
En una entrada reciente se explicó los fundamentos de la prueba de independencia de Chi-cuadrado, una prueba que se puede encontrar fácilmente en R o Python. Pero en Excel es necesario implementarla. Hoy se explicará cómo se puede implementar la prueba de independencia de Chi-cuadrado con Excel.
Planteamiento del problema
Un grupo de investigadores desean comprobar si existe diferencia entre la aplicación de un tratamiento y un placebo. Para ello suministran a un grupo de pacientes el tratamiento y a otro de control placebo, obteniendo los resultados de la siguiente captura de pantalla del libro Excel.
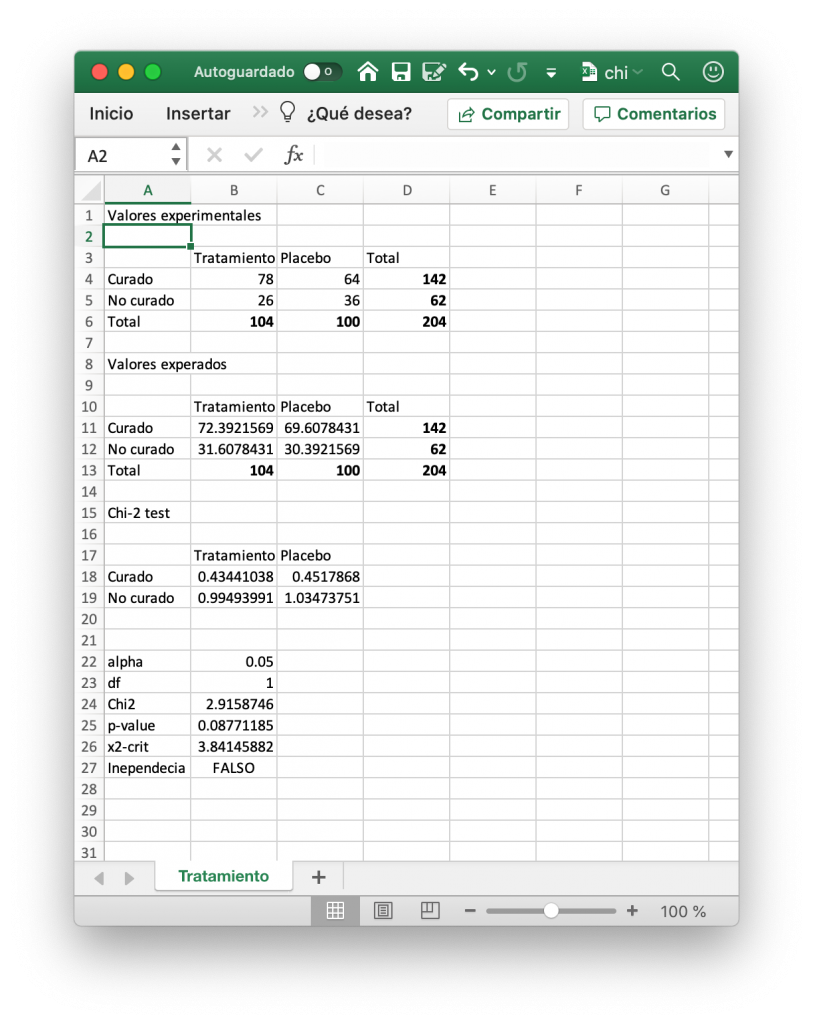
Ahora queremos comprobar si existe relación entre haberse curado y haber tomado el tratamiento o no. Para lo que se define la siguiente hipótesis nula: “No existe diferencia entre aplicar la terapia y el placebo.”
Implementación de la prueba de independencia de Chi-cuadrado con Excel
Ahora se puede cargar la tabla de contingencia en una hoja de cálculo Excel e intentar descartar esta hipótesis mediante la prueba de independencia de Chi-cuadrado.
Valores esperados
Para ello en primer es necesario calcular cual es la frecuencia esperada para cada de los casos asumiendo que fuese verdadera la hipótesis nula. Es decir, que el tratamiento no fuese mejor que el placebo. Lo que se hace multiplicando, como se explicó en la entrada anterior, el total de pacientes de un grupo por el total de cada uno de los resultados y dividido por el número total de pacientes en los dos grupos.

A modo de ejemplo se puede ver que el valor esperado para los pacientes curados con tratamiento es el total de pacientes con tratamiento (104) por el número de pacientes totales curados (142) y dividido por el número total de pacientes (204). Lo que da un valor esperado de 72,39 pacientes curados con tratamiento.
En este punto es importante recordar que para poder aplicar la Prueba de independencia de Chi-cuadrado es necesario que todos los valores esperados sean mayor que 5.
Diferencias al cuadrado
El segundo paso es obtener la diferencia al cuadrado del número de casos respecto al esperado dividido por el esperado. Por ejemplo, en el caso de pacientes curados con tratamiento tememos 78 casos y lo esperado seria 72,39, lo que nos da un valor de 0,43.
Los valores para todos los casos se suman para obtener el valor de la distribución de Chi-cuadrado. En el ejemplo es 2,91, lo que se muestra en la celda B24 del ejemplo.
Evaluación de los resultados
Ahora se puede comprobar si se puede rechazar la hipótesis nula de dos maneras. En la primera se puede obtener el punto de corte que nos indica la distribución inversa de Chi-cuadrado con el grado de significancia (generalmente 0,05) y los grados de libertad del experimento. Comprobando si el valor obtenido es mayor que el del punto de corte. Es importante recordar que los grados de libertad es el producto del número de tratamientos (2) menos uno por el número de posibles resultados (2) menos uno. Por lo que, en este caso, los grados de libertad son 1. Esto se puede hacer con obtener con la siguiente celda de Excel (B26 en el ejemplo).
=INV.CHICUAD(1-0,05; 1)
Lo que nos da un valor de 3,8 que es mayor de 2,91, por lo que no se puede rechazar la hipótesis nula.
Otra alternativa es obtener el p-valor y comprobar si este es menor que el grado de significancia. Algo que se puede obtener con la distribución de Chi-cuadrado. En la hoja de cálculo de ejemplo (celda B25):
=1-DISTR.CHICUAD(B24;B23;VERDADERO)
Lo que nos da 0,09. Al igual que antes indica que no se puede rechazar la hipótesis nula en este experimento. Esto es, no existe diferencia entre en tratamiento y el placebo.
Conclusiones
En esta entrada se ha visto cómo aplicar la prueba de independencia de Chi-cuadrado con Excel. Algo que no es excesivamente complicado.
Hola Daniel,
Muchas gracias por tu detallada explicación. Me ha ayudado a refrescar algunos conceptos que necesito usar.
Hacía años que no miraba nada de estadísitica, lo que estudié en la universidad hace 10 años, pero gracias a este post he podido hacer un contraste que nos irá muy bien en el trabajo.