
Las reglas de asociación permiten encontrar patrones comunes en los elementos de grandes conjuntos de datos. Una de las principales aplicaciones de esta técnica es el análisis de la cesta de la compra (market-basket analysis). Mediante el cual se pude identificar los productos que se compra de forma conjunta en una tienda.
Uno de los ejemplos más citado sobre los resultados de los análisis de la cesta de la compra es caso “cerveza y pañales”. La historia es que una gran cadena observo que los clientes que compraban cerveza y pañales al mismo tiempo. Posiblemente no sea más que una leyenda urbana de la ciencia de datos. Sin embargo es uno de los ejemplos más reconocidos de los resultados que se pueden obtener con este tipo de análisis.
Tabla de contenidos
Introducción a las reglas de asociación
Las reglas de asociación generalmente se escriben de la forma:
\{Antecedente\} \implies \{Consecuente\}Esto indica que existe una relación entre los clientes que compran el antecedente y el consecuente en la misma transacción. La fuerza y el sentido de la relación se mide con diferentes indicadores: el soporte, la confianza y la mejora de la confianza.
Soporte
El soporte es la frecuencia relativa con la que se observa la regla. Es decir, un soporte de 0.15 indica que el antecedente y el consecuente se observan a la vez en el 15% de las transacciones. Este indicado mide la fuerza de la regla. Al ser un porcentaje, los posibles valores del soporte se encuentran entre 0 y 1.

Confianza
La confianza es el porcentaje de las transacciones en las que aparece el antecedente en la que también aparece el consecuente. Lo que mide este indicador es la fiabilidad de la regla. Matemáticamente se puede obtener utilizando la expresión
conf(\{Antecedente\} \implies \{Consecuente\}) = \frac{conf(\{Antecedente, Consecuente\})}{conf(\{Antecedente\})}En donde conf(\{Antecedente\} \implies \{Consecuente\}) es la confianza de los registros en los que aparece a la vez el antecedente y consecuente. En un ejemplo en el que se tenga 100 registros con el antecedente, 200 con el consecuente y 80 con ambos se obtiene una confianza de 0,8 para la regla \{Antecedente\} \implies \{Consecuente\}. Por otro lado, la regla \{Consecuente\} \implies \{Antecedente\} tiene el mismo soporte, pero una confianza de 0,4. Lo que indica que la primera regla tiene más fuerza que la segunda. Siendo el antecedente el que induce la aparición del consecuente y no al revés. Al igual que el soporte, el valor de la confianza solamente puede tener valores entre 0 y 1.
Mejora de la confianza
Finalmente, la mejora de la confianza es la fracción de soporte de la regla respecto al que se observaría en caso de independía. Matemáticamente se puede obtener utilizando la expresión
conf(\{Antecedente\} \implies \{Consecuente\}) = \frac{conf(\{Antecedente, Consecuente\})}{conf(\{Antecedente\}) \times conf(\{Consecuente\})}Valores cercanos a 1 indica que la regla no se puede diferenciar del azar. A medida que aumenta el valor la regla es más interesante ya que no se puede justificar únicamente por el azar.
Implementación en Python: MLxtend
A la hora de implementar un algoritmo de aprendizaje automático en Python generalmente la primera idea suele ser buscarlo en scikit-learn. Desgraciadamente la librería no contiene este tipo de algoritmos. Afortunadamente, la biblioteca MLxtend de Sebastian Raschka tiene una implementación del algoritmo Apriori para obtener reglas de asociación a partir de los datos. Para poder utilizarlo simplemente se ha de instalar la libraría empleando pip:
pip install mlxtend
Importación de los datos
Para trabajar se puede importa datos desde el repositorio de datos para aprendizaje automático de la Universidad de California, Irvine. El conjunto de datos se encuentra en formato de Microsoft Excel, por lo que se puede cargar utilizando las funciones de pandas para archivos xls.
import pandas as pd
df = pd.read_excel('http://archive.ics.uci.edu/ml/machine-learning-databases/00352/Online%20Retail.xlsx')
df.head()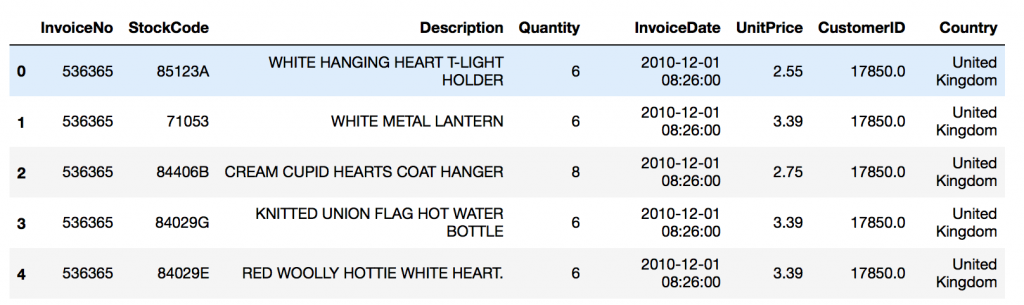
El conjunto de datos no se puede utilizar tal como esta. Por ejemplo, las descripciones contienen espacios que ha de ser eliminados. Las filas que no tienen número de facturas no se pueden utilizar ya que no se identifica la transacción.
df['Description'] = df['Description'].str.strip()
df.dropna(axis=0, subset=['InvoiceNo'], inplace=True)
df['InvoiceNo'] = df['InvoiceNo'].astype('str')Para acelerar los cálculos se van a utilizar únicamente los datos correspondientes a España. La implementación del método apriori requiere que los datos se encuentren en un dataframe. Cada una de las filas representa una factura y cada una de las columnas un producto. Esto se puede conseguir utilizando el siguiente código:
basket = (df[df['Country']=="Spain"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))
basket.drop('POSTAGE', inplace=True, axis=1)Puede observase que se ha eliminado la columna ` POSTAGE` ya que prácticamente es un ítem que aparece en todas las facturas.
Obtención de la reglas de asociación
Ahora se pude utilizar la función `apriori` para obtener los productos con un mínimo de soporte.
from mlxtend.frequent_patterns import apriori frequent_itemsets = apriori(basket > 0, min_support=0.06, use_colnames=True) frequent_itemsets.head()
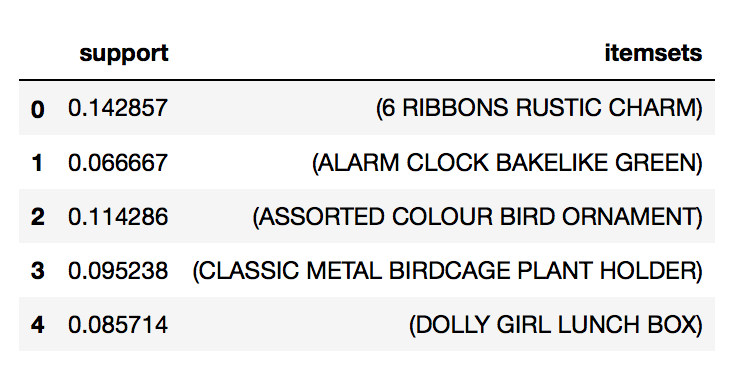
A continuación, se pueden obtener las reglas que superen además un mínimo de confianza:
from mlxtend.frequent_patterns import association_rules rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.8) rules.head()

O un mínimo de soporte:
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1) rules.head()

Interpretación de los resultados
Los resultados que se han obtenido dicen cosas interesantes. Analizando la primera regla se puede observar que los clientes que han comprado "6 RIBBONS RUSTIC CHARM" también aparece "ASSORTED COLOUR BIRD ORNAMENT" con un soporte de 0,085 y una confianza de 0,6. Esto indica que en el 8,5% de las transacciones contienen ambas referencias. Además, la confianza indica que en el 60% de los casos que se compra "6 RIBBONS RUSTIC CHARM" también aparece "ASSORTED COLOUR BIRD ORNAMENT". La mejora de la confianza de 5,25 indica que cuando aparece “6 RIBBONS RUSTIC CHARM” aparece la otra referencia cinco veces más de lo que se podría esperar por azar.
Conclusiones
En esta entrada se han vistos los fundamente de las reglas de asociación. Estas se han utilizado para realizar un análisis de la cesta de la compra (market-basket analysis). Finalmente se han interpretado los resultados obtenidos, descubriendo lo que estos quieren decir.
Imágenes: Pixabay
Muy interesante!
Soy nueva en eso y tengo una pregunta ¿Que significa basket > ?
El termino “market-basket analysis” es análisis de la cesta de la compra.