
En las entradas anteriores hemos visto cómo definir pruebas unitarias con pytest, así como ejecutarlas en diferentes versiones de Python con tox. Un dato importante de las pruebas es el nivel de cobertura, el porcentaje de código que se prueba. Para así poder identificar qué partes del código tienen pruebas asociadas y cuáles no. Con lo que se puede definir nuevas pruebas para estas últimas partes del paquete. Ya que cualquier cambio que se introduzca en el código sin cobertura puede modificar el comportamiento del paquete de una forma no desea. Que no detectaremos hasta que este se encuentre en producción. En esta cuarta parte de la serie “Creación de paquetes de Python” se va a explicar cómo medir la cobertura de las pruebas unitarias en Python con coverage.
Esta entrada forma parte de la colección “Creación de paquetes de Python” que consta de las siguientes siete entradas:
- Creación de paquetes de Python
- Pruebas unitarias en Python
- Probar en múltiples versiones de Python
- Cobertura de las pruebas unitarias en Python
- Gestionar las dependencias de paquetes Python
- Documentar paquetes de Python
- Distribuir paquetes de Python
Tabla de contenidos
Instalación de coverage
La librería que vamos a utilizar para crear pruebas unitarias es coverage, dado que es fácil de utilizar y proporciona la información necesaria. Como es habitual en Python el paquete coverage lo instalaremos utilizando pip, para lo que abriremos una terminal y escribiremos:

pip install coverage
Medir el nivel de cobertura
Tras la instalación de coverage solamente tenemos que ejecutar las pruebas unitarias a través de este. Para lo que hay que llamar a coverage seguido de la opción run y las instrucciones que hemos utilizado hasta ahora para lanzar las pruebas, es decir, tenemos que escribir:
coverage run pytest
Una vez hecho esto para ver el nivel de cobertura podemos simplemente hay que escribir coverage seguido de la opción report, para ver el informe en la terminal, o html, para crear un informe en formato HTML. En la terminal podemos ver un informe como el siguiente:
% coverage report Name Stmts Miss Cover ------------------------------------------------------------ pylane/__init__.py 3 0 100% pylane/arithmetic.py 4 0 100% tests/test_arithmetic.py 6 0 100% /opt/anaconda3/bin/pytest 6 0 100% ------------------------------------------------------------ TOTAL 19 0 100%
En donde se puede ver que el paquete tiene una cobertura de pruebas del 100%. Lo que es una buena noticia, podemos agregar código o modificar el actual sin miedo a cometer errores.
Configurar de los archivos en los que mide la cobertura
Algo que se puede apreciar en el informe es que no solamente mide las líneas código del paquete que se ejecutan, sino que también las de del código de pruebas. Algo que generalmente no es lo que se desea. Problema que se puede solucionar mediante el archivo de configuración .coveragerc. Un archivo que se ha de situar en la raíz del proyecto.
Existen dos opciones que son interesantes, una es limitar los archivos en los que se mide el nivel de cobertura y otro es mostrar las líneas que no se ejecutan en las pruebas. Cosa que no veíamos en el ejemplo anterior. Para limitar los archivos se usa la opción include donde se indica la ruta donde se medirá la cobertura. Por otro lado, para mostrar o no las líneas de código que no se prueban existe la opción show_missing que se ha de poner a verdadero si queremos verlas. Así se puede usar el siguiente archivo:
[run] include = aprendizaje_automatico_aplicado/* [report] show_missing = True
Una vez guardado este archivo el informe de cobertura será como el que se muestra a continuación. En donde la nueva columna Missing se indicará que líneas de cada uno de los archivos no se prueba. En este ejemplo, como la cobertura es del 100%, la columna se encuentra vacía.
Name Stmts Miss Cover Missing ---------------------------------------------------- pylane/__init__.py 3 0 100% pylane/arithmetic.py 4 0 100% ---------------------------------------------------- TOTAL 7 0 100%
Instalación del plugin pytest-cov
Instalar el plugin pytest-cov permite ejecutar las pruebas y generar el informe en un único paso. Simplificando el flujo de trabajo. Al igual que anteriormente converge la podemos instalar con pip:
pip install pytest-cov
Una vez instalado el plugin solamente tenemos que lanzar las pruebas con la opción --cov para obtener inmediatamente el informe de cobertura.
pytest --cov=pylane tests/
Identificar los métodos sin cobertura
Hasta ahora el código del paquete tiene una cobertura del 100%, pero sin creamos una nueva función multiplicar podremos comprobar como el informe nos indica las líneas que no tienen cobertura.
def addition(a, b):
return a + b
def subtraction(a, b):
return a - b
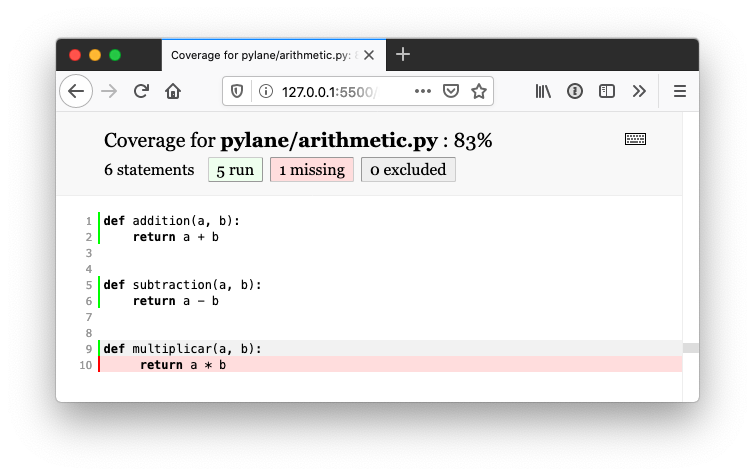
def multiplicar(a, b):
return a * bAsí agregando la función al archivo arithmetic.py, sin crear una nueva prueba, se obtiene el siguiente informe:
Name Stmts Miss Cover Missing ---------------------------------------------------- pylane/__init__.py 3 0 100% pylane/arithmetic.py 6 1 83% 10 ---------------------------------------------------- TOTAL 9 1 89%
En donde nos indica que la línea 10 de arithmetic.py no se ejecuta las pruebas. Por lo que el nivel de cobertura baja hasta un 83% para ese archivo y 89% para el total del proyecto.
Informe HTML
El informa en HTML además de ser más vistoso que la versión de terminal también nos permite navegar ver las líneas que no tienen cobertura. Así si escribimos el siguiente comando podremos acceder al documento web.
coverage html
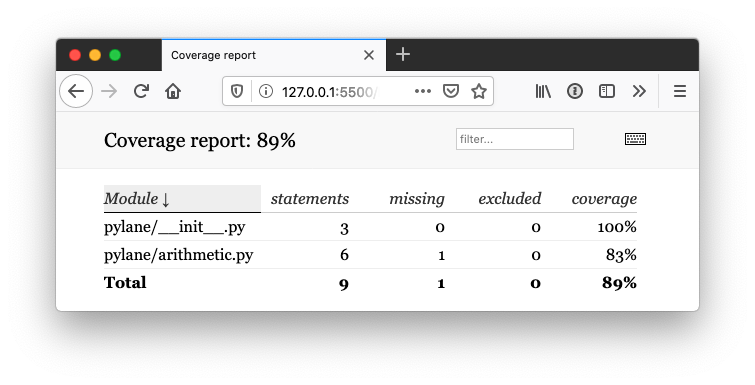
En la web se puede ver el mismo informe, pero si pulsamos sobre cada uno de los archivos se puede ver visualmente qué líneas se prueban y cuáles no. Algo que se puede ver en la siguiente captura de pantalla.
Conclusiones
En esta entrada se ha visto cómo medir la cobertura de las pruebas unitarias en Python con coverage. Un paquete que nos puede ayudar a comprobar que no se deja código sin probar. La próxima semana aprenderemos a gestionar las dependencias de paquetes de terceros.
Deja una respuesta