Tienes los datos de ventas de tres productos en dos años distintos y quieres saber cuál creció más. Podrías hacer dos gráficos separados… pero tu cerebro tardaría el doble en extraer conclusiones. La solución es un gráfico de barras comparativo, y en esta entrada verás exactamente cómo construirlo en Python con Matplotlib, paso a paso.
En concreto, veremos tres técnicas fundamentales:
- Barras agrupadas (grouped bar charts): para comparar valores directamente entre grupos.
- Barras apiladas (stacked bar charts): para ver la composición del total.
- Barras porcentuales: para analizar proporciones y eliminar el efecto del tamaño absoluto.
Al final del artículo encontrarás una tabla resumen para saber cuándo usar cada una.
Tabla de contenidos
- 1 Recordatorio rápido: el gráfico de barras básico
- 2 Gráficos de barras agrupadas (Grouped Bar Charts)
- 3 Gráficos de barras apiladas (Stacked Bar Charts)
- 4 Comparación porcentual (barras normalizadas)
- 5 Mejoras estéticas para gráficos más legibles
- 6 Errores comunes y cómo evitarlos
- 7 Caso práctico completo
- 8 Resumen: ¿cuándo usar cada tipo de gráfico?
- 9 Conclusiones
Recordatorio rápido: el gráfico de barras básico
Antes de entrar en comparaciones, repasemos la forma más simple de crear un gráfico de barras en Matplotlib:
import matplotlib.pyplot as plt
categorias = ['A', 'B', 'C']
valores = [10, 15, 7]
plt.bar(categorias, valores)
plt.title("Gráfico de barras básico")
plt.ylabel("Valores")
plt.show()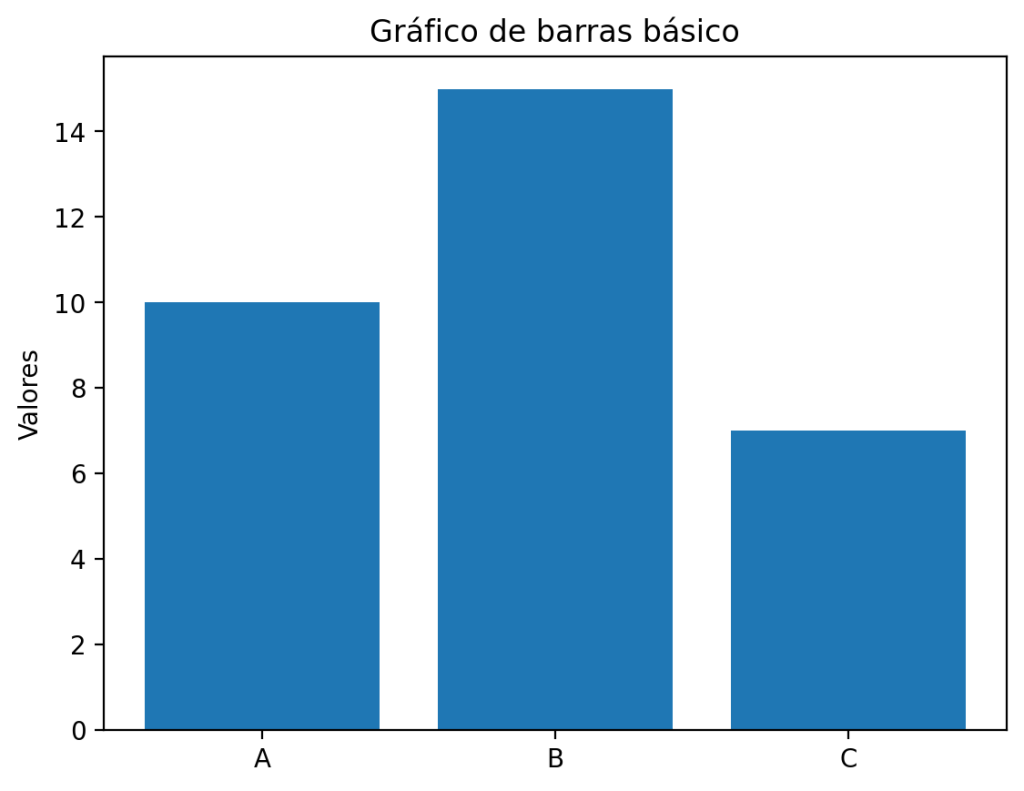
Este gráfico funciona perfectamente cuando tienes una sola variable y categorías independientes. Pero en cuanto quieres añadir una segunda serie de datos —por ejemplo, los mismos productos en un año diferente— este enfoque se queda corto. No puedes superponer dos llamadas a plt.bar() sin que las barras se solapen o se oculten entre sí.

Es justo ahí donde necesitas las técnicas que vamos a ver a continuación.
Gráficos de barras agrupadas (Grouped Bar Charts)
Las barras agrupadas son la elección correcta cuando quieres comparar directamente dos o más series dentro de la misma categoría. Por ejemplo:
- Ventas de varios productos en distintos años.
- Rendimiento de algoritmos en distintos conjuntos de datos.
- Resultados de encuestas segmentadas por edad o región.
El concepto clave: posicionamiento numérico
Matplotlib no trabaja internamente con categorías de texto como 'Producto A' o 'Q1'. En realidad, todo se basa en posiciones numéricas en el eje X. Esto nos da el control total para desplazar las barras horizontalmente y evitar que se solapen.
El truco consiste en seguir los siguientes tres pasos:
- Convertir las categorías en números con
np.arange. - Definir el ancho de cada barra.
- Desplazar cada grupo de barras hacia la izquierda o la derecha.
Implementación con dos series
Empecemos con el caso más habitual: comparar dos años de ventas para tres productos.
import numpy as np
import matplotlib.pyplot as plt
categorias = ['Producto A', 'Producto B', 'Producto C']
ventas_2023 = [10, 15, 20]
ventas_2024 = [12, 18, 25]
# Paso 1: convertir categorías en posiciones numéricas
x = np.arange(len(categorias)) # → [0, 1, 2]
# Paso 2: definir el ancho de cada barra
width = 0.35
# Paso 3: dibujar las barras desplazadas
plt.bar(x - width/2, ventas_2023, width, label='2023')
plt.bar(x + width/2, ventas_2024, width, label='2024')
# Sustituir los números del eje X por las etiquetas reales
plt.xticks(x, categorias)
plt.ylabel('Ventas')
plt.title('Comparación de ventas por producto')
plt.legend()
plt.show()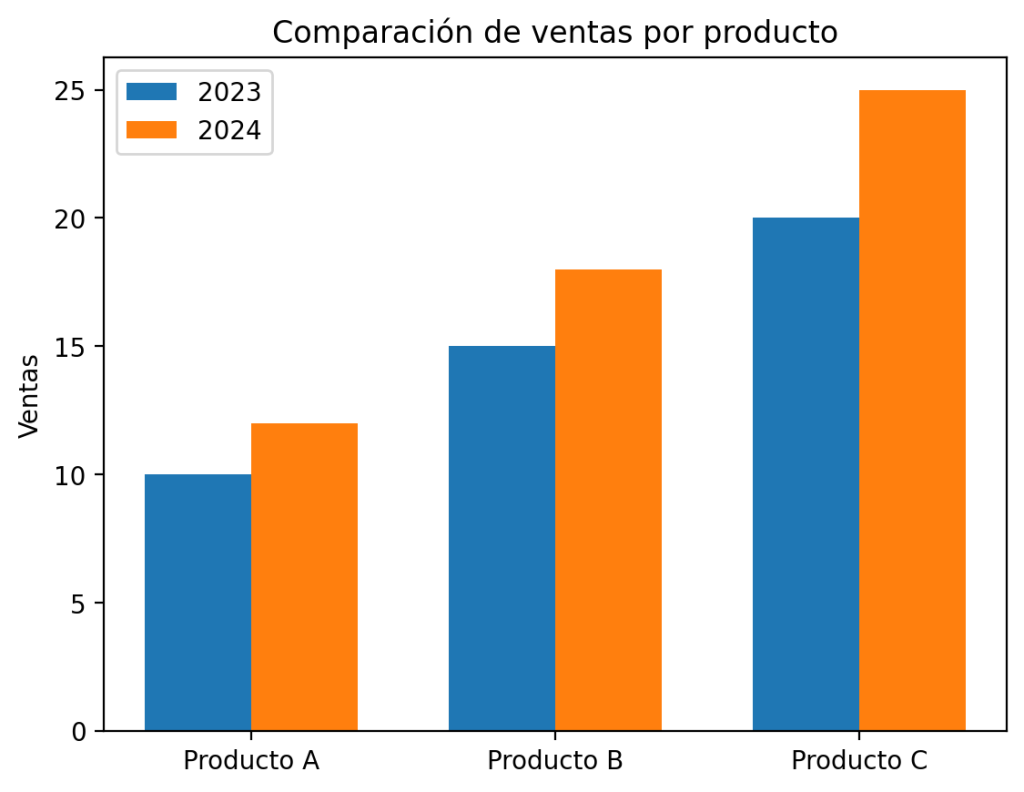
Vamos a entender exactamente qué hace cada parte de este código:
x = np.arange(len(categorias)): Genera el array[0, 1, 2]. Cada número representa la posición central de un grupo de barras en el eje X.width = 0.35: Controla el ancho de cada barra individual. Un valor entre0.25y0.4suele funcionar bien. Si lo haces demasiado grande las barras se solaparán; si es demasiado pequeño, el gráfico quedará lleno de espacio vacío.x - width/2yx + width/2: Aquí está la clave. En lugar de dibujar ambas barras en la posiciónx, desplazamos la primera hacia la izquierda (-width/2) y la segunda hacia la derecha (+width/2). El resultado es que las dos barras quedan centradas alrededor de cada posición, sin solaparse.plt.xticks(x, categorias): Como el eje X contiene números (0, 1, 2), esta línea los sustituye por las etiquetas de texto originales. Sin esto, el gráfico mostraría0,1,2en lugar de los nombres de los productos.
Escalando a tres o más series
En análisis real es frecuente trabajar con más de dos grupos. Supongamos ahora tres años:
ventas_2022 = [8, 12, 18]
ventas_2023 = [10, 15, 20]
ventas_2024 = [12, 18, 25]
x = np.arange(len(categorias))
width = 0.25 # Reducimos el ancho para que quepan tres barras
plt.bar(x - width, ventas_2022, width, label='2022')
plt.bar(x, ventas_2023, width, label='2023')
plt.bar(x + width, ventas_2024, width, label='2024')
plt.xticks(x, categorias)
plt.legend()
plt.title("Comparación multianual")
plt.show()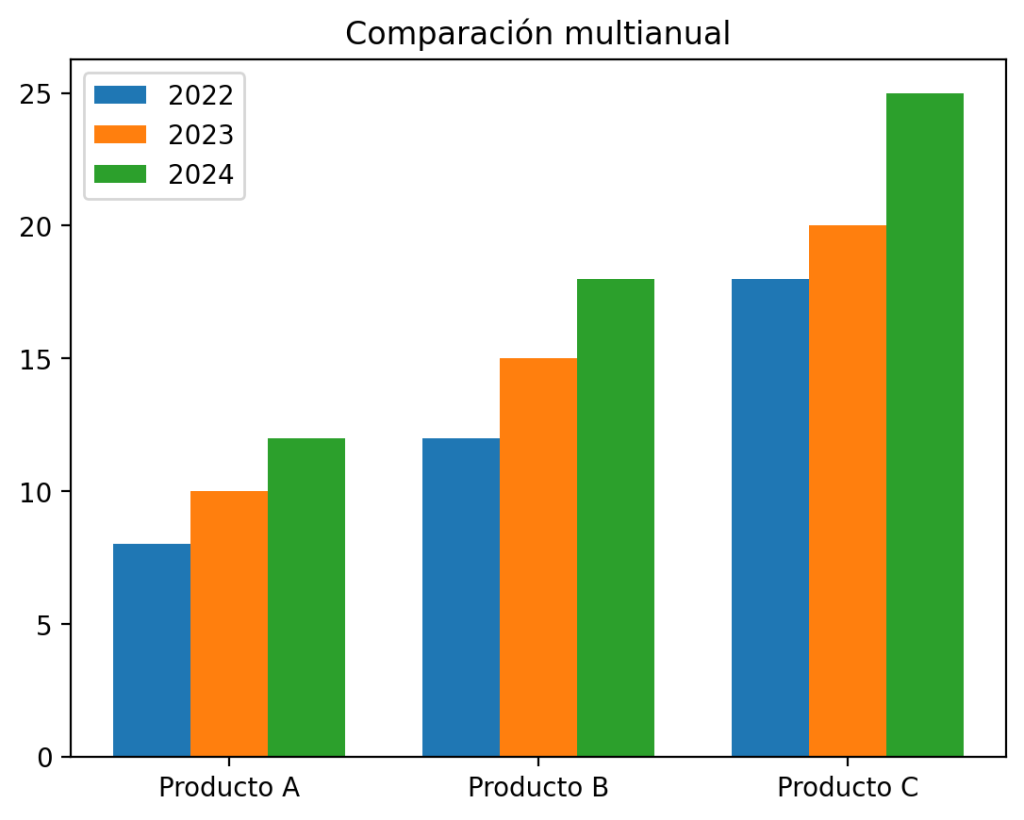
Observa que al añadir una tercera barra hemos tenido que reducir el width a 0.25 para que las tres quepan. La barra central permanece en x, y las otras dos se desplazan simétricamente.
Advertencia: a partir de 4 o 5 grupos, las barras agrupadas se vuelven difíciles de leer. Si tienes muchas series, considera usar líneas temporales, heatmaps o dividir el análisis en varios gráficos. Más información no siempre es mejor visualización.
Gráficos de barras apiladas (Stacked Bar Charts)
Las barras apiladas son ideales cuando lo que te importa no es comparar los valores entre sí, sino ver cómo varias partes componen un total. Por ejemplo:
- Desglose de ingresos por línea de producto.
- Tiempo invertido en distintas tareas durante la semana.
- Contribución de cada departamento al presupuesto total.
Implementación básica
La clave aquí es el parámetro bottom. Este parámetro le indica a Matplotlib desde qué altura debe empezar a dibujar la siguiente barra. Sin él, todas las barras empezarían desde cero y se solaparían.
categorias = ['Producto A', 'Producto B', 'Producto C']
ventas_2023 = [10, 15, 20]
ventas_2024 = [12, 18, 25]
plt.bar(categorias, ventas_2023, label='2023')
plt.bar(categorias, ventas_2024, bottom=ventas_2023, label='2024')
plt.legend()
plt.title("Barras apiladas: ventas acumuladas")
plt.ylabel("Ventas totales")
plt.show()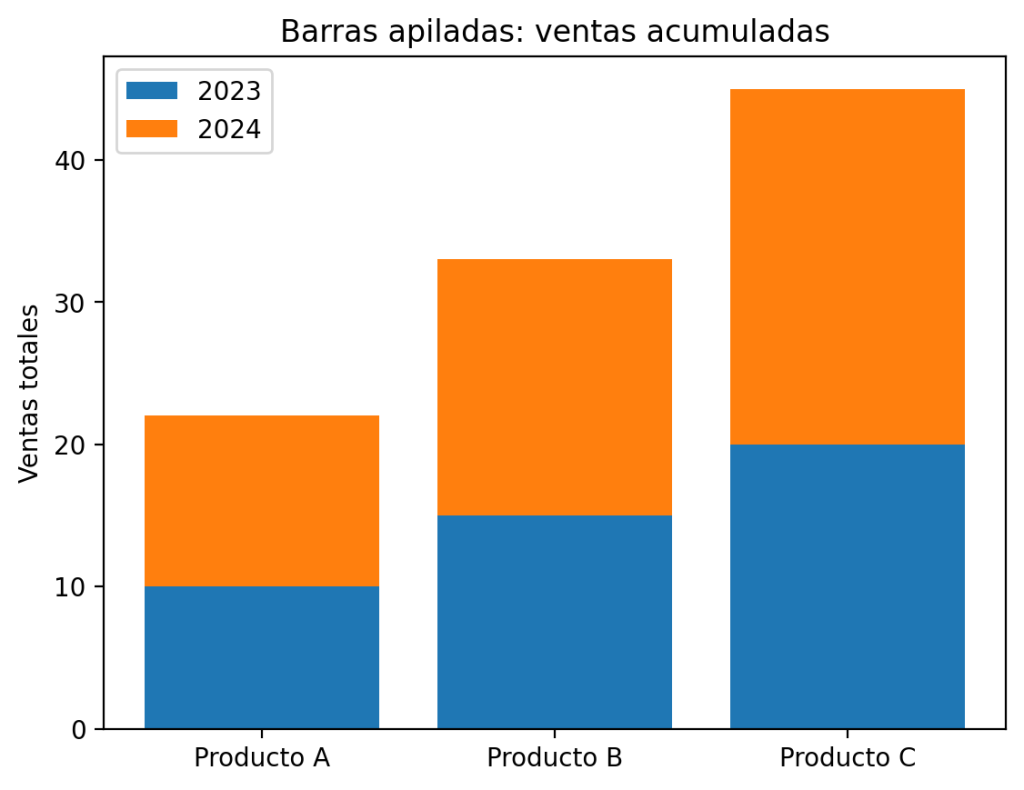
En este caso, la barra de 2023 forma la base y la de 2024 se apila encima. El alto total de cada barra representa la suma de ambos años, lo que permite ver rápidamente qué producto tiene mayor volumen acumulado.
Apilando tres o más series
Para apilar tres series, simplemente acumulamos los bottom de forma progresiva:
ventas_2022 = np.array([8, 12, 18])
ventas_2023 = np.array([10, 15, 20])
ventas_2024 = np.array([12, 18, 25])
plt.bar(categorias, ventas_2022, label='2022')
plt.bar(categorias, ventas_2023, bottom=ventas_2022, label='2023')
plt.bar(categorias, ventas_2024, bottom=ventas_2022 + ventas_2023, label='2024')
plt.legend()
plt.title("Barras apiladas con tres series")
plt.show()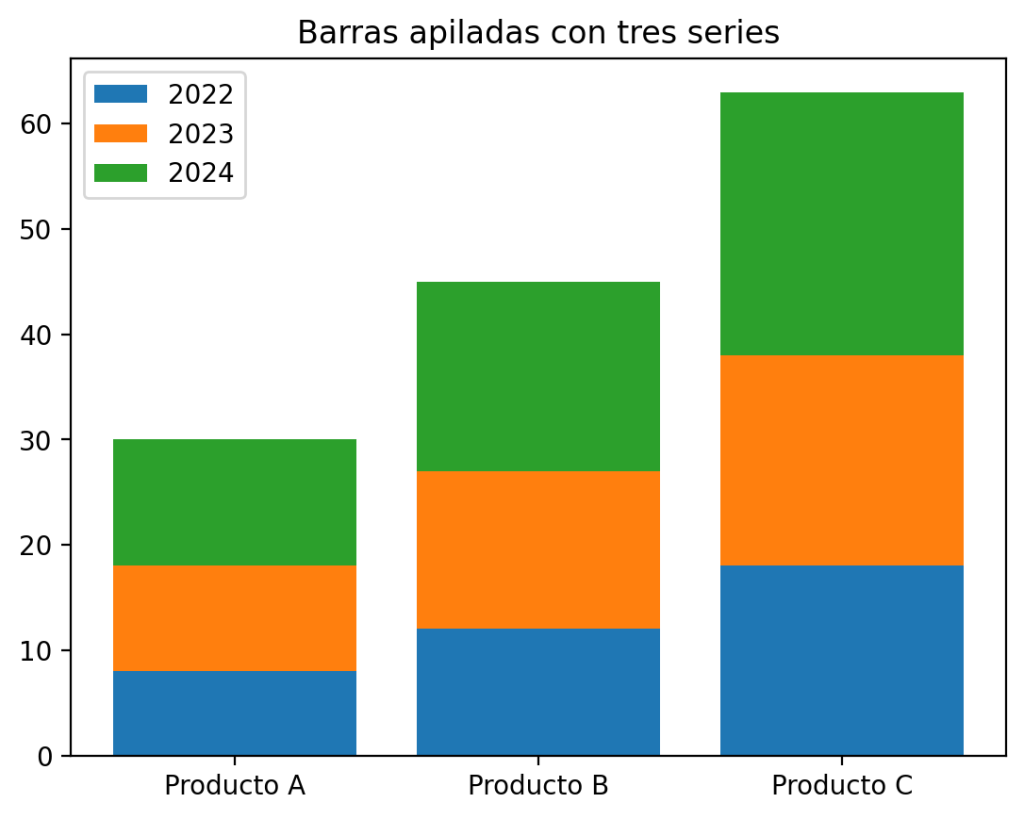
Es importante usar np.array en lugar de listas de Python para poder sumar los arrays directamente con el operador +.
Error frecuente: usar barras apiladas cuando en realidad quieres comparar. Si tu pregunta es “¿cuánto vendió el Producto A en 2023 frente a 2024?”, las barras apiladas no te ayudan, porque la segunda barra no empieza en cero. Para comparación directa, usa siempre barras agrupadas.
Comparación porcentual (barras normalizadas)
A veces los valores absolutos distorsionan la imagen. Imagina que el Producto A vende 100 unidades y el Producto B vende 10.000. Si los representas juntos con barras apiladas, la contribución de A quedará casi invisible aunque sea importante en términos relativos.
La normalización soluciona esto: convierte los valores a porcentaje sobre el total, de forma que todas las barras alcanzan exactamente el 100 %. Esto permite comparar la estructura interna de cada categoría independientemente de su tamaño.
Implementación paso a paso
import numpy as np
import matplotlib.pyplot as plt
categorias = ['Producto A', 'Producto B', 'Producto C']
ventas_2023 = np.array([10, 15, 20])
ventas_2024 = np.array([12, 18, 25])
# Calcular el total por producto
total = ventas_2023 + ventas_2024
# Convertir a porcentaje
ventas_2023_pct = ventas_2023 / total * 100
ventas_2024_pct = ventas_2024 / total * 100
# Dibujar el gráfico apilado porcentual
plt.bar(categorias, ventas_2023_pct, label='2023')
plt.bar(categorias, ventas_2024_pct, bottom=ventas_2023_pct, label='2024')
plt.ylabel('%')
plt.ylim(0, 100)
plt.title("Distribución porcentual de ventas por producto")
plt.legend()
plt.show()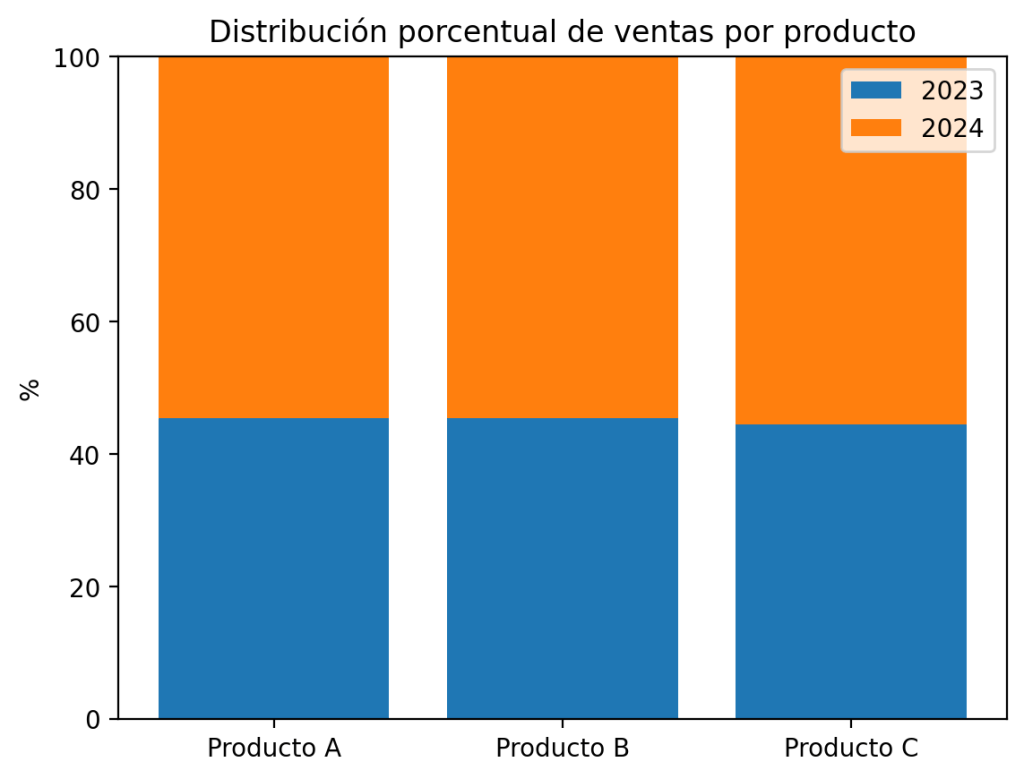
Ahora todas las barras llegan al 100 % y puedes ver fácilmente si el peso relativo de cada año ha cambiado entre productos, independientemente de cuántas unidades vendieron.
Mejoras estéticas para gráficos más legibles
Un gráfico correcto técnicamente puede ser difícil de interpretar si no cuida la presentación. Estas son las mejoras más efectivas:
Estilo base
plt.style.use('seaborn-v0_8')Este estilo añade un fondo limpio y colores predefinidos más suaves que los del estilo por defecto de Matplotlib.
Cuadrícula horizontal
plt.grid(axis='y', linestyle='--', alpha=0.7)
Una cuadrícula en el eje Y ayuda al ojo a estimar valores sin sobrecargar el gráfico. El parámetro alpha=0.7 la hace semitransparente para que no compita con los datos.
Rotación de etiquetas
plt.xticks(rotation=45, ha='right')
Cuando los nombres de categoría son largos, rotarlos 45 grados evita que se solapen. El ha='right' (horizontal alignment) asegura que el texto quede bien alineado bajo su barra.
Colores personalizados
colores = ['steelblue', 'darkorange', 'seagreen'] plt.bar(x, ventas_2023, color=colores[0]) plt.bar(x, ventas_2024, color=colores[1])
Elegir colores con buen contraste mejora la legibilidad, especialmente para lectores con daltonismo. Paletas como tab10 o Set2 de Matplotlib son buenas opciones accesibles.
Añadir etiquetas de valor sobre las barras
for i, v in enumerate(ventas_2023):
plt.text(i - width/2, v + 0.3, str(v), ha='center', fontsize=9)Mostrar el valor exacto encima de cada barra elimina la necesidad de que el lector estime mirando el eje, lo que hace el gráfico más autónomo.
Errores comunes y cómo evitarlos
Antes de ver el ejemplo final, conviene revisar los errores más frecuentes al construir este tipo de gráficos:
- No usar
np.arangepara las posiciones: Si intentas pasar listas de texto directamente aplt.bar()con desplazamientos, Matplotlib no sabrá cómo calcular las posiciones y las barras se solaparán o darán error. Siempre convierte a posiciones numéricas primero. - Ancho de barra (
width) mal ajustado: Con dos series ywidth=0.5, las barras se tocan o se superponen. Conwidth=0.1, quedan demasiado delgadas y el gráfico parece vacío. Ajusta el ancho en función del número de series: divide el espacio disponible (~0.8 unidades) entre el número de barras por grupo. - Demasiadas series en el mismo gráfico: A partir de 4–5 grupos distintos, las barras agrupadas se vuelven ilegibles. En ese caso es mejor usar líneas, pequeños múltiplos (small multiples) o un heatmap.
- Mezclar barras apiladas y comparación directa: Recuerda que en las barras apiladas la segunda barra no empieza en cero, lo que hace imposible comparar su altura con la primera. Si necesitas comparar magnitudes, usa siempre barras agrupadas.
- Olvidar normalizar en análisis porcentual: Si tus categorías tienen tamaños muy distintos y quieres comparar proporciones, trabajar con valores absolutos puede llevar a conclusiones erróneas. Normaliza siempre antes de representar proporciones.
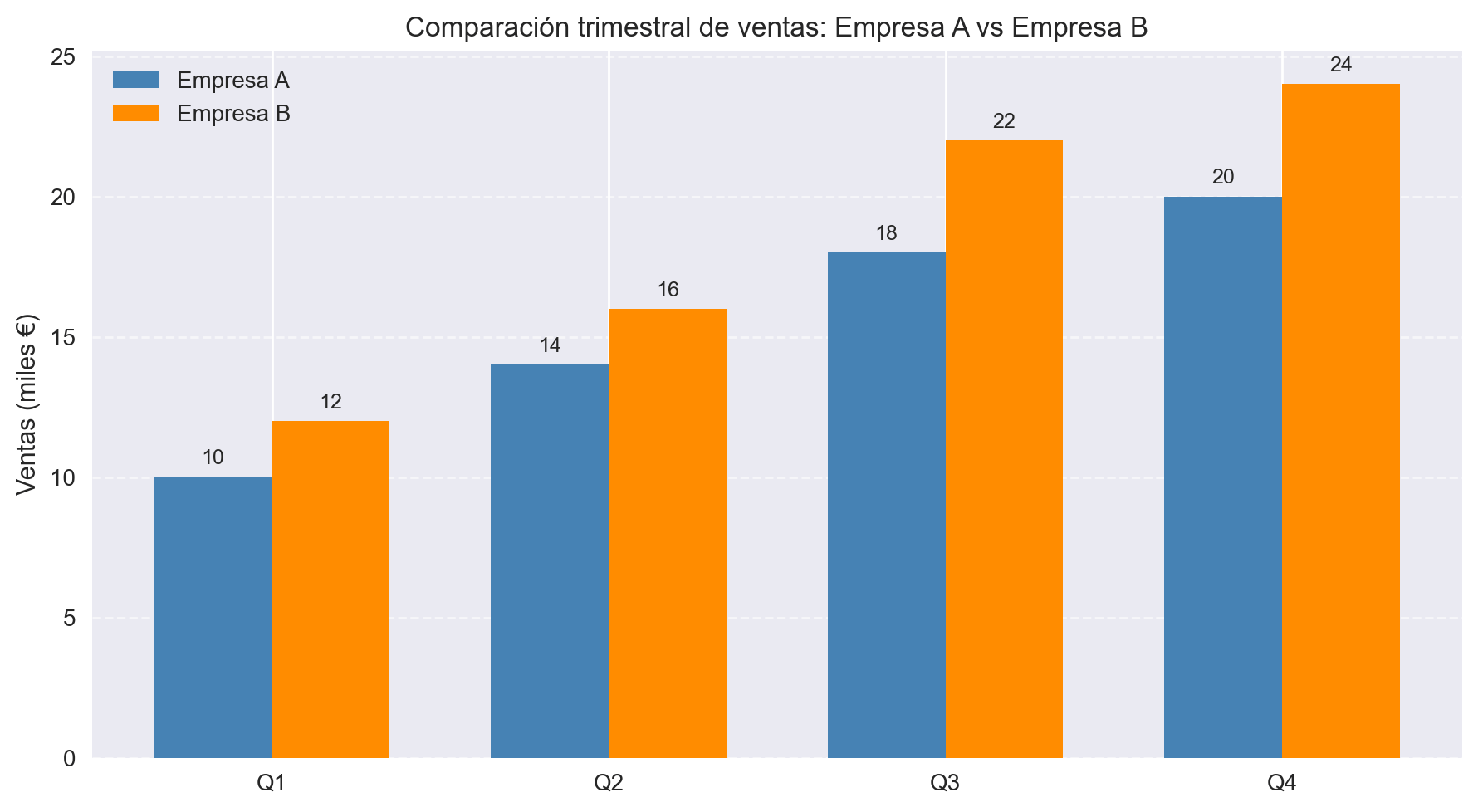
Caso práctico completo
Pongamos todo junto en un ejemplo realista: comparar las ventas trimestrales de dos empresas con un gráfico bien presentado.
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('seaborn-v0_8')
categorias = ['Q1', 'Q2', 'Q3', 'Q4']
empresa_a = [10, 14, 18, 20]
empresa_b = [12, 16, 22, 24]
x = np.arange(len(categorias))
width = 0.35
fig, ax = plt.subplots(figsize=(9, 5))
bars_a = ax.bar(x - width/2, empresa_a, width, label='Empresa A', color='steelblue')
bars_b = ax.bar(x + width/2, empresa_b, width, label='Empresa B', color='darkorange')
# Etiquetas de valor
for bar in bars_a:
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.3,
str(int(bar.get_height())), ha='center', va='bottom', fontsize=9)
for bar in bars_b:
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.3,
str(int(bar.get_height())), ha='center', va='bottom', fontsize=9)
ax.set_xticks(x)
ax.set_xticklabels(categorias)
ax.set_ylabel('Ventas (miles €)')
ax.set_title('Comparación trimestral de ventas: Empresa A vs Empresa B')
ax.legend()
ax.grid(axis='y', linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()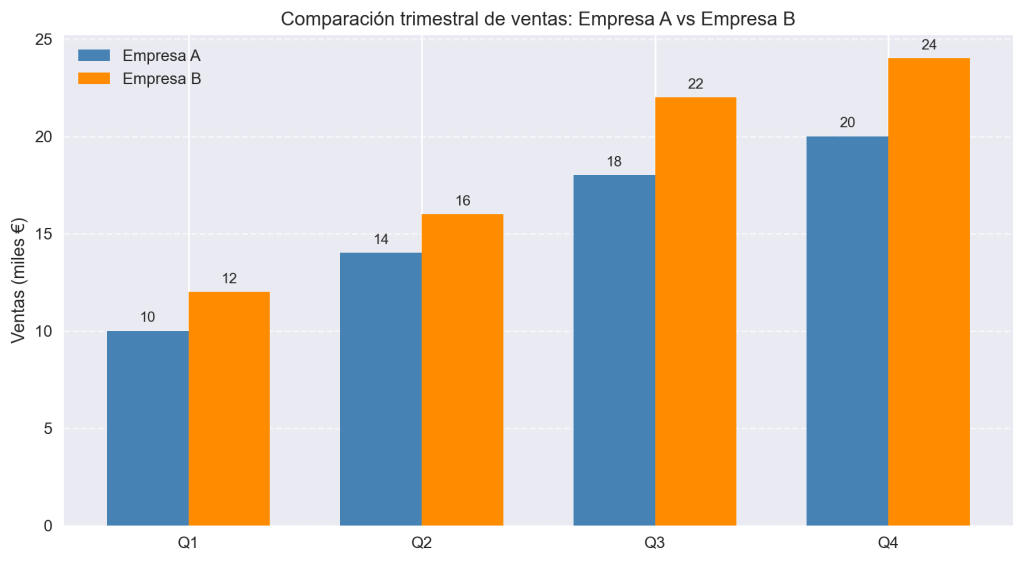
El uso de fig, ax = plt.subplots() es la forma recomendada de trabajar en Matplotlib cuando se quiere un control más preciso del gráfico. El objeto ax expone los mismos métodos que plt, pero es más explícito y facilita la creación de múltiples subgráficos en el futuro.
Resumen: ¿cuándo usar cada tipo de gráfico?
| Tipo | Úsalo cuando quieras… | Limitación principal |
|---|---|---|
| Barras agrupadas | Comparar valores directamente entre grupos | Difícil de leer con más de 4 series |
| Barras apiladas | Ver la composición y el total acumulado | No permite comparar partes entre categorías |
| Barras porcentuales | Analizar proporciones eliminando el tamaño absoluto | Pierdes información sobre los valores reales |
Conclusiones
Los gráficos de barras comparativos son una de las herramientas más versátiles del análisis de datos. Con Matplotlib puedes construir desde una comparación directa entre dos grupos hasta un análisis porcentual multiserie, siempre que entiendas bien el mecanismo de posicionamiento y elijas el tipo de gráfico adecuado para tu pregunta.
La regla de oro es simple: antes de escribir el código, pregúntate qué quieres que el lector vea. ¿Una diferencia? Usa barras agrupadas. ¿Una composición? Apílalas. ¿Una proporción? Normaliza. El tipo de gráfico es siempre una consecuencia de la pregunta analítica, nunca al revés.
Deja una respuesta