Al trabajar con conjuntos de datos complejos, a menudo puede ser necesario explorar las relaciones entre las variables de tipo categóricas y continuas. Por ejemplo:Generalmente, la representación de este tipo de relaciones en un único gráfico puede ser algo confuso y poco claro. Siendo en estos casos donde la clase FacetGrid de Seaborn se convierte en una herramienta … [Leer más...] acerca de Combinar gráficos con FacetGrid: Cómo analizar tendencias complejas en múltiples paneles con Seaborn
Seaborn
Anotaciones en gráficos de correlación en Seaborn: Mejorando la interpretación con etiquetas
Los gráficos de correlación son herramientas esenciales para identificar y visualizar las relaciones entre las variables de un conjunto de datos. Estos gráficos permiten representar correlaciones positivas, negativas e incluso nulas, utilizando escalas de colores para facilitar la interpretación general. Por esta razón, a menudo también se les conoce como mapas de calor.Sin … [Leer más...] acerca de Anotaciones en gráficos de correlación en Seaborn: Mejorando la interpretación con etiquetas
Visualización de datos con Pyjanitor y Matplotlib o Seaborn: Potenciando el análisis visual

La visualización de datos es una parte clave del análisis de datos y comunicación de los resultados. Facilitando la comprensión de patrones, identificación de tendencias y comunicación de hallazgos de una manera más sencilla y efectiva que solamente estadísticas. En esta cuarta y última entrega la serie dedicada a Pyjanitor se explicará cómo se puede combinar con bibliotecas … [Leer más...] acerca de Visualización de datos con Pyjanitor y Matplotlib o Seaborn: Potenciando el análisis visual
Creación de Ridge Plots en Python con Seaborn: Guía completa paso a paso
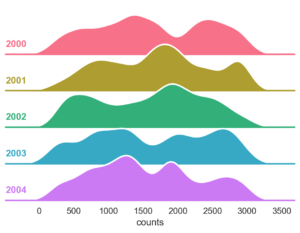
Una de las mejores opciones para poder visualizar la forma de la distribución de un conjunto de datos son los gráficos de densidad (KDE, Kernel Density Estimation). Especialmente cuando se desconoce la distribución subyacente. Si, además, para un conjunto de datos, se desea analizar cómo evoluciona la distribución a lo largo de una dimensión categórica, como puede ser el tiempo … [Leer más...] acerca de Creación de Ridge Plots en Python con Seaborn: Guía completa paso a paso
Serie especial verano 2023 sobre Seaborn

Ayer finalizó la serie especial de publicaciones para el verano de 2023 de Analytics Lane en la que se han repasado las principales funcionalidades de Seaborn. Esta serie continúa la tradición instaurada en 2020 con una serie sobre el lenguaje de programación Julia. Para continuar en 2021 con una serie sobre NumPy y Pandas y en 2022 con una serie sobre Matplotlib.Listado de … [Leer más...] acerca de Serie especial verano 2023 sobre Seaborn
Trucos y consejos para optimizar la velocidad en Seaborn
Seaborn es una de las bibliotecas más populares para la visualización de datos en Python. A pesar de esto, en ocasiones, especialmente cuando se trabaja con conjuntos de datos grandes, puede que la generación de los gráficos sea un proceso lento. Para solucionar este problema cuando aparece existen ciertos trucos y consejos para optimizar la velocidad en Seaborn. En esta … [Leer más...] acerca de Trucos y consejos para optimizar la velocidad en Seaborn
Combinar diferentes tipos de gráficos en Seaborn
Seaborn es una biblioteca para la visualización de datos en Python que cuenta con una gran variedad de tipos de gráficos predefinidos. Ofreciendo de esta forma una manera rápida y sencilla para crear representaciones de los datos. Algo que se potencia aún más con la capacidad que tiene para combinar diferentes tipos de gráficos en una sola figura, lo que permite crear gráficas … [Leer más...] acerca de Combinar diferentes tipos de gráficos en Seaborn
Cómo crear gráficos múltiples en Seaborn
Los gráficos múltiples, también conocidos por su nombre en inglés subplots, son una forma efectiva para mostrar múltiples visualizaciones de datos en una misma figura. Permitiendo ver al mismo tiempo más de un tipo de dato o tendencia. La mayoría de las bibliotecas de visualización de datos incluye funciones y métodos para esto, lo que no es una excepción en el caso de Seaborn. … [Leer más...] acerca de Cómo crear gráficos múltiples en Seaborn
Trabajar con datos faltantes con Seaborn
Los datos faltantes son un desafío a la hora de realizar casi cualquier análisis de datos. Si no se tiene en cuenta la falta de valores en algunos registros pueden aparecer sesgos en los resultados y una reducción de la precisión de los estadísticos. Lo que dificulta la interpretación de los resultados. Por eso es importante identificar la presencia de estos registros en los … [Leer más...] acerca de Trabajar con datos faltantes con Seaborn
Creación de gráficos de residuos en Seaborn para análisis de regresión
El análisis de los residuos es una parte clave para evaluar la calidad del ajuste en los modelos de regresión. Permitiendo verificar si se cumplen las condiciones subyacentes de estos modelos. Seaborn, una de las principales bibliotecas para la visualización de datos en Python, cuenta con funciones para facilitar la creación de gráficos de residuos de una forma rápida y fácil. … [Leer más...] acerca de Creación de gráficos de residuos en Seaborn para análisis de regresión
Gráficos de contorno en Seaborn: Representación de distribuciones conjuntas y estimaciones de densidad
Los gráficos de contorno permiten visualizar la distribución conjunta de dos variables. Facilitando estimar la densidad de los valores. Seaborn, una de las principales bibliotecas para la visualización de datos en Python, dispone de funciones con las que se pueden crear este tipo de gráficos de una forma sencilla. En esta entrada, se verá cómo crear gráficos de contorno en … [Leer más...] acerca de Gráficos de contorno en Seaborn: Representación de distribuciones conjuntas y estimaciones de densidad
Análisis de outliers en Seaborn: Cómo identificar y visualizar valores atípicos
Los valores atípicos u outliers de un conjunto de datos son aquellos registros que se alejan de forma significativa de los demás puntos. Identificar estos valores es crucial para un correcto análisis de datos. No conocer ni comprender los outliers de un conjunto de datos puede llevar a conclusiones erróneas durante los análisis de datos, ya que su presencia afecta a los … [Leer más...] acerca de Análisis de outliers en Seaborn: Cómo identificar y visualizar valores atípicos