
El algoritmo de regresión logística es uno de los más utilizados actualmente en aprendizaje automático. Siendo su principal aplicación los problemas de clasificación binaria. Es un algoritmo simple en el que se pueden interpretar fácilmente los resultados obtenidos e identificar por qué se obtiene un resultado u otro. A pesar de su simplicidad funciona realmente bien en muchas aplicaciones y se utiliza como referencia de rendimiento. Por lo tanto, este es un algoritmo con el que los científicos de datos han de estar familiarizados. Ya que comprender los conceptos básicos de la regresión logística son útiles para la entender de otras técnicas más avanzadas.
¿Qué es la regresión logística?
La regresión logística es una técnica de aprendizaje automático que proviene del campo de la estadística. A pesar de su nombre no es un algoritmo para aplicar en problemas de regresión, en los que se busca un valor continuo, sino que es un método para problemas de clasificación, en los que se obtienen un valor binario entre 0 y 1. Por ejemplo, un problema de clasificación es identificar si una operación dada es fraudulenta o no. Asociándole una etiqueta “fraude” a unos registros y “no fraude” a otros. Simplificando mucho es identificar si al realizar una afirmación sobre registro esta es cierta o no.

Con la regresión logística se mide la relación entre la variable dependiente, la afirmación que se desea predecir, con una o más variables independientes, el conjunto de características disponibles para el modelo. Para ello utiliza una función logística que determina la probabilidad de la variable dependiente. Como se ha comentado anteriormente, lo que se busca en estos problemas es una clasificación, por lo que la probabilidad se ha de traducir en valores binarios. Para lo que se utiliza un valor umbral. Los valores de probabilidad por encima del valor umbral la afirmación es cierta y por debajo es falsa. Generalmente este valor es 0,5, aunque se puede aumentar o reducir para gestionar el número de falsos positivos o falsos negativos.
Formulación matemática de la función logística
A la función que relaciona la variable dependiente con las independientes también se le llama función sigmoidea. La función sigmoidea es una curva en forma de S que puede tomar cualquier valor entre 0 y 1, pero nunca valores fuera de estos límites. La ecuación que define la función sigmoidea es
f(x) = \frac{1}{1 + e^{-x}}donde x es un número real. En la ecuación se puede ver que cuando x tiene a menos infinito el cociente tiende a cero. Por otro lado, cuando x tiende a infinito el cociente tiende a la unidad. En la siguiente figura se muestra una representación gráfica de la función logística (función sigmoide).
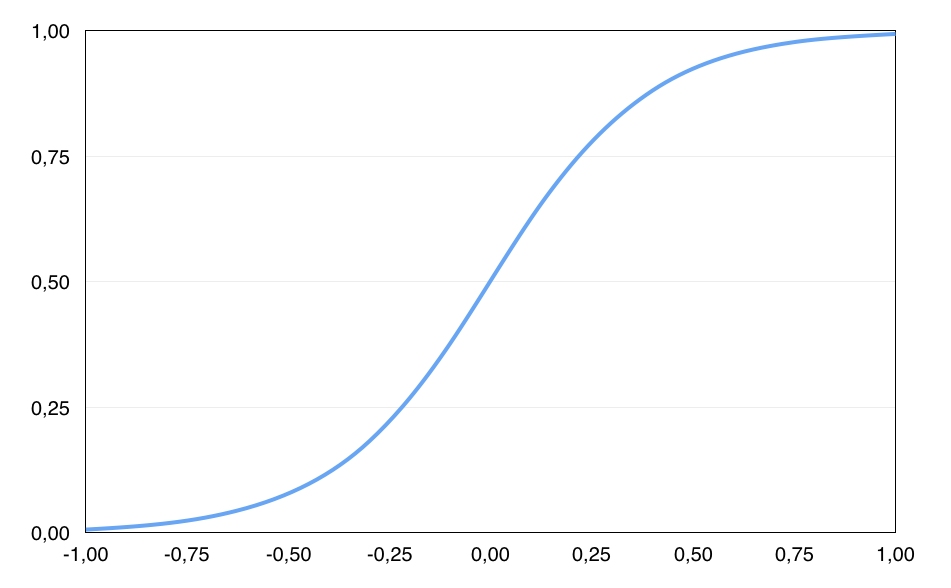
El proceso de entrenamiento de una función logística se puede realizar maximizando la probabilidad de que los puntos de un conjunto de datos clasifiquen correctamente. Lo que se conoce como estimación de máxima verosimilitud. La estimación de máxima verisimilitud es un enfoque genérico para la estimación de parámetros en modelos estadísticos. La maximización se puede realizar utilizando diferentes métodos de optimización como el descenso de gradiente.
Ventajas de la regresión logística
La regresión logística es una técnica muy empleada por los científicos de datos debido a su eficacia y simplicidad. No es necesario disponer de grandes recursos computacionales, tanto en entrenamiento como en ejecución. Además, los resultados son altamente interpretables. Siendo esta una de sus principales ventajas respecto a otras técnicas. El peso de cada una de las características determina la importancia que tiene en la decisión final. Por lo tanto, se puede afirmar que el modelo ha tomado una decisión u otra en base a la existencia de una u otra característica en el registro. Lo que en muchas aplicaciones es altamente deseado además del modelo en sí.
El funcionamiento de la regresión logística, al igual que la regresión lineal, es mejor cuando se utilizan atributos relacionados con la de salida. Eliminado aquellos que no lo están. También es importante eliminar las características que muestran una gran multicolinealidad entre sí. Por lo que la selección de las características previa al entrenamiento del modelo es clave. Siendo aplicables las técnicas de ingeniería de características también utilizadas en la regresión lineal.
Desventajas de la regresión logística
En cuanto a sus desventajas se encuentra la imposibilidad de resolver directamente problemas no lineales. Esto es así porque la expresión que toma la decisión es lineal. Por ejemplo, en el caso de que la probabilidad de una clase se reduzca inicialmente con una característica y posteriormente suba no puede ser registrado con un modelo logístico directamente. Siendo necesario transforma esta característica previamente para que el modelo puede registrar este comportamiento no lineal. En estos casos es mejor utilizar otros modelos como los árboles de decisión.
Una cuestión importante es que la variable objetivo esta ha de ser linealmente separable. En caso contrario el modelo de regresión logística no clasificará correctamente. Es decir, en los datos han de existir dos “regiones” con una frontera lineal.
Otra desventaja es la dependencia que muestra en las características. Ya que no es una herramienta útil para identificar las características más adecuadas. Siendo necesario identificar estas mediante otros métodos
Finalmente, la regresión logística tampoco es uno de los algoritmos más potentes que existen. Pudiendo ser superado fácilmente por otros más complejos.
Regresión logística en clasificación con múltiples clases
En aprendizaje automático hay clarificadores que pueden trabajar con múltiples clases, como los Árboles de Decisión o Random Forest. Por otro lado, existen otros que no, como la Regresión Logística. Pero siempre es posible utilizar trucos para utilizar la regresión logística en problemas de clasificación con múltiples clases. Algunos de los trucos que se pueden utilizar son:
- Uno contra todos (one-vs.-all, OvA). En esta estrategia se ha de entrenar tantos clasificadores binarios como clases existan en el conjunto de datos. Cada uno de los modelos predice la probabilidad de que el registro pertenezca a una clase. A la hora de realizar una predicción se ejecutan todos los clasificadores y se selecciona aquel que ofrece mayor probabilidad.
- Uno contra uno (one-vs.-one, OvO). En esta estrategia se crean tantos modelos como pares de posibles resultados existan. Es decir, se han de entrenar (N^2 -N)/2 modelos, donde N es el número de posibles clases. Esto es, un clasificador decidirá solamente entre dos posibles resultados. Al igual que en el caso anterior, a la hora de realizar una predicción se ejecutan todos los clasificadores y se selecciona aquel que ofrece mayor probabilidad.
Conclusiones
En esta entrada se ha presentado las bases de la regresión logística y su funcionamiento. Posteriormente se han descrito sus principales ventajas y desventajas. Entre sus ventajas se puede destacar su simplicidad y que sus resultados son fácilmente interpretables. Por otro lado, entre sus desventajas se puede destacar que no funciona bien en problemas que no son linealmente separables. Además, se ha presentado las técnicas que se pueden utilizar para utilizar la regresión logística en problemas de clasificación con múltiples clases.
Deja una respuesta