
Cuando hablamos de clustering, lo primero que viene a la mente suele ser k-means. Pero k-means tiene dos limitaciones importantes: hay que decidir cuántos clusters queremos a priori, y trata cualquier punto como parte de algún grupo, aunque sea claramente un valor atípico.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) resuelve precisamente esos dos problemas:
- No necesita que le digamos cuántos clusters hay.
- Detecta el ruido de forma natural.
- Encuentra clusters de formas arbitrarias (no solo “bolitas” como es el caso de k-means).
Pero todo tiene un precio: DBSCAN depende crucialmente de un hiperparámetro llamado ε (épsilon), y elegirlo bien es la diferencia entre un análisis útil y uno completamente inservible.
En esta entrada vamos a ver:
- Cómo funciona DBSCAN por dentro.
- Qué significa realmente ε.
- Cómo usar la herramienta interactiva del Laboratorio de Analytics Lane para elegirlo sin esfuerzo.
- Cómo replicar exactamente ese proceso en Python.
Tabla de contenidos
- 1 ¿Cómo funciona DBSCAN?
- 2 El gran problema: elegir ε
- 3 La idea clave: el gráfico de distancias k
- 4 ¿Dónde está ε? El “codo”
- 5 Usando la herramienta interactiva
- 6 Intuición visual: por qué es más que una heurística
- 7 Cómo replicarlo en Python
- 8 Detectando el codo automáticamente
- 9 Aplicar DBSCAN con ese ε
- 10 Buenas prácticas
- 11 Conclusiones
¿Cómo funciona DBSCAN?
La idea central de DBSCAN es muy intuitiva:
Un cluster es una región densa de puntos rodeada de regiones poco densas.
Piensa en una fiesta vista desde el techo: los grupos de gente conversando son los clusters, las personas sueltas paseando son ruido. DBSCAN identifica exactamente estos patrones en los datos, pero formalmente.
Los dos hiperparámetros
Para definir qué significa “denso”, DBSCAN necesita dos hiperparámetros numéricos:

- ε (epsilon): el radio de vecindad. Define qué entendemos por “estar cerca”.
- minPts: el número mínimo de vecinos dentro de ese radio para considerar una zona como densa.
Tres tipos de puntos
En base a estos dos hiperparámetro, cada punto del conjunto de datos cae en una de la siguientes tres categorías:
- Puntos núcleo (core): tienen al menos
minPtsvecinos dentro del radio ε. Son el corazón de un cluster. - Puntos frontera (border): están dentro del radio de un punto núcleo, pero no tienen suficientes vecinos propios. Forman parte del cluster, pero “en el borde”.
- Ruido (noise): ni son densos ni están cerca de un punto denso. No pertenecen a ningún clusters.
El algoritmo arranca en un punto núcleo, expande el cluster siguiendo cadenas de vecinos densos, y cuando se queda sin vecinos densos, salta a otro punto núcleo y empieza un cluster nuevo.
Todo este proceso se puede ver en directo en el simulador. Una vez cargados los datos, basta con cambiar el modo de ejecución a Paso a paso o Automático para observar cómo el algoritmo va clasificando cada punto como núcleo, frontera o ruido. Pulsa Iniciar para verlo correr de golpe, o avanza manualmente si quieres seguir en detalle cómo se actualizan los puntos en la gráfica a medida que se forman los clusters.
El gran problema: elegir ε
Como en k-means con el núcleo de clusteres, aquí está el desafío a la hora de entrenar DBSCAN. Si nos equivocamos con ε, el resultado es desastroso:
- Si ε es demasiado pequeño → casi todo se clasifica como ruido.
- Si ε es demasiado grande → todos los clusters se fusionan en uno solo.
Y lo peor: el valor “correcto” depende totalmente de la escala y la densidad de tus datos. No existe un valor universal.
Entonces, ¿cómo lo elegimos sin lanzar una moneda?
La idea clave: el gráfico de distancias k
La técnica estándar (y la que utiliza casi todo el mundo) se llama: k-distance plot (gráfico de distancias al k-ésimo vecino).
El procedimiento tiene tres pasos:
- Para cada punto del dataset, calcular la distancia a su k-ésimo vecino más cercano, donde
k = minPts. - Ordenar esas distancias de mayor a menor (orden descendente).
- Representarlas en un gráfico.
El resultado es siempre una curva decreciente: empieza alta (los puntos en zonas dispersas, con vecinos lejanos), cae de forma abrupta en algún momento, y luego se aplana en valores bajos (los puntos en zonas densas).
Nota: hay implementaciones que ordenan al revés (de menor a mayor), produciendo una curva creciente en espejo. La idea y el procedimiento son los mismos, solo cambia la orientación visual.
¿Dónde está ε? El “codo”
La magia está en buscar el famoso codo (elbow) de la curva:
- Antes del codo (parte alta) → puntos en zonas dispersas o ruido (su k-ésimo vecino está lejos).
- Después del codo (parte plana baja) → puntos que viven en zonas densas (su k-ésimo vecino está cerca).
El valor de ε se elige justo en ese punto de transición, donde la curva deja de caer abruptamente y empieza a aplanarse.
¿Por qué funciona? Porque la gráfica separa de manera natural dos regímenes muy distintos: dentro de un cluster, los vecinos están todos a distancias parecidas y pequeñas. Fuera, las distancias se disparan. El codo marca la frontera.
Usando la herramienta interactiva
Si no quieres programarlo a mano, la aplicación del Laboratorio de Analytics Lane implementa este proceso de forma visual:Simulador de DBSCAN
El flujo es muy sencillo:
- Selecciona un conjunto de datos en la aplicación.
- Pulsa sobre “¿Cómo elegir epsilon?” para acceder al componente que hace el cálculo.
- La herramienta muestra el k-distance plot y sugiere automáticamente el valor del codo.
- A partir de ahí, puedes usar ese valor sugerido o seleccionar otro manualmente si quieres ajustar la sensibilidad.
Esto convierte una heurística abstracta en una decisión visual: ves el codo, y eliges.
Intuición visual: por qué es más que una heurística
Este gráfico no es un truco arbitrario, tiene una interpretación clara:
- La parte alta → estás midiendo distancias hacia el ruido.
- La caída abrupta → es la transición: el codo.
- La parte plana baja → estás midiendo distancias dentro de los clusters.
En otras palabras, lo que el codo te dice es:
Estás estimando la densidad mínima que define un cluster en tus datos.
Es una forma de dejar que los datos hablen, en lugar de imponerles un valor a ojo.
Cómo replicarlo en Python
Ahora viene lo interesante: reproducir exactamente lo que hace la herramienta. El código TypeScript de la aplicación implementa esencialmente este algoritmo:
- Para cada punto, calcular las distancias a todos los demás puntos (excluyendo el propio).
- Ordenarlas de menor a mayor y quedarse con la k-ésima.
- Construir el array de todas esas k-distancias y ordenarlo de mayor a menor.
- Detectar el codo y devolver la distancia en esa posición como ε.
En Python son apenas unas líneas, y vamos a seguir exactamente esa misma secuencia.
Paso 1: calcular vecinos más cercanos
Queremos, para cada punto, la distancia a su k-ésimo vecino más cercano excluyendo el propio punto (justo lo que hace la aplicación con su filter(candidate.id !== point.id)).
En sklearn hay un detalle importante: cuando llamas a kneighbors(X) sobre los mismos datos con los que entrenaste, el primer vecino de cada punto es él mismo, con distancia 0. Por eso pedimos k + 1 vecinos: el primero (índice 0) es el propio punto, y los siguientes k son los vecinos reales.
from sklearn.neighbors import NearestNeighbors from sklearn.datasets import make_moons import numpy as np import matplotlib.pyplot as plt # Reemplaza X por tus datos X, _ = make_moons(n_samples=200, noise=0.2, random_state=42) k = 5 neigh = NearestNeighbors(n_neighbors=k + 1) neigh.fit(X) distances, _ = neigh.kneighbors(X)
Paso 2: quedarnos con la distancia al k-ésimo vecino
kneighbors devuelve las distancias ordenadas a los k + 1 vecinos. Como el primero es el propio punto (distancia 0), nos quedamos con el último de la fila, que es el k-ésimo vecino real:
k_distances = distances[:, k]
Paso 3: ordenar las distancias de mayor a menor
k_distances = np.sort(k_distances)[::-1] # orden descendente
Paso 4: graficar
plt.plot(k_distances)
plt.xlabel("Puntos ordenados")
plt.ylabel(f"Distancia al {k}-ésimo vecino")
plt.title("K-distance plot")
plt.grid(True)
plt.show()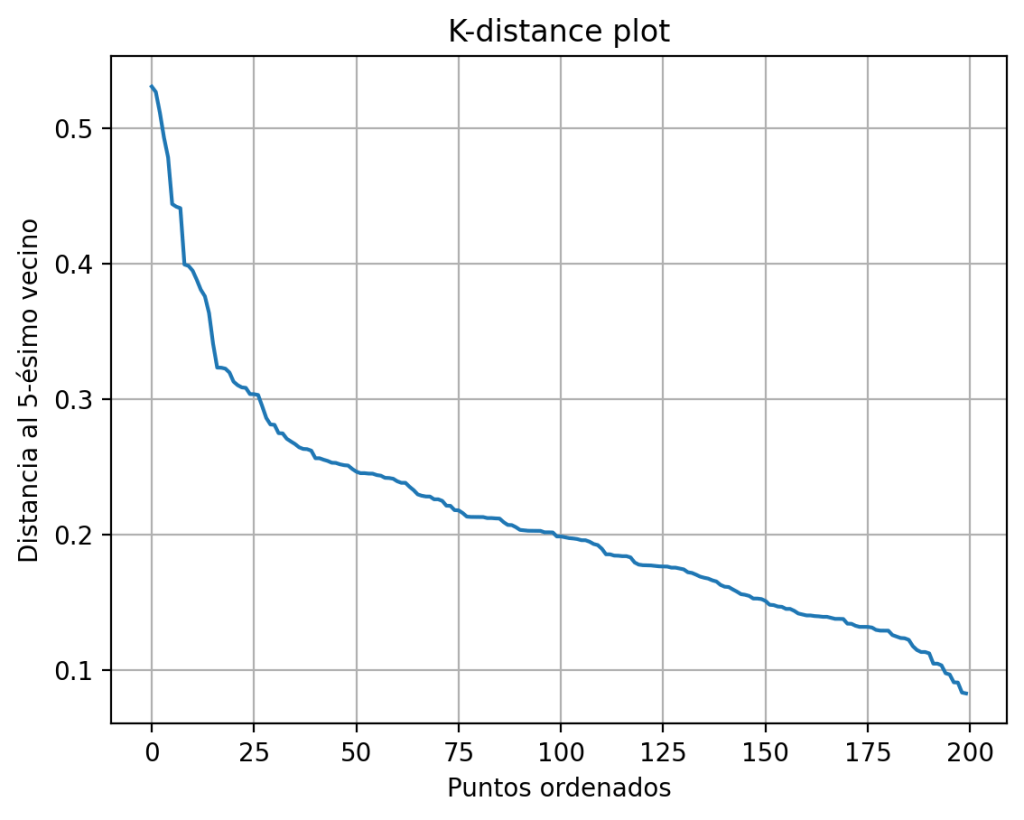
Paso 5: elegir ε visualmente
Mira la gráfica, localiza el codo, y lee el valor en el eje Y. Ese es tu ε.
Esto funciona, pero tiene un problema: depende del ojo humano. Si quieres que el proceso sea reproducible y automático (como hace la herramienta interactiva), necesitas un método matemático para localizar el codo.
Detectando el codo automáticamente
¿Cómo decide un programa dónde está el codo? Existen varios algoritmos, pero el más extendido por su simplicidad y robustez es el método de la máxima distancia a la cuerda.
La intuición geométrica
La idea es elegante:
- Imagina la curva del k-distance plot.
- Traza una línea recta que una el primer punto con el último punto de la curva. Esa recta es la “cuerda”.
- Para cada punto de la curva, mide la distancia perpendicular a esa recta.
- El codo es el punto que está más lejos de la cuerda.
¿Por qué funciona? Porque el codo es, por definición, el punto donde la curva más se aleja de su tendencia lineal global. Si la curva fuera una recta perfecta, todos los puntos estarían a distancia cero. Cuanto más pronunciado sea el codo, mayor será la distancia máxima.
Visualmente, con la curva ordenada de mayor a menor:
primer → ●
punto ●
●
● ↕ máxima distancia a la cuerda
codo → ● ↕
●
●
● ● ● ● ● ● ● ● ● ← último puntoLa cuerda es la línea recta que une el primer punto (arriba a la izquierda) con el último (abajo a la derecha). El codo es el punto de la curva más alejado de esa línea.
Un detalle importante: normalizar los ejes
Hay una trampa sutil. El eje X va de 0 a N (donde N puede ser miles de puntos), mientras que el eje Y son distancias pequeñas (a menudo entre 0 y 1). Si calculamos la distancia geométrica directamente, el eje X dominará por completo y la detección fallará.
Solución: normalizar ambos ejes al rango [0, 1] antes de calcular distancias. Así los dos ejes contribuyen por igual a la geometría.
Implementación en Python
Una nota antes del código: por qué la app muestra ε como entero y aquí no
En la aplicación interactiva, ε se presenta como un número entero por una razón puramente didáctica: los datos con los que trabaja están en coordenadas grandes (distancias del orden de cientos), así que mostrar
ε = 50en lugar deε = 49.83es más limpio en la interfaz y la parte decimal es irrelevante en esa escala.ε es un parámetro real que recibe DBSCAN, y si tus datos están escalados (con
StandardScaler, o sintéticos comomake_moons), las distancias serán del orden de 0.1 a 1.0. Por lo que se debe tratar como un real.
import numpy as np
def find_elbow(k_distances):
"""
Detecta el codo en la curva del k-distance plot usando el método
de la máxima distancia a la cuerda.
Funciona indistintamente con la curva ordenada de mayor a menor
(descendente, como en la aplicación) o de menor a mayor (ascendente),
porque la geometría es simétrica.
Devuelve
--------
elbow_idx : int
Índice del codo en el array.
elbow_eps : float
Valor de epsilon en ese punto, sin redondear.
"""
n = len(k_distances)
# 1. Coordenadas de la curva
x = np.arange(n, dtype=float)
y = np.asarray(k_distances, dtype=float)
# 2. Normalizar ambos ejes a [0, 1] para que sean comparables
x_norm = (x - x.min()) / (x.max() - x.min())
y_norm = (y - y.min()) / (y.max() - y.min())
# 3. Definir la cuerda (primer punto -> último punto)
p1 = np.array([x_norm[0], y_norm[0]])
p2 = np.array([x_norm[-1], y_norm[-1]])
line_vec = p2 - p1
line_len = np.linalg.norm(line_vec)
# 4. Distancia perpendicular de cada punto a la cuerda
# (fórmula del producto cruz en 2D, en valor absoluto)
points = np.column_stack([x_norm, y_norm])
cross = np.abs(
line_vec[0] * (p1[1] - points[:, 1]) -
(p1[0] - points[:, 0]) * line_vec[1]
)
distances_to_line = cross / line_len
# 5. El codo es el punto con máxima distancia a la cuerda
elbow_idx = int(np.argmax(distances_to_line))
elbow_eps = float(k_distances[elbow_idx])
return elbow_idx, elbow_epsY se usa así, encadenado con los pasos anteriores:
elbow_idx, eps_auto = find_elbow(k_distances)
print(f"Codo detectado en el índice {elbow_idx}, ε ≈ {eps_auto:.4f}")Codo detectado en el índice 31, ε ≈ 0.2746
Visualizar el resultado
Para ganar confianza en el valor detectado, conviene representarlo sobre la gráfica:
plt.plot(k_distances, label="Distancia al k-ésimo vecino")
plt.axvline(elbow_idx, color="red", linestyle="--", label=f"Codo (idx={elbow_idx})")
plt.axhline(eps_auto, color="green", linestyle="--", label=f"ε ≈ {eps_auto:.4f}")
plt.xlabel("Puntos ordenados (descendente)")
plt.ylabel(f"Distancia al {k}-ésimo vecino")
plt.title("Detección automática del codo")
plt.legend()
plt.grid(True)
plt.show()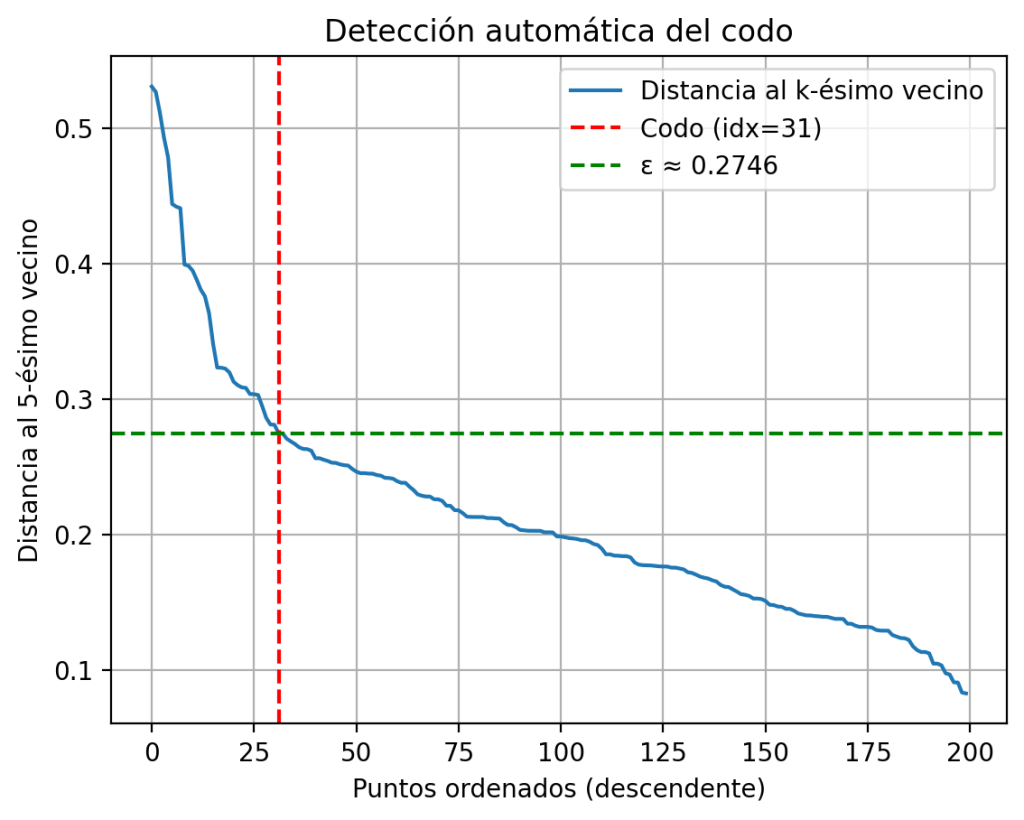
Este es exactamente el proceso que hace la herramienta interactiva por debajo: calcula el k-distance plot, normaliza los ejes, busca el punto de máxima distancia a la cuerda, y te lo muestra como sugerencia.
Alternativa: la librería kneed
Si prefieres no implementarlo a mano, existe una librería ya hecha llamada kneed, que implementa el algoritmo Kneedle (Satopaa et al., 2011), una versión más sofisticada de la misma idea:
from kneed import KneeLocator
knee = KneeLocator(
range(len(k_distances)),
k_distances,
curve="convex",
direction="decreasing", # nuestra curva está ordenada de mayor a menor
)
eps_auto = float(k_distances[knee.knee])
print(f"ε automático (kneed) ≈ {eps_auto:.4f}")Ambos métodos suelen dar valores muy parecidos. La función casera tiene la ventaja de ser transparente: ves exactamente qué está haciendo y por qué.
Aplicar DBSCAN con ese ε
Una vez tienes el valor, ejecutar DBSCAN es trivial:
from sklearn.cluster import DBSCAN eps = eps_auto # valor decimal devuelto por find_elbow, sin redondear min_samples = k # el mismo k que usaste antes model = DBSCAN(eps=eps, min_samples=min_samples) labels = model.fit_predict(X)
labels te devuelve la asignación de cada punto a un cluster. El valor -1 indica ruido.
Buenas prácticas
1. Elegir minPts con criterio
Una regla práctica muy extendida:
minPts ≈ 2 × (número de dimensiones)
En 2D, minPts = 4 o 5 suele funcionar bien. En espacios de mayor dimensión, conviene aumentarlo.
2. Escalar los datos antes de nada
DBSCAN se basa en distancias, así que si una variable va de 0 a 1 y otra de 0 a 1.000.000, la segunda dominará todo. Estandariza siempre:
from sklearn.preprocessing import StandardScaler X_scaled = StandardScaler().fit_transform(X)
3. No existe un único ε “perfecto”
El método del codo es una heurística, no una fórmula matemática exacta. A veces el codo es muy claro, otras veces hay varios candidatos razonables. No te obsesiones: prueba dos o tres valores cercanos y compara los resultados.
4. Valida los resultados
Antes de dar por bueno un clustering:
- Visualiza los clusters (en 2D directamente, en alta dimensión usa PCA o UMAP).
- Revisa cuántos puntos quedan etiquetados como ruido. Si es el 80%, tu ε es probablemente demasiado pequeño.
- Usa métricas como silhouette, pero con cautela: están diseñadas para clusters convexos y no siempre reflejan bien la calidad de un clustering basado en densidad.
Conclusiones
La selección de ε en DBSCAN no tiene por qué ser un misterio:
- Se apoya en la estructura de densidad de los propios datos.
- El k-distance plot la hace visible.
- El codo marca la frontera natural entre clusters y ruido.
Una herramienta interactiva como la del Laboratorio de Analytics Lane aporta algo muy valioso: convierte una heurística abstracta en una decisión visual e inmediata. Y lo mejor es que ese mismo proceso es totalmente reproducible en Python con apenas unas líneas de código.
Al final, DBSCAN es un algoritmo poderoso, pero como toda herramienta potente, exige entenderla. Saber elegir ε es saber escuchar lo que los datos te están diciendo sobre su propia densidad.
Imagen de WikiImages en Pixabay
Deja una respuesta