
SELECT * FROM Operaciones WHERE CAST(JSON_VALUE(JsCalcResults, '$._calculator.impuestos') AS INT) > 100;
El resultado devolverá únicamente aquellas operaciones que cumplan la condición especificada.
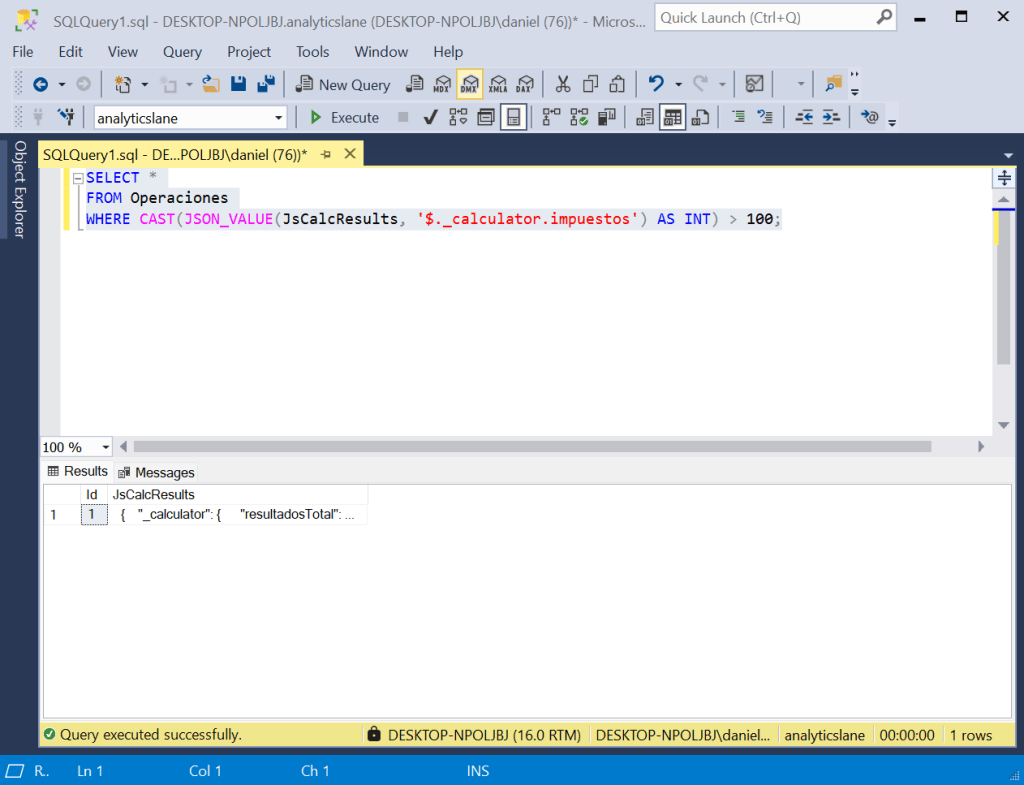
De este modo, SQL Server permite trabajar con datos semiestructurados como si fueran campos normales, facilitando los análisis y búsquedas dentro de columnas JSON sin necesidad de descomponer la información en tablas adicionales.
Modificar valores dentro de un JSON con JSON_MODIFY
Además de leer y filtrar datos dentro de un JSON, también es posible modificarlos directamente desde SQL Server. La función JSON_MODIFY() permite actualizar, agregar o eliminar propiedades sin necesidad de sobrescribir todo el documento.
Por ejemplo, se puede cambiar el valor de una propiedad existente:
UPDATE Operaciones SET JsCalcResults = JSON_MODIFY(JsCalcResults, '$._calculator.impuestos', 300) WHERE Id = 1;
Y también agregar nuevas propiedades en caso de que no existan:
UPDATE Operaciones SET JsCalcResults = JSON_MODIFY(JsCalcResults, '$._calculator.descuento', 50) WHERE Id = 1;
De esta forma, se puede editar el contenido JSON directamente en la base de datos, sin necesidad de extraerlo al código de la aplicación, modificarlo y volver a guardarlo. Esto hace que las actualizaciones de campos sean más simples, rápidas y eficientes.
Conclusiones
En esta entrada hemos visto que trabajar con JSON en SQL Server es más fácil y potente de lo que muchos imaginan. Lejos de ser un formato exclusivo del frontend o del backend, SQL Server ofrece soporte nativo completo para almacenar, consultar y modificar datos JSON de forma directa.
Con funciones como:
JSON_VALUE()yJSON_QUERY()→ para leer propiedades internas y objetos.FOR JSON PATH→ para generar respuestas JSON limpias desde tus consultas.JSON_MODIFY()→ para actualizar valores sin reconstruir todo el documento.
Así se pueden integrar datos semiestructurados dentro de los flujos SQL de una manera sencilla. Esto no sustituye un buen diseño relacional, pero sí ofrece la flexibilidad necesaria para manejar información dinámica o variable de forma elegante y eficiente.
Nota: La imagen de este artículo fue generada utilizando un modelo de inteligencia artificial.
Deja una respuesta