
El MSCI World Index suele presentarse como “la ventana al mundo” para quienes invierten en bolsa. Es uno de los índices más seguidos por inversores y gestores de fondos porque, en teoría, ofrece una exposición global a los mercados desarrollados. Reúne en torno a 1500 empresas de gran y mediana capitalización repartidas en 23 países, desde Estados Unidos hasta Europa y Japón.
A primera vista, esto suena a diversificación garantizada. Sin embargo, cuando miramos más de cerca, descubrimos algo llamativo: NVIDIA representa ya alrededor del 4% del índice, y justo detrás vienen gigantes como Microsoft y Apple. Entonces surge la duda: ¿de verdad el MSCI World está tan diversificado como parece o, en realidad, son unas pocas compañías las que marcan el rumbo?
Para investigar este tema, vamos a echar mano de herramientas que normalmente se usan para estudiar la desigualdad económica, como la curva de Lorenz y el coeficiente de Gini. También exploramos gráficos logarítmicos (rank-size plots) y veremos qué nos cuenta un ajuste a la ley de potencias.
Los datos los hemos tomado de la web oficial de MSCI, donde se publica regularmente la composición del índice y el peso de cada empresa. Y ahí está la clave: no todas las compañías influyen igual. Cuanto mayor es su capitalización bursátil, mayor es su peso, y eso significa que las subidas y bajadas de estas pocas afectan mucho más al rendimiento total del índice.

Primer vistazo a los datos
Lo primero es cargar la información del índice desde el Excel que descargamos previamente y echar un vistazo a las primeras filas:
import pandas as pd
# Importación de los datos
msci = pd.read_excel("MSCI.xlsx")
# Revisión de los primeros registros
msci.head(10).style.format({"Closing Weight": "{:.2%}"})Security Name Closing Weight
0 NVIDIA 4.62%
1 MICROSOFT CORP 4.49%
2 APPLE 4.17%
3 AMAZON,COM 2.72%
4 META PLATFORMS A 2.02%
5 BROADCOM 1.53%
6 TESLA 1.37%
7 ALPHABET A 1.36%
8 ALPHABET C 1.16%
9 JPMORGAN CHASE & CO 1.02%
Al explorar los primeros registros aparecen nombres que resultan familiares para cualquiera que siga los mercados: NVIDIA, Microsoft, Apple, Amazon y Meta. Solo estas cinco compañías suman cerca del 18% del peso total del índice, lo cual es una proporción muy llamativa para un conjunto que incluye en torno a 1400 empresas.
El dato se vuelve aún más revelador si afinamos un poco más: NVIDIA, Microsoft y Apple, las tres primeras, concentran en torno al 13%, mientras que las 10 primeras superan el 24,4%. Es decir, menos del 1% de las empresas (en número) explica casi una cuarta parte del índice (en peso).
Esto ya deja entrever una clara concentración en el sector tecnológico estadounidense. Sin embargo, para entender hasta qué punto unas pocas compañías dominan el comportamiento del MSCI World, necesitamos herramientas más formales que nos permitan medir y visualizar la desigualdad.
Curva de Lorenz: desigualdad en los pesos
La curva de Lorenz es una herramienta clásica en economía para medir la desigualdad en la distribución de ingresos. Aquí la usaremos con el mismo propósito, pero aplicada a los pesos de las empresas dentro del MSCI World.
La idea es sencilla: en el eje horizontal representamos la fracción acumulada de empresas (ordenadas de menor a mayor peso) y en el eje vertical, la fracción acumulada del peso total del índice. Lo que se puede hacer con el siguiente código Python:
import numpy as np
import matplotlib.pyplot as plt
# Ordena los pesos de menor a mayor
weights = msci["Closing Weight"].sort_values(ascending=True).values
n = len(weights)
# Cálculo acumulado y normalización
cum_weights = np.cumsum(weights) / weights.sum()
cum_pop = np.arange(1, n+1) / n
# Graficar Lorenz
plt.figure(figsize=(7,5))
plt.plot(cum_pop, cum_weights, label="Curva de Lorenz", color="blue")
plt.plot([0,1], [0,1], "--", color="grey", label="Igualdad perfecta")
plt.xlabel("Fracción de empresas")
plt.ylabel("Fracción del peso total")
plt.title("Curva de Lorenz de los pesos del MSCI World")
plt.legend()
plt.grid(True)
plt.show()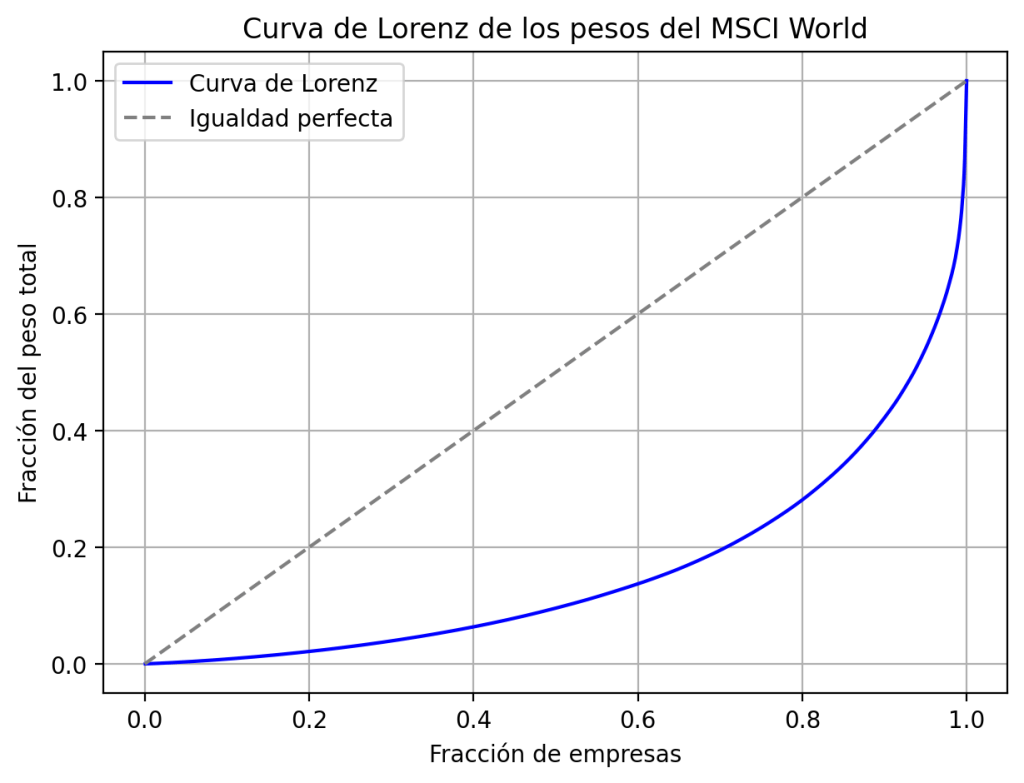
En un escenario de igualdad perfecta, todas las empresas tendrían el mismo peso y la curva coincidiría con la diagonal gris. Pero lo que observamos está muy lejos de eso: la curva real se sitúa claramente por debajo de la diagonal, lo que refleja que unas pocas compañías concentran gran parte del índice, mientras que la mayoría apenas tiene impacto.
El gráfico se puede interpretar fácilmente con ejemplos concretos:
- Cuando llevamos acumulado el 60% de las empresas (punto 0,6 en el eje X), estas apenas suman en torno al 20% del peso total (punto 0,2 en el eje Y).
- En el extremo opuesto, el último tramo del eje X muestra cómo unas pocas compañías concentran por sí solas el 20% final del índice.
En otras palabras, el MSCI World está compuesta por un gran número de empresas, pero su influencia real está muy concentrada en unas pocas gigantes bursátiles.
Coeficiente de Gini: cuantificando la desigualdad
La curva de Lorenz nos da una representación visual muy clara de la concentración, pero a veces conviene resumir todo ese patrón en un solo número. Ese número es el coeficiente de Gini, un indicador clásico de desigualdad.
Su escala puede estar entre 0 a 1 y su interpretación es realmente sencilla:
- 0 → igualdad perfecta (todas las empresas pesan lo mismo).
- 1 → desigualdad extrema (una sola empresa concentraría el 100%).
El coeficiente de Gini se puede calcular con el siguiente código:
# Calcular coeficiente de Gini
Gini = 1 - 2*np.trapz(cum_weights, cum_pop)
print(f"Coeficiente de Gini: {Gini:.3f}")Coeficiente de Gini: 0.679
En el caso del MSCI World, el resultado del índice Gini es 0,679.
¿Es mucho o poco? Para ponerlo en contexto: en economía, cuando el Gini de un país supera 0,5 en distribución de ingresos ya se habla de una sociedad con alta desigualdad. Trasladado al mundo bursátil, un valor de 0,679 indica que el índice está fuertemente concentrado en pocas compañías, mientras que la mayoría de las empresas tienen un peso casi simbólico.
En otras palabras, aunque el MSCI World se presente como un índice “global y diversificado”, la realidad es que su comportamiento está dominado por un puñado de gigantes tecnológicos y financieros.
Rank-size plot: distribución en escala logarítmica
Otra forma interesante de analizar la concentración es mediante un rank-size plot. La idea es ordenar las empresas de mayor a menor según su peso en el índice y luego graficarlas en escala logarítmica doble:
- En el eje X se coloca el rango (1 para la empresa más grande, 2 para la segunda, etc.).
- En el eje Y se representa el peso de cada empresa.
Este tipo de gráficos es muy común en el estudio de fenómenos donde unos pocos elementos dominan sobre el resto: por ejemplo, el tamaño de las ciudades, la distribución de la riqueza o incluso la frecuencia de palabras en un texto.
Para crear un gráfico tipo rank-size plot para el MSCI World se puede usar el siguiente código Python:
# Rank (1 = mayor peso)
ranks = np.arange(1, n+1)
weights_desc = msci["Closing Weight"].sort_values(ascending=False).values
plt.figure(figsize=(7,5))
plt.plot(ranks, weights_desc, marker="o", linestyle="none")
plt.xscale("log")
plt.yscale("log")
plt.xlabel("Ranking de la empresa")
plt.ylabel("Peso en el MSCI World")
plt.title("Rank-size plot (escala log-log)")
plt.grid(True, which="both", ls="--", alpha=0.5)
plt.show()En el caso del MSCI World, la curva muestra una caída muy pronunciada: las empresas del top 10 tienen un peso desproporcionado si se las compara con los cientos de compañías que ocupan la cola de la distribución.
Este patrón nos lleva a una pregunta natural: ¿siguen los pesos de las empresas del MSCI World una ley de potencias, como ocurre en muchos sistemas complejos? Un análisis similar ya lo realizamos al revisar las visitas al blog en 2019 y 2021, para analizar los patrones de interés de los lectores.
¿Sigue una ley de potencias?
En muchos fenómenos económicos y sociales, la desigualdad no es aleatoria: sigue un patrón conocido como ley de potencias. Esto significa que la probabilidad de encontrar un elemento muy grande (una empresa, una ciudad, una fortuna…) decrece según una fórmula matemática concreta. Dicho de otra forma: unos pocos gigantes dominan, mientras que la mayoría se queda en tamaños mucho más pequeños.
Veamos si los pesos de las empresas en el MSCI World se ajustan a este tipo de distribución:
import powerlaw
# Ajuste a la distribución de ley de potencias
fit = powerlaw.Fit(weights_desc, discrete=False)
print(f"Alpha estimado: {fit.alpha:.2f}")
print(f"Peso mínimo para ajustar: {fit.xmin:.6f}")
# Comparación con lognormal u otras distribuciones
R, p = fit.distribution_compare("power_law", "lognormal")
print(f"Comparación Power Law vs Lognormal: R={R:.2f}, p={p:.3f}")
# Visualización
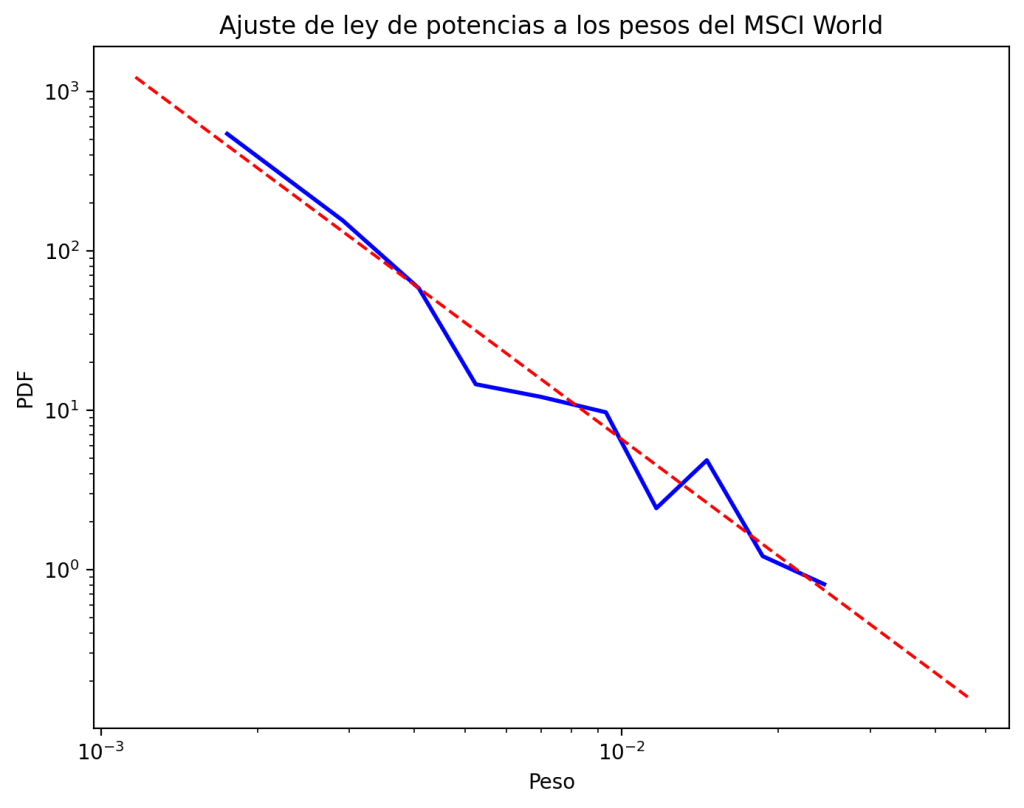
plt.figure(figsize=(8,6))
fit.plot_pdf(color="b", linewidth=2)
fit.power_law.plot_pdf(color="r", linestyle="--")
plt.xlabel("Peso")
plt.ylabel("PDF")
plt.title("Ajuste de ley de potencias a los pesos del MSCI World")
plt.show()Calculating best minimal value for power law fit
Alpha estimado: 2.44
Peso mínimo para ajustar: 0.001165
Comparación Power Law vs Lognormal: R=-0.87, p=0.024
Al aplicar este análisis obtenemos:
- Un exponente α ≈ 2,44, lo que indica que la caída de los pesos no es tan abrupta como podría pensarse: hay concentración, pero no llega a ser extrema.
- El punto mínimo de ajuste (xmin ≈ 0,0012) muestra que es sobre todo en la cola de la distribución donde este patrón encaja mejor. Esto significa que solo 177 de las ~1400 empresas cumplen la ley de la potencia.
- Al comparar con otras alternativas, como la lognormal, la evidencia estadística indica que la ley de potencias no describe mejor los datos. Esto se refleja en que R es negativo y el p-value es menor a 0,05, lo que se considera estadísticamente significativo.
En base a estos resultados conviene ser cautos:
- No toda la distribución sigue perfectamente este comportamiento.
- Los valores extremos pueden generar problemas numéricos y sesgar las estimaciones.
En resumen, aunque el MSCI World no es un caso “puro” de ley de potencias, sus pesos muestran un patrón característico de sistemas complejos: unas pocas empresas muy grandes concentran la mayor parte de la influencia del índice.
Conclusiones
El análisis del MSCI World mediante la curva de Lorenz, el coeficiente de Gini, los rank-size plots y el ajuste a ley de potencias confirma varias ideas importantes:
- Diversificación aparente: Aunque el índice incluye unas 1.400 empresas, no todas tienen el mismo peso. En la práctica, invertir en el MSCI World significa estar muy expuesto a un puñado de compañías estadounidenses de gran capitalización.
- Riesgo de concentración: Si una de las empresas del top 5 sufre una caída significativa, el índice global se ve afectado de manera desproporcionada. Es decir, unas pocas compañías, especialmente del sector tecnológico, dominan el comportamiento del índice.
- Desigualdad estructural: La distribución de pesos sigue patrones matemáticos similares a los que se observan en otros sistemas complejos. Esto explica por qué unas pocas empresas concentran la mayor parte de la influencia en el índice.
Para los inversores, esto es un recordatorio clave: aunque un índice pueda parecer muy diversificado por el número de empresas que lo componen, lo realmente determinante es cómo están distribuidos esos pesos.
Nota: La imagen de este artículo fue generada utilizando un modelo de inteligencia artificial.
Deja una respuesta