
La distribución de las librerías en un entrono de trabajo son clave para el éxito. Disponer de la última versión de estas es imprescindible para poder realizar el trabajo de forma efectiva y evitar los errores ya conocidos. En R la forma más popular de instalar paquetes en los entornos de trabajo es a través del CRAN. El CRAN es abierto y esto puede no ser adecuado en un entrono corporativo. En estos se puede desarrollar paquetes de uso interno que no se desean compartir fuera, pero si internamente. Para esto se puede crear un CRAN corporativo al que solamente pueden acceder los miembros del equipo.
Una alternativa para la distribución interna de código es mediante la utilización de repositorios Git privados. Instalar un paquete que se encuentra en un repositorio es algo que se puede realizar de una manera casi tan fácil como desde el CRAN. Aunque presenta algunas desventajas como no actualizar de forma automática el listado de paquetes dependientes. Además, la utilización del CRAN es una forma más natural e intuitiva para la mayoría de los usuarios.
Creación de un CRAN corporativo
La creación de la estructura de un CRAN se puede realizar con el paquete miniCRAN (https://cran.r-project.org/web/packages/miniCRAN/index.html). Este paquete permite descargar un listado de paquetes y las dependencias de estos guardando los mismos es una estructura de carpetas adecuadas. Por ejemplo, para descargar el paquete foreach y todas sus dependencias se pude utilizar:

library('miniCRAN')
# Obtención del listado de paquetes
pkg <- c('foreach')
pkg_list <- pkgDep(pkg)
# Descarga de los paquetes
pth <-'miniCRAN'
makeRepo(pkg_list, path = pth, type = 'source')
makeRepo(pkg_list, path = pth, type = 'mac.binary')
makeRepo(pkg_list, path = pth, type = 'win.binary')Inicialmente se carga el paquete miniCRAN y se crea el listado de paquetes utilizando la función pkgDep. Posteriormente se descargan los paquetes en los formatos disponibles: código, binarios para Mac y binarios para Windows. Obviamente, en caso de que no se trabaje con alguna de las plataformas podemos omitir los binarios correspondientes. Estos se almacenarán es la carpeta miniCRAN. La estructura para Windows se puede ver en la siguiente captura de pantalla:
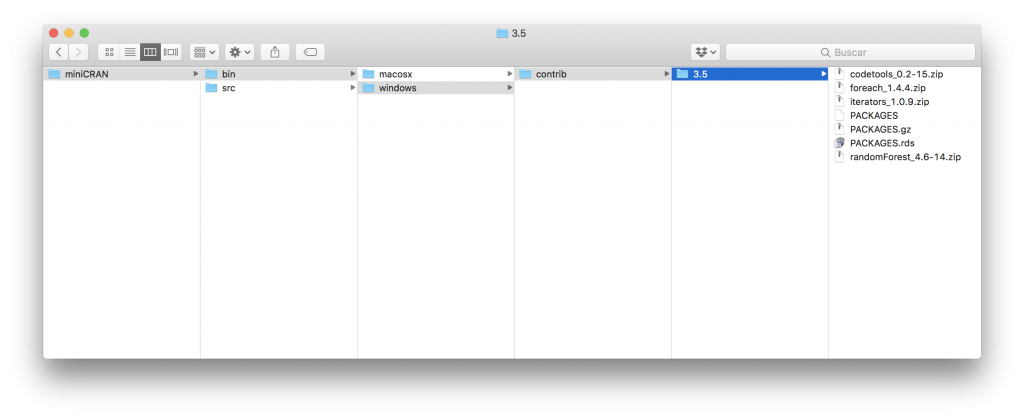
En esta captura se pude observa que en la capeta existen diferentes archivos zip (en la carpeta src los archivos son tar.gz), uno para cada paquete y tres archivos PACKAGES en los que se encuentra el listado de paquetes disponibles.
Ahora esos esta carpeta se puede publicar en un servidor ftp (o http) dentro de la intranet para acceder a los mismo indicando a R que instale desde el repositorio privado
install.packages('foreach', repos = 'http://miniCRAN')donde http://miniCRAN es la URL en la que se sitúa el CRAN.
Paquetes propios
La forma de añadir paquetes nuevos al repositorio es incluyendo los mismos en las carpetas src y bin. Una vez realizado estos se han de actualizar los archivos PACKAGES para que se puedan encontrar los nuevos paquetes, para lo que se puede utilizar el comando write_PACKAGES del paquete tools.
write_PACKAGES(pth)
Conclusiones
CRAN es el método más habitual y conocido para la distribución de paquetes en R. Poder replicar el funcionamiento de este con un CRAN corporativo para la distribución del código empleado internamente puede facilitar la vida a nuestros compañeros.
Imágenes: Pixabay (skeeze)
Deja una respuesta