
El Análisis de Componentes Principales (PCA) es una técnica ampliamente utilizado en aprendizaje automático. Se utiliza para reducir la dimensionalidad (el número de variables o columnas) de los conjuntos de datos manteniendo al mismo tiempo la mayor cantidad de información posible. PCA transforma las variables originales en otras nuevas, llamadas componentes principales, … [Leer más...] acerca de Introducción al Análisis de Componentes Principales (PCA)
Scikit-Learn
Desmitificando Elliptic Envelope: Una exploración de la detección de anomalías con estimación de covarianza elíptica

Entre los algoritmos de Machine Learning para la detección de anomalías Elliptic Envelope destaca por su capacidad para modelar la distribución de los datos utilizando una elipse en el espacio de características. Un enfoque efectivo para identificar anomalías en conjuntos de datos multivariados donde la mayoría de los datos se distribuyen de manera normal. Lo que lo convierte … [Leer más...] acerca de Desmitificando Elliptic Envelope: Una exploración de la detección de anomalías con estimación de covarianza elíptica
Explorando Local Outlier Factor (LOF): Un enfoque eficaz para la detección de anomalías

Los modelos de detección de anomalías es una parte del aprendizaje automático en la que cada vez existe un mayor interés. Siendo una tarea crítica en diferentes áreas como la seguridad informática, el mantenimiento predictivo o el monitoreo de la salud. Uno de los algoritmos más populares para esta tarea es Local Outlier Factor (LOF). Este algoritmo identifica las anomalías de … [Leer más...] acerca de Explorando Local Outlier Factor (LOF): Un enfoque eficaz para la detección de anomalías
One-Class SVM: Detección de anomalías con máquinas de vector soporte
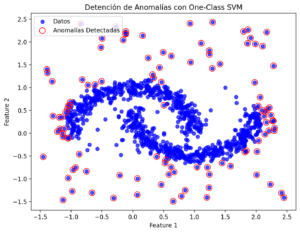
La detección de anomalías es una de las aplicaciones del aprendizaje no supervisado más utilizadas. Siendo una técnica que se emplea en casos tan diferentes como la detección de ataques cibernéticos, la detección de problemas de salud o la identificación de aplicaciones fraudulentas en servicios financieros o seguros. En todos los casos, identificar anomalías requiere localizar … [Leer más...] acerca de One-Class SVM: Detección de anomalías con máquinas de vector soporte
Isolation Forest: Detectando Anomalías con Eficacia

La detección de anomalías es uno de los desafíos más intrigantes del aprendizaje automático. Ya sea en el campo de la seguridad informática, la detección de fraudes financieros o en tareas de mantenimiento predictivo, identificar valores anómalos dentro de grandes conjuntos de datos es clave para evitar problemas en las operaciones. En esta entrada se explicará el algoritmo de … [Leer más...] acerca de Isolation Forest: Detectando Anomalías con Eficacia
Selección del valor óptimo de K en SelecKBest de scikit-learn

Para poder entrenar un modelo de aprendizaje automático de forma correcta es necesario seleccionar las características. Un proceso clave para mejorar el rendimiento de los modelos. En Python, uno de los posibles métodos para ello es SelectKBest (o su equivalente SelectPercentile). Una de las herramientas de selección de características que se encuentran disponibles en … [Leer más...] acerca de Selección del valor óptimo de K en SelecKBest de scikit-learn
Diferencias entre fit(), predict() y fit_predict() en Scikit-learn

Scikit-learn (muchas veces reverenciada como sklearn) es posiblemente la librería de Aprendizaje Automático más popular actualmente en Python. Lo que se debe a la cantidad de modelos que implementa y su sencillez. En la mayoría de los objetos de esta librería se encuentran implementados los métodos fit(), predict() y fit_predict() usados para entrenar y realizar predicciones … [Leer más...] acerca de Diferencias entre fit(), predict() y fit_predict() en Scikit-learn
Modelos de aprendizaje automático con ChatGPT en español

Hace unas semanas publiqué una entrada en la que evalúe las posibilidades que tiene ChatGPT para la creación de modelos de aprendizaje automático. Comprobando que es una herramienta que puede servir de ayuda para aquellos que comienzan. En aquella ocasión trabajé con la herramienta en inglés, debido a que este es el idioma en el que suelen entrenarse los modelos y, por lo … [Leer más...] acerca de Modelos de aprendizaje automático con ChatGPT en español
Eliminar características colineales con la matriz de correlación

En aprendizaje automático el uso de características colineales para el entrenamiento es un problema que puede afectar a la calidad de los modelos, especialmente en los lineales. Por lo que es necesario identificarlas y eliminarlas. Una de las razones para hacer esto es usar la matriz de correlación dado que la multicolinealidad se produce cuando dos o más características están … [Leer más...] acerca de Eliminar características colineales con la matriz de correlación
Interpretación de las predicciones de los árboles de regresión y Random Forest

Una de las ventajas de usar árboles de regresión es su interpretabilidad. Cuando se crea un modelo a partir de un árbol de regresión no solamente se puede obtener una predicción para cada uno de los registros, sino que también es posible saber cuánto afecta cada una de las características usadas al resultado final. Aunque esto no se puede hacer directamente en Scikit-learn. … [Leer más...] acerca de Interpretación de las predicciones de los árboles de regresión y Random Forest
Implementar modelos de aprendizaje automático con ChatGPT
ChatGPT es un modelo de lenguaje desarrollado por OpenAI que puede producir respuestas a las cuestiones que se le plantean de forma similar a como lo haría un humano. Con capacidad de comprender el contexto de las preguntas y seguir una conversación. Por lo que es capaz ampliar o corregir las respuestas generadas anteriormente dentro de una conversación en base a las cuestiones … [Leer más...] acerca de Implementar modelos de aprendizaje automático con ChatGPT
Configurar el API de Scikit-learn para generar DataFrames

La nueva versión 1.3 de Scikit-learn trae importantes novedades. Una de ellas es la posibilidad de configurar el API de las herramientas de transformación de datos o transformers. Hasta ahora en Scikit-learn al utilizar un transformer el resultado que se obtiene es un ndarray de NumPy. A partir de la versión 1.3, es posible configurar el tipo de objeto resultante mediante el … [Leer más...] acerca de Configurar el API de Scikit-learn para generar DataFrames