
Pandas es una biblioteca para la manipulación y el análisis de datos en el lenguaje de programación Python. Siendo una de las librerías mas utilizadas por los científicos de datos que trabajan con este lenguaje. Entre sus capacidades se encuentra el manejo de objetos DataFrame para la manipulación de tablas, la capacidad de importación y exportación los datos en múltiples formatos y el manejo de series temporales. Conocer las posibilidades para el procesado de series temporales con pandas ofrece la posibilidad de realizar muchas operaciones básicas que son muy habituales cuando se trabaja con este tipo de datos.
Creación de un rango de fechas
La manipulación de series temporales con pandas requiere que en primer lugar se importen los datos. En esta entrada se va a trabajar con un conjunto de datos aleatorio. En condiciones reales los datos se pueden importar empleado las herramientas que provee pandas para trabajar con diferentes tipos de archivos, como son los CSV o Excel.
En primer lugar, se ha de crear un rango de fechas para la serie temporal. Esto se puede conseguir mediante el método date_range de pandas. El rango de fechas requiere que se le indique la fecha de inicio, la fecha final y el número de periodos, la fecha de inicio, la fecha final y la frecuencia o el número de periodos, la frecuencia y alguna de las dos fechas. En el siguiente ejemplo se crear una serie desde el 1 de julio del 2018 al 15 de julio con una frecuencia de horas y se muestra el resultado.

import pandas as pd from datetime import datetime import numpy as np date_rng = pd.date_range(start='2018/07/01', end='2018/07/15', freq='H') date_rng
DatetimeIndex(['2018-07-01 00:00:00', '2018-07-01 01:00:00',
'2018-07-01 02:00:00', '2018-07-01 03:00:00',
'2018-07-01 04:00:00', '2018-07-01 05:00:00',
'2018-07-01 06:00:00', '2018-07-01 07:00:00',
'2018-07-01 08:00:00', '2018-07-01 09:00:00',
...
'2018-07-14 15:00:00', '2018-07-14 16:00:00',
'2018-07-14 17:00:00', '2018-07-14 18:00:00',
'2018-07-14 19:00:00', '2018-07-14 20:00:00',
'2018-07-14 21:00:00', '2018-07-14 22:00:00',
'2018-07-14 23:00:00', '2018-07-15 00:00:00'],
dtype='datetime64[ns]', length=337, freq='H')
Creación de series temporales con pandas
A partir del rango de fechas se puede crear una DataFrame con valores. Para esto se puede utilizar la función randint con la que se pueden conseguir número aleatorios en un rango. A continuación, se muestra un código con un ejemplo y los cinco primeros registros obtenidos.
ts = pd.DataFrame(date_rng, columns=['date']) ts['data'] = np.random.randint(0,100,size=(len(date_rng))) ts.head(5)

Si se desea realizar la manipulación de una serie temporal se ha de utilizar la fecha como índice del DataFrame. Modificar el índice del DataFrame es realmente sencillo, para lo que se puede utilizar el siguiente código:
ts = ts.set_index('date')
ts.head(5)
Funciones básicas para la manipulación básica de series temporales con pandas
Una de las primeras operaciones que se puede realizar con la serie temporal el seleccionar un periodo de tiempo. En caso de que se necesiten los registros de un día simplemente se ha de indicar la fecha y, en el ejemplo, se obtendrá los 24 registros. Por ejemplo, los datos del día 5 julio de 2018 se obtendrían con la línea:
ts['2018/07/05']
Para conseguir un perdido de tiempo simplemente se ha de indicar la fecha inicial y final separada por dos puntos. Por ejemplo, los dato entre el 5 y el 7 de julio de 2018 se pueden obtener mediante el código:
ts['2018/07/05':'2018/07/07']
Finalmente, si se indica solamente el año o el mes se obtendrían todos los registros de ese periodo. Por ejemplo, todos los datos de julio de 2018:
ts['2018/07']
Remuestreo de las series temporales
Los datos que se han utilizado hasta ahora tienen una frecuencia horaria. En el caso de que se desee los datos con otra frecuencia estos se pueden remuestrear. Esto se consigue con el método resample, al que se le ha de indicar el periodo y a su resultado se le puede aplicar una operación. Por ejemplo, la media semanal se puede obtener mediante el código:
ts.resample('W').mean()
Ventana móvil
Las estadísticas se pueden obtener también mediante una ventana móvil. Para ello se ha de utilizar el método rolling al que se le ha de indicar el número de periodos. La media móvil de tres periodos se puede calcular con:
ts['MA'] = ts.rolling(3).mean() ts.head(5)
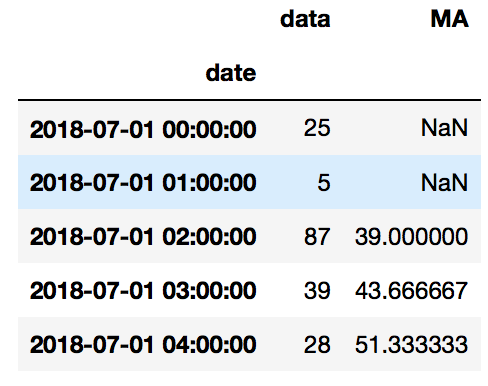
El resultado muestra tres valores nulos, estos se pueden completar con el método fillna.
ts['MA'] = ts['MA'].fillna(method='backfill') ts.head(5)

Conclusiones
En esta entrada se ha visto las herramientas básicas que provee pandas para trabajar con series temporales. A pesar de su sencillez estas herramientas permiten realizar una gran cantidad de trabajo con este tipo de datos.
Deja una respuesta