Cuando un banco evalúa una solicitud de crédito necesita responder a una pregunta aparentemente simple: ¿cuál es la probabilidad de que este cliente no pague? Para responderla dispone de decenas de variables sobre el solicitante — sus ingresos, su edad, el importe que solicita — pero esas variables tienen escalas, unidades y distribuciones completamente distintas. ¿Cómo combinar en un único modelo información tan heterogénea?
Durante décadas, el sector financiero ha confiado en dos métricas fundamentales: Weight of Evidence (WOE) y Information Value (IV). Estas dos métricas son la base matemática sobre la que se construyen los scorecards de crédito — los modelos que asignan una puntuación a cada solicitante y que determinan, en buena medida, si obtienes un préstamo o no.
En esta entrada explicaremos qué son el WOE y el IV, cómo se calculan, cómo se interpretan y por qué siguen siendo las métricas de referencia en credit scoring décadas después de su introducción. Todos los conceptos se pueden explorar de forma interactiva en el constructor de scorecards del laboratorio de Analytics Lane.
Tabla de contenidos
- 1 El problema que resuelven el WOE y el IV
- 2 Discretización: el paso previo
- 3 El Weight of Evidence (WOE)
- 4 El Information Value (IV)
- 5 WOE y regresión logística: una relación natural
- 6 De los coeficientes al scorecard
- 7 Problemas comunes en el cálculo del WOE y el IV
- 8 El IV como métrica de selección de variables
- 9 WOE, IV y las alternativas modernas
- 10 Conclusiones
El problema que resuelven el WOE y el IV
Imagina que tienes un conjunto de datos con 50.000 solicitudes de crédito, de las cuales 5.000 acabaron en default (impago). Tienes una variable llamada ingreso_anual que va desde 0 hasta 850.000 euros. Quieres saber dos cosas:

- ¿Esta variable es útil para predecir el default?
- Si es útil, ¿cómo la transformas para que pueda entrar en un modelo estadístico junto con otras variables de naturaleza completamente distinta — como la categoría de empleo, el número de productos contratados o el código postal?
El primer problema es de selección de variables: necesitas una métrica que te diga cuánto poder predictivo tiene cada variable. El segundo es de transformación: necesitas convertir cada variable a una escala común que preserve su relación con la variable objetivo (en el caso de los modelos de scoring, si acaba en default) y que sea compatible con la regresión logística.
El WOE resuelve el segundo problema. El IV resuelve el primero. Y lo hacen de forma simultánea y coherente — el IV se calcula a partir del WOE, y ambos se definen sobre los mismos bins en los que has discretizado la variable.
Discretización: el paso previo
Antes de calcular el WOE y el IV es necesario discretizar las variables continuas en intervalos (bins) y agrupar las categorías de las variables categóricas. Este proceso se llama binning.
Para la variable ingreso_anual podríamos crear estos bins:
| Bin | Rango |
|---|---|
| 1 | [Missing] |
| 2 | (-∞, 15.000€] |
| 3 | (15.000€, 25.000€] |
| 4 | (25.000€, 40.000€] |
| 5 | (40.000€, 60.000€] |
| 6 | (60.000€, 100.000€] |
| 7 | (100.000€, +∞) |
El binning no es trivial — un buen binning captura la relación entre la variable independiente y la variable objetivo de forma que el WOE sea monótono (siempre creciente o siempre decreciente), los bins tienen suficientes observaciones para que el WOE sea estadísticamente estable, y los puntos de corte tienen interpretación económica. Pero ese es el tema de otro artículo. Por ahora asumimos que tenemos los bins definidos y procedemos al cálculo del WOE.
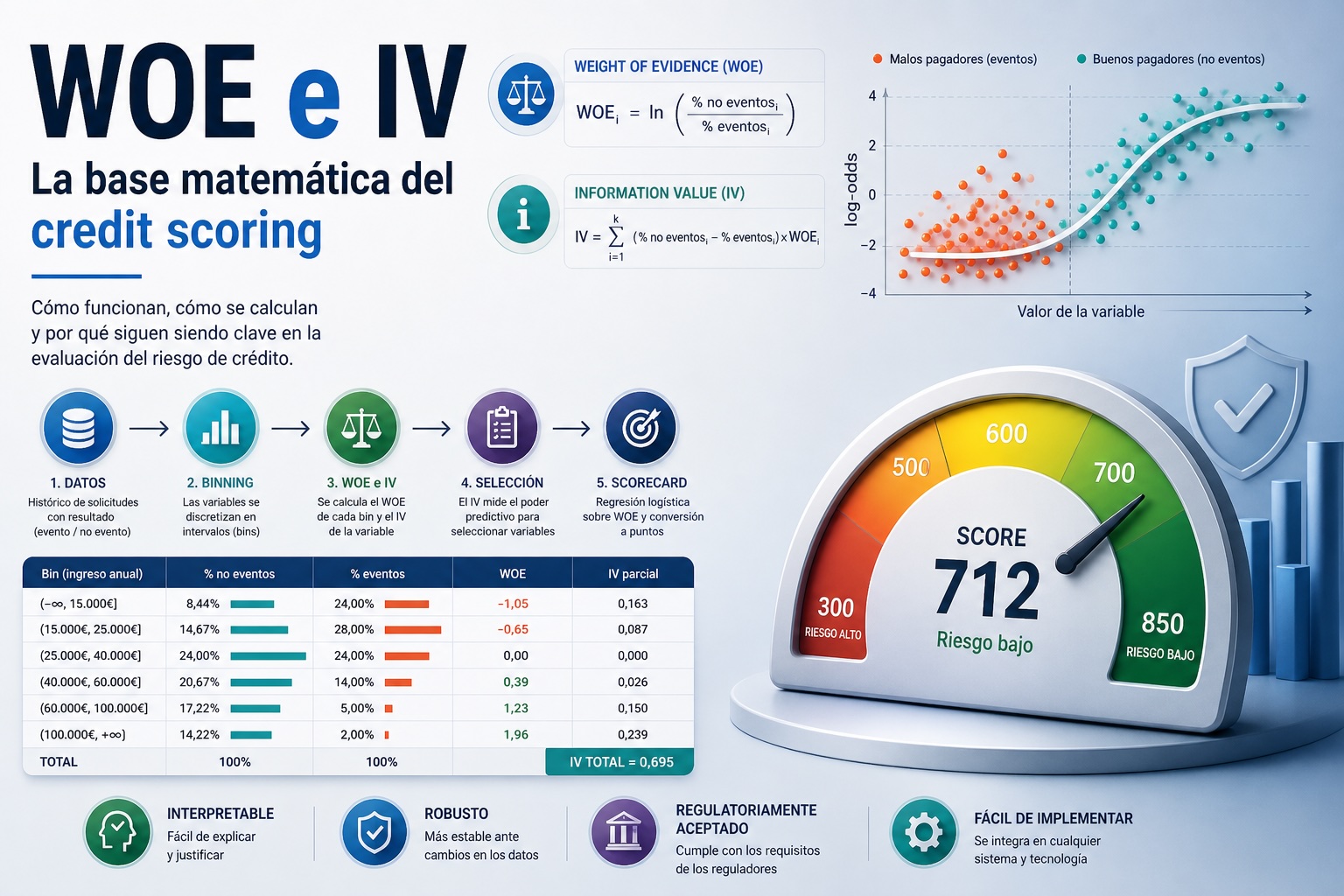
El Weight of Evidence (WOE)
El WOE de un bin mide la separación entre la distribución de buenos pagadores (no eventos) y malos pagadores (eventos) en ese bin. Se define como: WOE_i = \ln\left(\frac{\% \text{ no eventos}_i}{\% \text{ eventos}_i}\right) donde:
- \% \text{ no eventos}_i es la proporción de todos los no eventos del dataset que caen en el bin i
- \% \text{ eventos}_i es la proporción de todos los eventos del dataset que caen en el bin i
Un ejemplo concreto
Siguiendo con ingreso_anual, supongamos que en nuestro conjunto de datos hay 5.000 eventos (defaults) y 45.000 no eventos (buenos pagadores). La tabla completa sería:
| Bin | Rango | N total | N eventos | N no eventos | % eventos | % no eventos | WOE |
|---|---|---|---|---|---|---|---|
| 1 | [Missing] | 500 | 150 | 350 | 3,00% | 0,78% | ln(0,78/3,00) = −1,35 |
| 2 | (-∞, 15K] | 5.000 | 1.200 | 3.800 | 24,00% | 8,44% | ln(8,44/24,00) = −1,05 |
| 3 | (15K, 25K] | 8.000 | 1.400 | 6.600 | 28,00% | 14,67% | ln(14,67/28,00) = −0,65 |
| 4 | (25K, 40K] | 12.000 | 1.200 | 10.800 | 24,00% | 24,00% | ln(24,00/24,00) = 0,00 |
| 5 | (40K, 60K] | 10.000 | 700 | 9.300 | 14,00% | 20,67% | ln(20,67/14,00) = +0,39 |
| 6 | (60K, 100K] | 8.000 | 250 | 7.750 | 5,00% | 17,22% | ln(17,22/5,00) = +1,23 |
| 7 | (100K, +∞) | 6.500 | 100 | 6.400 | 2,00% | 14,22% | ln(14,22/2,00) = +1,96 |
| Total | 50.000 | 5.000 | 45.000 | 100% | 100% |
Interpretación del WOE
Con la convención WOE = \ln(\% \text{ no eventos} / \% \text{ eventos}):
- WOE positivo: el bin tiene más no eventos (buenos pagadores) que lo esperado. A mayor WOE positivo, mayor concentración de buenos pagadores — menor riesgo
- WOE negativo: el bin tiene más eventos (malos pagadores) que lo esperado. A mayor WOE negativo en valor absoluto, mayor concentración de malos pagadores — mayor riesgo
- WOE = 0:el bin tiene exactamente la misma proporción de eventos y no eventos que el total del conjunto de datos — riesgo neutro
En nuestro ejemplo el bin de ingresos más bajos (< 15.000€) tiene WOE = −1,05, lo que indica que ese segmento tiene una concentración de malos pagadores significativamente mayor que la media. El bin de ingresos más altos (> 100.000€) tiene WOE = +1,96, indicando una concentración muy alta de buenos pagadores.
La relación entre WOE y log-odds
El WOE no es una métrica arbitraria — tiene una interpretación matemática precisa en el contexto de la regresión logística. Las log-odds (logaritmo de las probabilidades relativas) de default en el bin i son: \ln\left(\frac{P(\text{default})_i}{1-P(\text{default})_i}\right) = \ln\left(\frac{\text{tasa eventos}_i}{\text{tasa no eventos}_i}\right)
Y el WOE está directamente relacionado con la desviación de esas log-odds respecto a las log-odds globales del conjunto de datos: WOE_i = \ln\left(\frac{\% \text{ no eventos}_i}{\% \text{ eventos}_i}\right) = -\ln\left(\frac{\% \text{ eventos}_i}{\% \text{ no eventos}_i}\right)
Esta relación es lo que hace que la regresión logística sobre variables transformadas a WOE tenga propiedades matemáticas convenientes que exploraremos más adelante.

El Information Value (IV)
El IV mide el poder predictivo total de una variable — cuánto contribuye esa variable a separar eventos de no eventos en el conjunto de datos completo. Se calcula como la suma ponderada de los WOE de todos los bins: IV = \sum_{i=1}^{k} \left(\% \text{ no eventos}_i - \% \text{ eventos}_i\right) \times WOE_i
Sustituyendo la definición del WOE: IV = \sum_{i=1}^{k} \left(\% \text{ no eventos}_i - \% \text{ eventos}_i\right) \times \ln\left(\frac{\% \text{ no eventos}_i}{\% \text{ eventos}_i}\right)
Cálculo del IV para ingreso_anual
Usando los datos de nuestra tabla:
| Bin | % no eventos | % eventos | Diferencia | WOE | IV parcial |
|---|---|---|---|---|---|
| 1 | 0,78% | 3,00% | −2,22% | −1,35 | (−0,0222) × (−1,35) = 0,030 |
| 2 | 8,44% | 24,00% | −15,56% | −1,05 | (−0,1556) × (−1,05) = 0,163 |
| 3 | 14,67% | 28,00% | −13,33% | −0,65 | (−0,1333) × (−0,65) = 0,087 |
| 4 | 24,00% | 24,00% | 0,00% | 0,00 | 0,000 |
| 5 | 20,67% | 14,00% | +6,67% | +0,39 | (+0,0667) × (+0,39) = 0,026 |
| 6 | 17,22% | 5,00% | +12,22% | +1,23 | (+0,1222) × (+1,23) = 0,150 |
| 7 | 14,22% | 2,00% | +12,22% | +1,96 | (+0,1222) × (+1,96) = 0,239 |
| Total | 100% | 100% | IV = 0,695 |
Interpretación del IV
El IV tiene una interpretación estándar en la industria del credit scoring:
| IV | Poder predictivo |
|---|---|
| < 0,02 | Sin poder predictivo — excluir |
| 0,02 – 0,10 | Débil |
| 0,10 – 0,30 | Medio |
| 0,30 – 0,50 | Fuerte |
| > 0,50 | Sospechoso — revisar posible data leakage |
Con IV = 0,695 nuestra variable ingreso_anual tiene un IV muy alto — superior a 0,50. Esto debería hacernos sospechar de data leakage (información del futuro) antes de incluirla en el modelo. En un caso real deberíamos revisar si esta variable realmente está disponible en el momento de la solicitud o si contiene información posterior al evento de default.
Por qué el IV siempre es positivo
Observa que en la fórmula del IV cada término es siempre positivo:
- Si % \text{ no eventos}_i > % \text{ eventos}_i entonces la diferencia es positiva y el WOE también es positivo
- Si % \text{ no eventos}_i < % \text{ eventos}_i entonces la diferencia es negativa y el WOE también es negativo
- El producto de dos números del mismo signo es siempre positivo
Esto significa que el IV acumula la contribución de todos los bins independientemente de la dirección de la relación — un bin de alto riesgo contribuye tanto al IV como un bin de bajo riesgo. El IV mide la magnitud de la separación total entre eventos y no eventos, no su dirección.
WOE y regresión logística: una relación natural
Una de las propiedades más importantes del WOE es su compatibilidad con la regresión logística. Cuando se ajusta una regresión logística sobre variables transformadas a WOE ocurre algo matemáticamente elegante.
Variables transformadas a WOE
Una vez calculado el WOE de cada bin, se transforma el dataset reemplazando cada valor de la variable original por el WOE del bin al que pertenece:
ingreso_anual = 18.000€ → bin 3 → WOE = −0,65 ingreso_anual = 75.000€ → bin 6 → WOE = +1,23 ingreso_anual = null → bin 1 → WOE = −1,35
El conjunto de datos transformado tiene exactamente las mismas filas que el original pero con valores de WOE en lugar de los valores originales.
Por qué funciona tan bien
La regresión logística modela las log-odds de default como combinación lineal de las variables: \ln\left(\frac{P(\text{default})}{1-P(\text{default})}\right) = \alpha + \beta_1 X_1 + \beta_2 X_2 + \ldots + \beta_k X_k
Cuando X_i es el WOE de la variable i, el coeficiente \beta_i tiene una interpretación directa: mide cuánto contribuye una unidad de WOE de esa variable a las log-odds de default. Con la convención WOE = \ln(% \text{ no eventos} / % \text{ eventos}), los coeficientes bien estimados deben ser negativos — a mayor WOE (menor riesgo), menor log-odds de default.
Además la transformación a WOE tiene otras ventajas prácticas:
- Manejo automático de valores atípicos: Un outlier (valor atípico) extremo en
ingreso_anual(por ejemplo 2.500.000€) simplemente cae en el bin más alto y recibe el WOE de ese bin. No distorsiona el modelo. - Manejo de valores nulos: Los nulos pueden tener su propio bin con su propio WOE — no necesitan obligatoriamente una imputación previa.
- Variables en la misma escala: Después de la transformación todas las variables están en escala de WOE, lo que hace que los coeficientes de la regresión sean comparables entre sí.
- Linealización de relaciones no lineales: La relación entre
ingreso_anualy las log-odds de default no es lineal en los valores originales — pero sí lo es (por construcción) en los valores WOE.
De los coeficientes al scorecard
Una vez ajustada la regresión logística sobre las variables WOE se obtienen los coeficientes \beta_i para cada variable. Pero un scorecard no usa directamente esos coeficientes — los transforma en puntos enteros que suman para dar el score final.
La transformación usa tres parámetros definidos por el analista:
- Score base (B): el score asignado a las odds (probabilidades relativas) de referencia (típicamente 600)
- PDO (Points to Double the Odds): cuántos puntos equivalen a doblar las odds de buen pagador (típicamente 20)
- Odds de referencia ($\theta_0$): las odds de buen pagador en el score base (típicamente 50:1)
Con estos parámetros se calculan dos constantes: \text{Factor} = \frac{PDO}{\ln(2)} \text{Offset} = B - \text{Factor} \times \ln(\theta_0)
Y los puntos asignados a cada bin de cada variable son:
\text{Puntos}_{ij} = -\left(\beta_i \times WOE_{ij} + \frac{\alpha}{n}\right) \times \text{Factor},donde \alpha es el intercepto de la regresión, n es el número de variables y j es el bin de la variable i.
El score final de un cliente es: \text{Score} = \text{Offset} + \sum_{i=1}^{n} \text{Puntos}_{ij}
Un ejemplo numérico
Con Factor = 20/ln(2) ≈ 28,85 y Offset = 600 − 28,85 × ln(50) ≈ 487,1, y suponiendo que la variable ingreso_anual tiene coeficiente β = −0,876 y el intercepto repartido aporta −5 puntos por variable:
| Bin | WOE | Puntos |
|---|---|---|
| [Missing] | −1,35 | ≈ −32 |
| (-∞, 15K] | −1,05 | ≈ −24 |
| (15K, 25K] | −0,65 | ≈ −13 |
| (25K, 40K] | 0,00 | ≈ +5 |
| (40K, 60K] | +0,39 | ≈ +15 |
| (60K, 100K] | +1,23 | ≈ +40 |
| (100K, +∞) | +1,96 | ≈ +62 |
Un cliente con ingreso de 75.000€ recibiría +40 puntos por esta variable. Un cliente con ingreso de 12.000€ recibiría −24 puntos. La diferencia de 64 puntos entre estos dos clientes solo por el ingreso refleja la diferente probabilidad de default que observamos en los datos.

Problemas comunes en el cálculo del WOE y el IV
El uso del WOE y el IV no está exento de problemas, algunos de los más habituales se enumeran a continuación.
El problema de los bins con cero eventos o cero no eventos
Si un bin no tiene ningún evento, es decir, % \text{ eventos}_i = 0$, el logaritmo del WOE no está definido. La solución estándar es aplicar una corrección de continuidad pequeña — sumar 0,5 a los conteos de cero antes de calcular los porcentajes. Aunque introduce un pequeño sesgo es preferible a no poder calcular el WOE.
El problema del WOE inestable en bins pequeños
Un bin con pocas observaciones tiene un WOE calculado sobre una muestra pequeña que puede no ser representativo de la población. Un bin con 10 observaciones y 3 defaults tiene tasa de default del 30% — pero ese 30% tiene un intervalo de confianza muy amplio. La regla práctica es que cada bin debe tener al menos 50 observaciones y al menos 10 eventos y 10 no eventos.
El problema de la monotonía
En credit scoring se prefieren variables con WOE monótono — siempre creciente o siempre decreciente al ordenar los bins por valor de la variable. Un WOE monótono significa que la relación entre la variable y el riesgo es consistente y fácil de interpretar. Una relación no monótona puede indicar un binning subóptimo o una variable genuinamente no monótona que requiere tratamiento especial.
El problema del data leakage
Un IV muy alto (> 0,50) es una señal de alarma. En casos legítimos puede ocurrir — una variable puede tener realmente un poder predictivo muy alto — pero con frecuencia indica que la variable contiene información del futuro (posterior al evento de default) que no estaría disponible en el momento de la decisión. Antes de incluir una variable con IV > 0,50 conviene verificar cuidadosamente su definición y su disponibilidad temporal.
El IV como métrica de selección de variables
Una de las aplicaciones más prácticas del IV es la selección de variables para el modelo. El proceso típico es:
- Calcular el IV de todas las variables disponibles
- Excluir las variables con IV < 0,02 — sin poder predictivo suficiente
- Excluir o revisar las variables con IV > 0,50 — posible data leakage
- Ordenar las variables restantes por IV de mayor a menor
- Seleccionar las N variables con mayor IV como punto de partida
Este proceso tiene la ventaja de ser rápido, interpretable y agnóstico respecto al tipo de variable — el IV de una variable numérica y el de una categórica son directamente comparables porque ambos están en la misma escala.
Sin embargo el IV tiene una limitación importante como criterio de selección: es univariante. Mide el poder predictivo de cada variable por separado, sin considerar la correlación entre variables. Dos variables altamente correlacionadas pueden tener ambas un IV alto pero aportar información redundante al modelo. Por eso el IV se complementa con un análisis de multicolinealidad entre las variables seleccionadas.
WOE, IV y las alternativas modernas
En los últimos años han aparecido alternativas al enfoque WOE/IV para la construcción de modelos de scoring — gradient boosting, redes neuronales, métodos de ensemble. Estos modelos pueden tener mejor discriminación (Gini más alto) que un scorecard tradicional. Sin embargo el enfoque WOE/IV mantiene ventajas que explican su persistencia en el sector financiero:
- Interpretabilidad regulatoria: Generalmente se exige que las decisiones automatizadas que afectan significativamente a las personas sean explicables. Un scorecard basado en WOE permite explicar exactamente cuántos puntos aporta cada variable y por qué — algo difícil de conseguir con un modelo de caja negra.
- Robustez: Un scorecard bien construido con WOE y monotonía forzada es inherentemente más robusto ante cambios en la distribución de los datos que un modelo complejo. Cuando la distribución cambia (lo que inevitablemente ocurre con el tiempo), un scorecard degrada de forma más predecible y gradual.
- Facilidad de implementación: Un scorecard es una tabla de puntos. Se puede implementar en cualquier sistema — Excel, SQL, una aplicación legada — sin necesidad de una infraestructura de ML. En entidades financieras con sistemas heredados esto es una ventaja práctica enorme.
- Validación regulatoria: Los reguladores financieros tienen guías de validación de modelos bien establecidas para scorecards basados en regresión logística y WOE. Validar un modelo de gradient boosting para uso en decisiones de crédito regulado es significativamente más complejo.
Conclusiones
El WOE y el IV son herramientas matemáticamente sencillas — una es un logaritmo de un cociente, la otra es una suma ponderada — pero su impacto en el credit scoring ha sido enorme. Proporcionan una forma coherente de transformar variables heterogéneas a una escala común, medir su poder predictivo individual y construir modelos interpretables que cumplen con los requisitos regulatorios.
La fórmula WOE = \ln(\% \text{ no eventos} / \% \text{ eventos}) resume en una línea la esencia del problema de credit scoring: medir cuánto se desvía la distribución de buenos y malos pagadores en cada segmento respecto a la distribución global. Cuando esa desviación es grande y consistente tenemos una variable útil. Cuando es pequeña o errática no merece entrar en el modelo.
Por eso, a pesar del auge de modelos más complejos, el WOE y el IV siguen siendo, en muchos contextos, la forma más sólida y fiable de construir modelos de riesgo de crédito.
Si quieres explorar estos conceptos de forma interactiva — calcular el WOE e IV de tus propias variables, ver cómo el binning afecta a los resultados y construir un scorecard completo — puedes hacerlo en el constructor de scorecards del laboratorio de Analytics Lane, en tu navegador y sin que tus datos salgan de tu dispositivo. Una vez creado tu scorecards, también lo puede aplicarlo a cualquier conjunto de datos con la herramienta para aplicar los scorecards del laboratorio de Analytics Lane.
Nota: Las imágenes de este artículo fueron generadas utilizando un modelo de inteligencia artificial.
Deja una respuesta