
RapidMiner Studio es una gran herramienta para el análisis y minería de datos. Facilitando la realización de estas tareas mediante la utilización de un entorno gráfico en el que se pueden encadenar diferentes operaciones. Una de estas operaciones permite importar datos directamente desde algunas de las bases de datos más populares como PostgreSQL, Oracle, MySQL o Microsoft SQL Server. Una base de datos que no se encuentra disponible por defecto es SQLite. En esta entrada se explicará cómo realizar la integración de RapidMiner con SQLite y los pasos necesarios para la importación de datos. Además, el proceso explicado en la entrada se puede utilizar posteriormente para la integración de otras bases de datos no incluidas por defecto en la configuración de RapidMiner Studio.
SQLite
SQLite es un motor de base de datos compatible con ACID que se distribuye como una biblioteca con un peso de uno 250Kb. Permitiendo integrar bases de datos relacionales en las aplicaciones con un impacto mínimo de recursos. A diferencia de los sistemas de bases de datos relacionales tradicionales SQLite no se ejecuta como un proceso independiente con el que se comunica la aplicación, sino que se enlaza con el programa principal.
Para utilizar SQLite en RapidMiner Studio es necesario disponer del controlador JDBC de SQLite. La última versión de este se puede descargar desde la página de descargas del proyecto.

Integración de RapidMiner con SQLite
La configuración de nuevas bases de datos en RapidMiner Studio se puede realizar a través del formulario que se acceda a través del menú Connections > Manage Database Drivers. En esta se muestran todas las conexiones a bases de datos disponibles, pudiéndose añadir, modificar o eliminar cualquiera. Para añadir SQLite a la lista simplemente se ha de pulsar en el botón Add y rellenar el formulario con los siguientes valores:
- Name: SQLite
- URL prefix: jdbc:sqlite:
- Port: [nada]
- Schema separator: /
- Jar file: [la ruta al archivo sqlite-jdbc-(VERSION).jar descargado previamente]
- Driver class: org.sqlite.JDBC
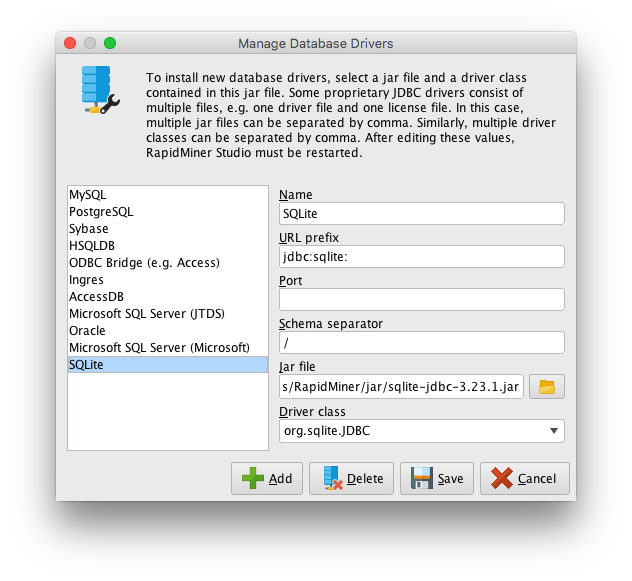
Una vez realizado esto se ha de pulsar en el botón Save. A partir de este momento se puede importar datos directamente de las bases de datos SQLite desde RapidMiner Studio.
Configuración una base de datos en RapidMiner
La importación de datos desde una base de datos se realiza en RapidMiner Studio con el operador “Read Database”. Es el mismo independientemente de la base de datos que se ha de seleccionar en los parámetros del operador. Concretamente la configuración se realiza mediante la opción “connection”. Las opciones que se han de cumplimentar son:
- Name: [cualquier nombre]
- Database system: SQLite
- Host:[la ruta absoluta al archivo sqlite]
- Port: [nada]
- Database scheme: [nada]
- User: [nada]
- Password: [nada]
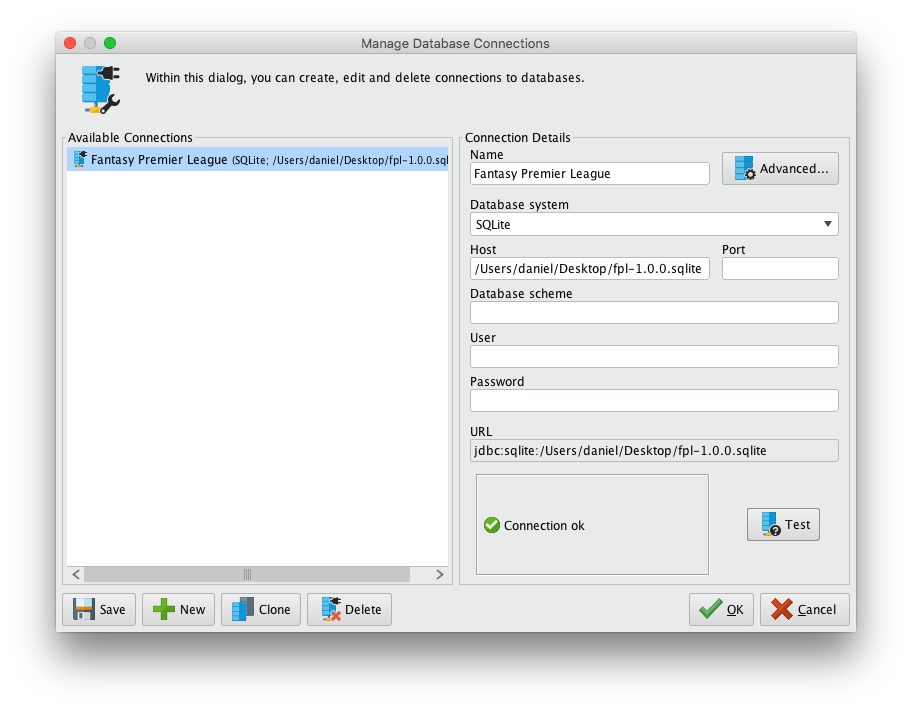
Una vez realizado esto se ha de pulsar en el botón Test y, si la configuración es correcta, lo indicará mediante el mensaje “Connection ok”. Una vez realizado esto se guarda la conexión pulsando en “Save”. Las conexiones guardadas se pueden utilizar posteriormente en múltiples operadores de conexión a base de datos.
Importación desde una base de datos en RapidMiner
Tras la configuración de la base de datos ya se puede acceder al contenido de esta. Ahora solamente se ha de crear una consulta SQL con la herramienta “Build SQL Query”. En esta se ha de seleccionar la tabla y los atributos a importar. Opcionalmente también se puede añadir condiciones.
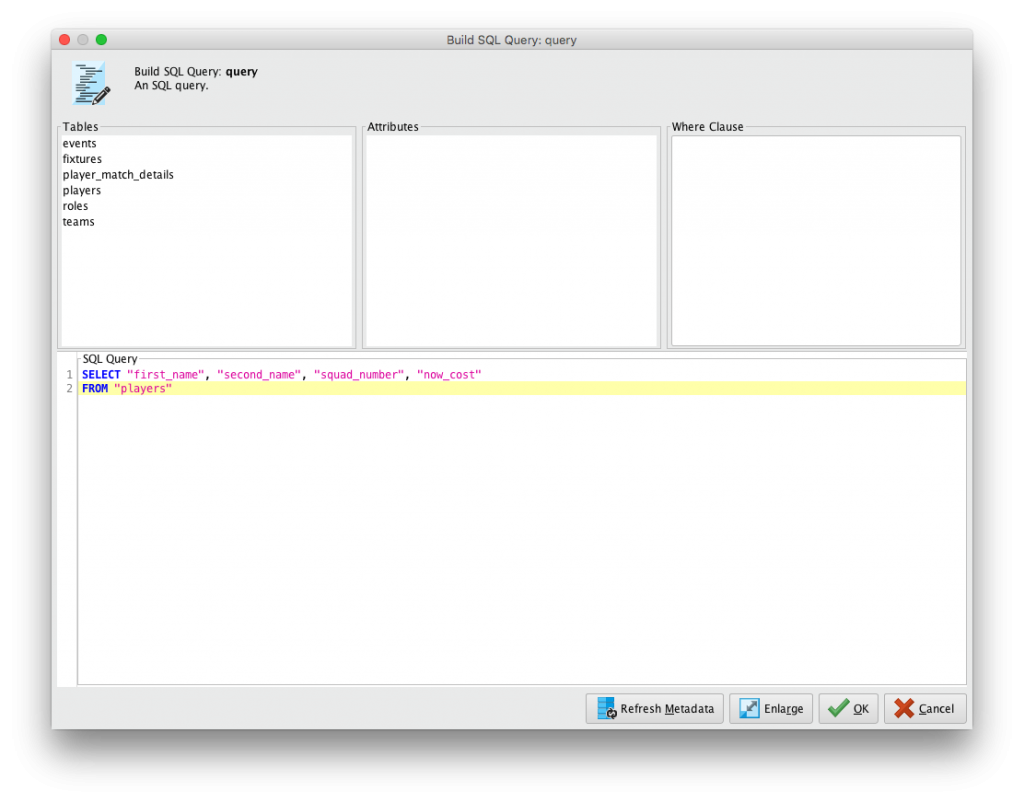
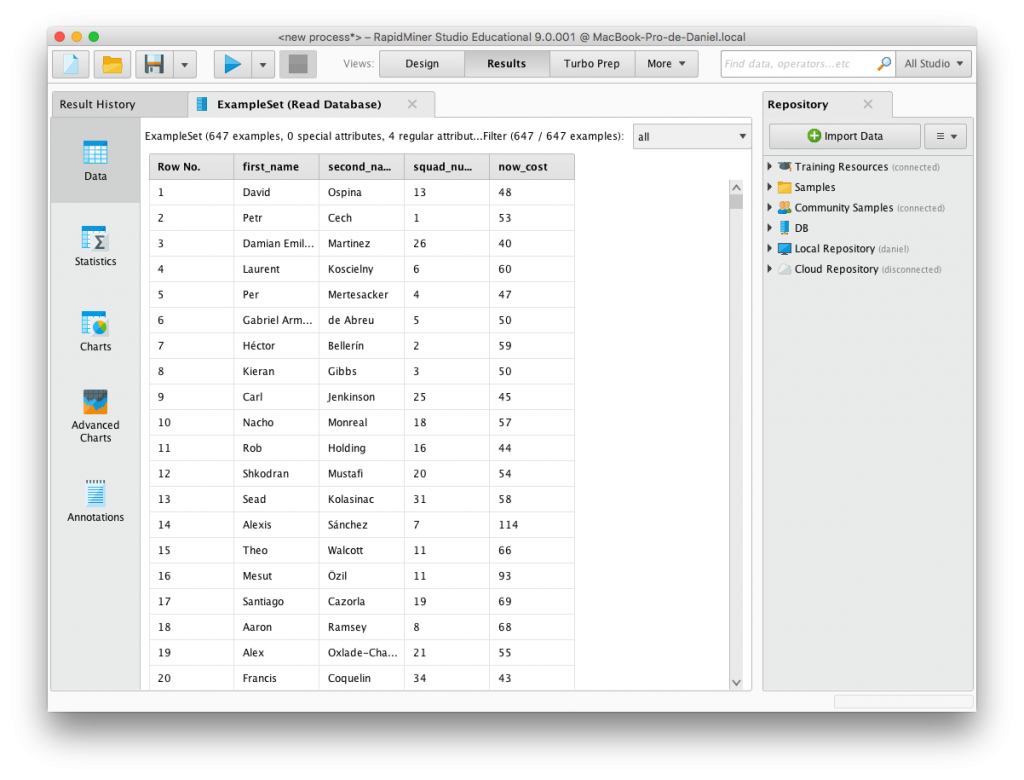
Al ejecutar el proceso se obtienen los datos de la consulta.
Conclusiones
RapidMiner Studio permite trabajar con múltiples motores de bases de datos. Entre estos los que se encuentran por defecto configurados no se encuentra SQLite. Para solucionar esto se ha visto cómo realizar la integración de RapidMiner con SQLite. Además, se ha aprendido los pasos para la importación de datos desde bases de datos una vez configurada esta.
Deja una respuesta