
El análisis de componentes principales (PCA, por sus siglas en inglés) es una técnica ampliamente utilizada para reducir la dimensionalidad en conjuntos de datos. Una de las decisiones clave al aplicar PCA es determinar el número de componentes que se deben seleccionar, logrando un equilibrio entre capturar la mayor cantidad de información posible y evitar redundancias innecesarias. En esta entrada, explicaremos cómo determinar el número de componentes en PCA utilizando la varianza explicada acumulada, ilustrando el método con un caso práctico y compartiendo una función que automatiza este proceso.
Tabla de contenidos
¿Qué es la varianza explicada acumulada?
En PCA, cada componente principal representa una dirección de máxima varianza en los datos. La varianza explicada por un componente mide cuánta información (o dispersión) de los datos originales captura.
La varianza explicada acumulada es la suma de las varianzas explicadas por los componentes seleccionados hasta cierto punto, expresada como un porcentaje del total. Este valor permite determinar qué proporción de la información total del conjunto de datos se conserva al incluir un número específico de componentes.
Pasos para determinar el número de componentes en PCA
Para estimar el número óptimo de componentes en PCA usando la varianza explicada acumulada, se deben seguir los siguientes pasos:
- Calcular los componentes principales y las varianzas explicadas: Aplicar PCA para calcular cuánta varianza explica cada componente.
- Sumar las varianzas explicadas: Calcular la varianza explicada acumulada para determinar qué porcentaje de información total se conserva al incluir varios componentes.
- Definir un umbral deseado: Elegir un porcentaje de retención de información, como el 90%, el 95% o el 99%, según los requerimientos del problema. En aplicaciones críticas, puede ser preferible un umbral más alto para conservar más información.
- Seleccionar el número de componentes: Identificar el menor número de componentes necesarios para superar el umbral deseado.
Ejemplo práctico: Conjunto de datos de diabetes
Para ilustrar este método, utilizaremos el conjunto de datos Diabetes. Este conjunto de datos, disponible en la biblioteca sklearn, incluye 442 observaciones de pacientes con diabetes y 10 variables numéricas que describen diferentes factores relacionados con la salud, como la presión arterial o los niveles de glucosa. El objetivo es reducir la dimensionalidad de este conjunto de datos, conservando la mayor cantidad de información posible.

Paso 1: Carga y preprocesamiento de los datos
Para este ejemplo, cargamos los datos y los normalizamos antes de realizar el análisis de PCA.
import numpy as np import pandas as pd from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler from sklearn.datasets import load_diabetes # Cargar el conjunto de datos de diabetes data = load_diabetes() X = data.data df = pd.DataFrame(X, columns=data.feature_names) # Normalizar los datos scaler = StandardScaler() X_scaled = scaler.fit_transform(df)
Paso 2: Aplicar PCA y calcular la varianza explicada acumulada
Tras normalizar los datos, aplicamos PCA y calculamos la varianza explicada por cada componente. Este valor se puede obtener a partir de la propiedad explained_variance_ratio_ del objeto PCA que contiene la proporción de varianza explicada por cada componente, ya normalizada. Para calcular la varianza explicada acumulada, simplemente sumamos estos valores.
# Aplicar PCA
pca = PCA()
pca.fit(X_scaled)
# Calcular la varianza explicada acumulada
varianza_acumulada = np.cumsum(pca.explained_variance_ratio_)
# Imprimir resultados
for i, var in enumerate(varianza_acumulada):
print(f"Componentes: {i+1}, Varianza explicada acumulada: {var:.2f}")Componentes: 1, Varianza explicada acumulada: 0.40
Componentes: 2, Varianza explicada acumulada: 0.55
Componentes: 3, Varianza explicada acumulada: 0.67
Componentes: 4, Varianza explicada acumulada: 0.77
Componentes: 5, Varianza explicada acumulada: 0.83
Componentes: 6, Varianza explicada acumulada: 0.89
Componentes: 7, Varianza explicada acumulada: 0.95
Componentes: 8, Varianza explicada acumulada: 0.99
Componentes: 9, Varianza explicada acumulada: 1.00
Componentes: 10, Varianza explicada acumulada: 1.00
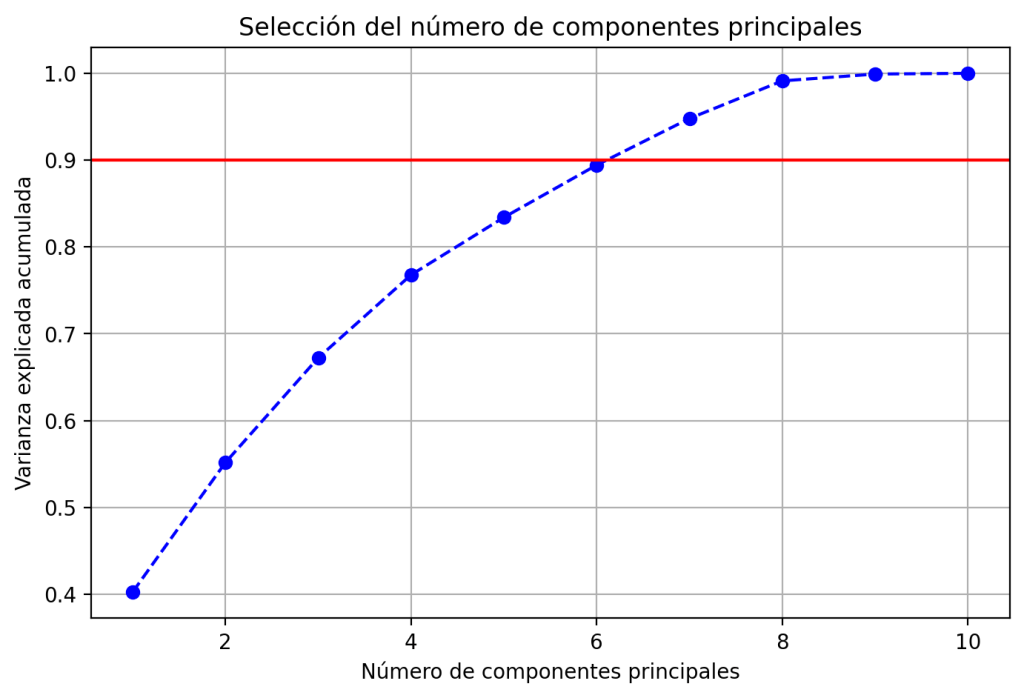
El resultado muestra que, para este conjunto de datos, son necesarios 7 componentes de los 10 totales para conservar el 90% de la varianza explicada. Curiosamente, como la varianza explicada por 6 componentes es del 89% y con 7 se alcanza el 95%, se necesitan los mismos 7 componentes para cumplir el umbral del 95%. Para el 99%, en cambio, son necesarios 8 componentes.
Paso 3: Seleccionar el número óptimo de componentes
Seleccionamos el número de componentes necesarios para alcanzar un umbral de varianza explicada, como el 90%.
umbral = 0.9 # 90% de varianza explicada
n_componentes = np.argmax(varianza_acumulada >= umbral) + 1
print(f"Número óptimo de componentes: {n_componentes}")Número óptimo de componentes: 7
En este caso, como se ha visto en la sección anterior, el número óptimo de componentes es 7.
Paso 4: Visualizar los resultados
Para complementar el análisis, graficamos la varianza explicada acumulada. Esto permite identificar visualmente el punto en el que se alcanza el umbral deseado, aunque no es estrictamente necesario para el análisis.
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 5))
plt.plot(range(1, len(varianza_acumulada) + 1), varianza_acumulada, marker='o', linestyle='--', color='b')
plt.axhline(y=umbral, color='r', linestyle='-')
plt.xlabel('Número de componentes principales')
plt.ylabel('Varianza explicada acumulada')
plt.title('Selección del número de componentes principales')
plt.grid()
plt.show()Al ejecutar este código, se genera la siguiente gráfica, que muestra cómo evoluciona la varianza explicada acumulada en función del número de componentes. Este tipo de visualización permite identificar de forma clara el punto en el que se alcanza el porcentaje deseado de información retenida, facilitando la selección del número óptimo de componentes.
Función en Python para automatizar el proceso
Dado que esta es una tarea habitual, es útil contar con una función que automatiza el cálculo del número óptimo de componentes. Una posible implementación de esta función podría ser la que se muestra a continuación.
def seleccionar_componentes(X, umbral=0.9):
"""
Selecciona el número óptimo de componentes principales según la varianza explicada.
Parámetros:
X (array-like): Datos de entrada (normalizados).
umbral (float): Umbral de varianza explicada acumulada (por defecto 0.9).
Devuelve:
int: Número de componentes principales seleccionados.
"""
# Normalizar los datos
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Aplicar PCA
pca = PCA()
pca.fit(X_scaled)
# Calcular varianza acumulada
varianza_acumulada = np.cumsum(pca.explained_variance_ratio_)
# Encontrar el número óptimo de componentes
n_componentes = np.argmax(varianza_acumulada >= umbral) + 1
return n_componentesEsta función toma un conjunto de datos como entrada y devuelve el número de componentes necesarios según el umbral de varianza explicada especificado. Una función que se puede usar fácilmente como se muestra a continuación.
n_componentes = seleccionar_componentes(df, umbral=0.9)
print(f"Número de componentes seleccionados: {n_componentes}")Número de componentes seleccionados: 7
Conclusiones
El método de la varianza explicada acumulada es una técnica sencilla y efectiva para seleccionar el número de componentes principales en PCA, siendo un hiperparámetro clave al realizar este análisis. De esta forma, se obtiene un conjunto de datos que conserva una proporción significativa de la información original mientras se reduce su dimensionalidad. Esto no solo facilita el análisis y la visualización, sino que también puede ayudar a eliminar el ruido y mejorar el rendimiento de modelos de aprendizaje automático.
Además, en esta entrada hemos incluido una función automatizada que facilita este proceso, adaptándose a diferentes conjuntos de datos y umbrales según las necesidades del usuario.
Nota: La imagen de este artículo fue generada utilizando un modelo de inteligencia artificial.
Deja una respuesta