
Es muy probable que la mayoría de los lectores tengan experiencia con las tablas dinámicas de Excel. Estas son un tipo especial de tablas en las que es posible resumir de forma dinámica el contenido de hojas calculo. A la hora de su definición es posible indicar los campos a utilizar como columna, como fila y los estadísticos que se mostraran en estas. Otro nombre por el que también se hace referencia a las tablas dinámicas es llame tablas pivote, debido a su nombre en inglés: “Pivot tables”. En Python pandas proporciona una función con la que se pueden conseguir los mismos resultados llamada pivot_table. Esta función, al igual que en Excel, es extremadamente útil para resumir conjuntos de datos de una forma rápida y eficaz. Veamos a continuación cómo aplicar esta función a un dataframe con la que se pueden construir tablas dinámicas en Python con pandas.
Importación del conjunto de datos
Antes de poder utilizar la función pivot_table para construir una tabla dinámica es necesario disponer de un conjunto de datos. En esta ocasión se puede importar el conjunto de datos de supervivencia del Titanic que se encuentra en la librería Seaborn. El proceso de importación se muestra en el siguiente código.
import numpy as np
import pandas as pd
import seaborn as sns
titanic = sns.load_dataset('titanic')Operaciones básicas con tablas dinámicas en Python
En el conjunto de datos una primera pregunta puede ser cuál es el porcentaje de los pasajeros en función de su clase. Esta pregunta se puede responder rápidamente mediante el uso de la función pivot_table. Para ello simplemente se ha de indicar que agrupe los valores de la columna survived en función de la columna clase class.

titanic.pivot_table('survived', 'class')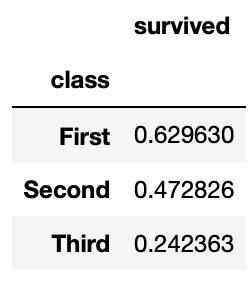
El resultado muestra los porcentajes de supervivencia por clase, pero puede que sea más interesante obtener el total. Para ello es necesario cambiar la función de agregación. Esto se puede indicar mediante el parámetro aggfunc, al que se le ha de pasar la función de agregación.
titanic.pivot_table('survived', 'class', aggfunc=np.sum)
Utilización de valores en columnas
Una posibilidad que aumenta las posibilidades de las tablas dinámicas es la posibilidad de separar los resultados en columnas. Para ello a la función se le ha de indicar una segunda columna del dataframe como segundo criterio de agrupación. A modo de ejemplo se puede ver la probabilidad de supervivencia por clase y género en el siguiente código.
titanic.pivot_table('survived', ['sex', 'alone'], 'class')
Múltiples criterios de agrupación en columnas y filas
Es posible utilizar más de un criterio de agrupación tanto en las filas como en las columnas de las tablas dinámicas. Para ello en lugar de indicar una única columna se ha de utilizar un vector. Siguiendo con el ejemplo, se puede separar el género en función de si viajaban solos o no para obtener la probabilidad de supervivencia.
titanic.pivot_table('survived', ['sex', 'alone'], 'class')
Por otro lado, en la clase se puede agregar el puerto de embarque.
titanic.pivot_table('survived',
['sex', 'alone'],
['embark_town', 'class'])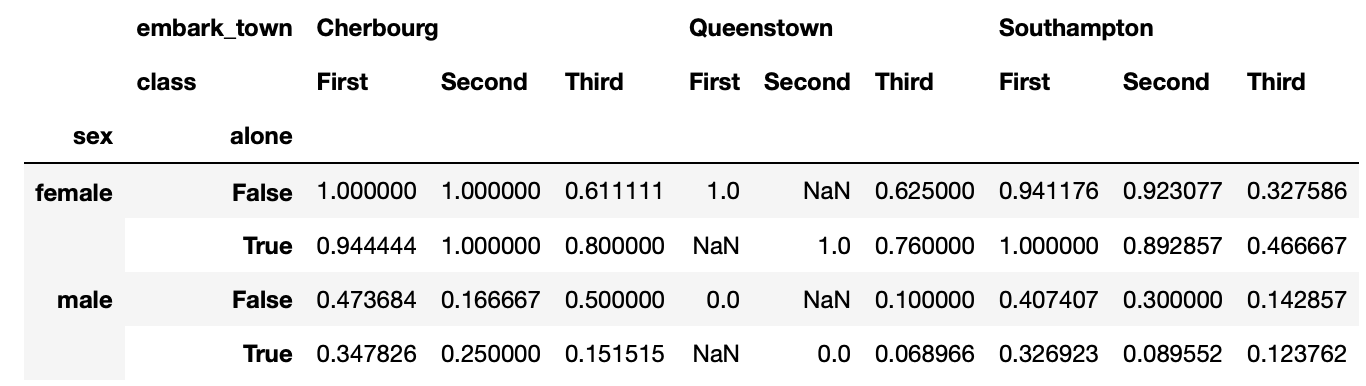
Múltiples funciones de agregación
No solo se pueden utilizar múltiples columnas, sino que es posible obtener a la vez los resultados para diferentes funciones de agregación. Para ello al parámetro aggfunc se le ha de agregar un diccionario en el que la clave sea la columna sobre la que se realiza la operación y el valor la función. Por ejemplo, se puede obtener a la vez el número de supervivientes y porcentaje de la tarifa pagada.
titanic.pivot_table(index='sex', columns='class',
aggfunc={'survived': np.sum,
'fare': np.mean})
Conclusiones
Las tablas dinámicas o tablas pivote son una herramienta extremadamente útil en tareas de análisis de datos. Muchos usuarios conocen su utilidad después de haberlas utilizado en Excel. Conocer que pandas suministra estas funciones y saber utilizarlas es clave para mejorar los flujos de trabajo.
Imágenes: Pixabay (Free-Photos)
Excelente trabajo.
Muy util.
No me ha reconocido la funciónaggfunc=np.sum, modificando la función, si que ha funcionado: aggfunc=sum
Deberían funcionar las dos opciones. Lo único que se me ocurre es que no este importado numpy o no se use el alias de np.
Como puede agregarse una columna calculada en la tabla pívot?
Por ejemplo una columna si el superviviente es de Quennstown y además es de segunda clase asignar valor 1 y 0 en cualquier otro caso.
Las tablas pívot son para agrupar la información, lo que se plantea es una simple creación de variables que se puede hacer creando una nueva columna en el DataFrame.
titanic['new'][(titanic.survived == 1) & (titanic.embark_town == 'Southampton') & (titanic.pclass == 2)] = 1Saludos, gracias por el aporte. Pero si quisiera hace un cálculo o crear una nueva columna a partir de un cálculo de los datos de dos columnas del pivot table, es factible?
Si, al final el resultado no es más que un nuevo DataFrame sobre el que se puede continuar trabajando y realizar nuevas operaciones.
Perfecto Daniel. Mil gracias por la respuesta!!!
Pensé que se podía continuar trabajando con la tabla pivot como un DataFrame en sí mismo.
Si que se puede continuar trabajando con la tabla pivot como un DataFrame, pero al ser un resumen de los datos originales ya no esta disponible toda la información original.
Muchas gracias por la información, pero al exportar la tabla pivot a excel, la columna index no se imprime, me pudieran ayudar.
saludos.
Los índices en estas tablas son las variables por las que se han agregado los datos, lo que se puede comprobar mediante la propiedad
indexdel objeto. Si se usa el métodoto_excelestos salen por defecto. No sé si lo que esperaba son los típicos números de los DataFrame, en este caso no saldrán porque los índices no necesariamente son valores numéricos.Buenas tardes, tengo una consulta y es que los datos de la tabla pivot en la columna salen alineados al centro y quisiera alinearlos ya sea a la derecha o izquierda, de antemano gracias.
Tendrás que jugar con los estilos de visualización de los dataframes, por ejemplo, para alinear el contenido al la izquierda de puede usar algo como
df.style.set_properties(**{'text-align': 'left'})