Seguir unos estándares de calidad a la hora de escribir un programa es algo clave de cara al futuro mantenimiento de cualquier solución. Haciendo más fácil su lectura al homogeneizar el estilo. Algo que también aplica en R. Una solución para garantizar el seguimiento de estos estándares son los analizadores estáticos de código o Linter. En R existe el paquete lintr con el que es posible auditar el código R para garantizar así que se siguen las mejores prácticas y los estándares de estilo.
El paquete lintr se encuentra disponible en el CRAN, por lo que su instalación se puede llevar a cabo mediante el proceso habitual.
Tabla de contenidos
Uso básico de lintr
Fijémonos en el siguiente código, una implementación del cálculo de la desviación estándar que aparentemente funciona correctamente.
MyStd <- function(x) {
mu = mean(x)
n <- length(x)
Sum2 <- sum((x - mu)^2)
return(sqrt(sum((x-mu)^2)/(n-1)))
}Obteniendo los mismos resultados que la función sd del paquete stats de R.
> sd(1:10) [1] 3.02765 > MyStd(1:10) [1] 3.02765
Ahora, para auditar este código solamente debemos guardarlo en un archivo, importar el paquete lintr y ejecutar la siguiente línea de código.
> lint('MyStd.R')
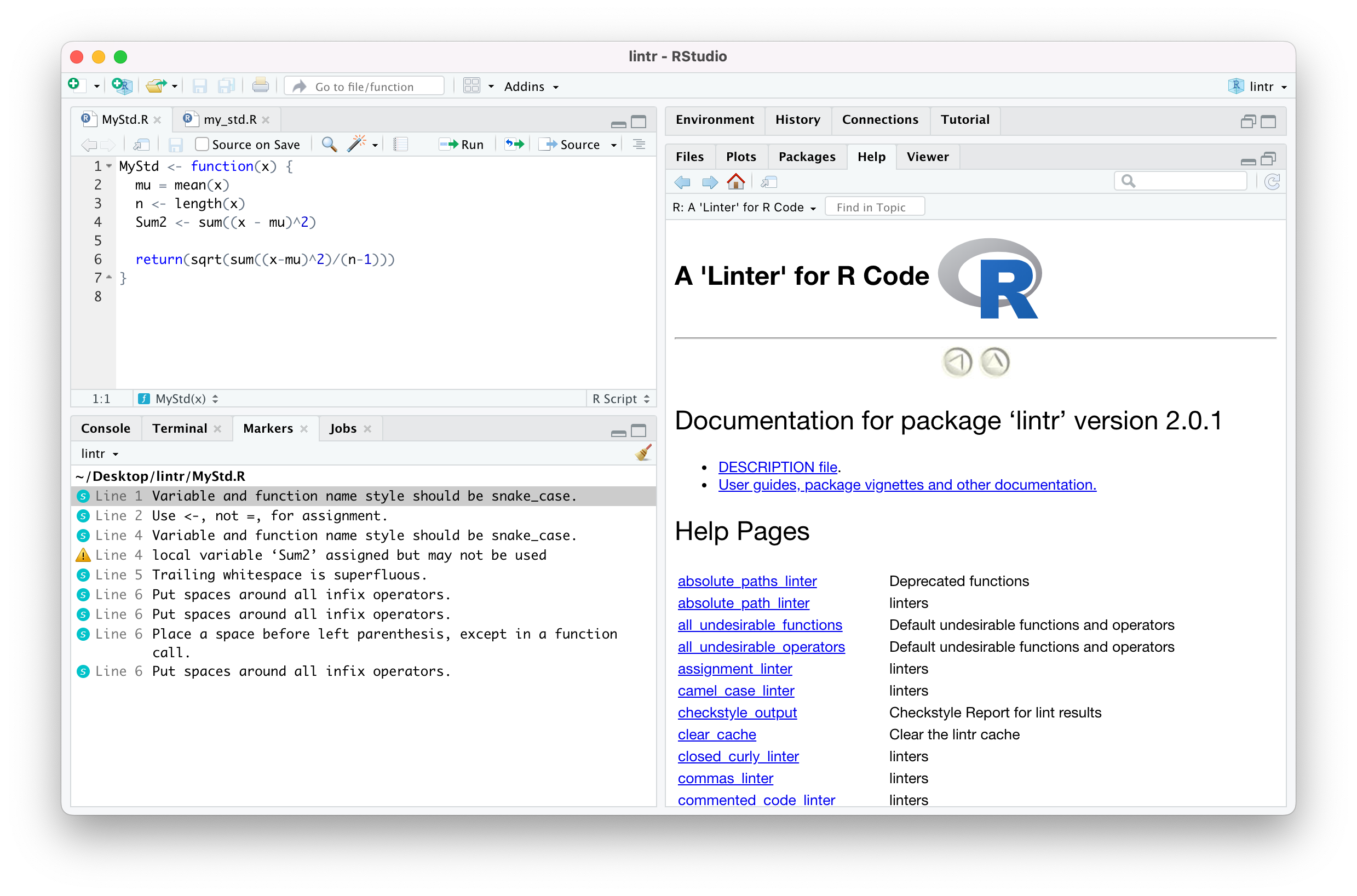
/Users/daniel/Desktop/test/test/MyStd.R:1:1: style: Variable and function name style should be snake_case.
MyStd <- function(x) {
^~~~~
/Users/daniel/Desktop/test/test/MyStd.R:2:6: style: Use <-, not =, for assignment.
mu = mean(x)
^
/Users/daniel/Desktop/test/test/MyStd.R:4:3: style: Variable and function name style should be snake_case.
Sum2 <- sum((x - mu)^2)
^~~~
/Users/daniel/Desktop/test/test/MyStd.R:4:3: warning: local variable 'Sum2' assigned but may not be used
Sum2 <- sum((x - mu)^2)
^~~~
/Users/daniel/Desktop/test/test/MyStd.R:5:1: style: Trailing whitespace is superfluous.
^~
/Users/daniel/Desktop/test/test/MyStd.R:6:21: style: Put spaces around all infix operators.
return(sqrt(sum((x-mu)^2)/(n-1)))
~^~
/Users/daniel/Desktop/test/test/MyStd.R:6:28: style: Put spaces around all infix operators.
return(sqrt(sum((x-mu)^2)/(n-1)))
~^~
/Users/daniel/Desktop/test/test/MyStd.R:6:29: style: Place a space before left parenthesis, except in a function call.
return(sqrt(sum((x-mu)^2)/(n-1)))
^
/Users/daniel/Desktop/test/test/MyStd.R:6:31: style: Put spaces around all infix operators.
return(sqrt(sum((x-mu)^2)/(n-1)))
~^~
>Lo que devuelve nueve errores, veámonos a continuación qué significa cada uno de ellos y los pasos para solucionarlo.

Notación snake_case
En R se recomienda usar la notación snake_case tanto para los nombres de funciones como de variables. Esto es, siempre en minúscula y para separar palabras un guion bajo. Algo que no se cumple en el código de ejemplo donde se usa la notación CamelCase tanto para el nombre de la función como para la variable Sum2. La solución de este problema es bastante sencilla, solamente se debe cambiar los nombres por otros más adecuados.
Uso de la igualdad para asignar =
La recomendación en R es usar <- para realizar las asignaciones, no el símbolo de igual =. Este posiblemente sea el problema más fácil de resolver, ya que solamente se ha de cambiar = por <- en todos los casos que aparezcan.
Variable asignada pero no usada
La variable Sum2 se ha definido, pero no se usa, algo que puede indicar un problema importante. La aparición de este tipo de mensajes puede deber a error en la implementación, un cálculo intermedio que no se usa, un código de depuración que no es necesario en producción, o algo que ha quedado pendiente de eliminar durante una refactorización del código. En este caso el problema posiblemente se deba a una reescritura del código, ya que la operación se implementa en la línea 6.
Espacio en blanco superfluos
Este problema es algo más difícil de ver que los anteriores, son espacios al final de la línea que no son necesarios. Posiblemente un error debido al editor de texto. La solución es también sencilla, borrar estos espacios en blanco.
Espacios alrededor de los operadores
Para facilitar la lectura de las fórmulas es aconsejable incluir espacios antes y después de la mayoría de los operadores. Algo que no se hace en la línea 6 donde se incluyen los cálculos principales de la función. La solución es sencilla, incluir los espacios para facilitar la lectura.
Resultado después de los cambios
Una vez solucionados los problemas indicados por lintr el código anterior de ejemplo quedaría algo tal como se muestra a continuación. Siendo un código más fácil de leer que el primero.
my_std <- function(x) {
mu <- mean(x)
n <- length(x)
return(sqrt(sum((x - mu)^2) / (n - 1)))
}Ahora, si se ejecuta el lintr sobre un archivo con la nueva función no se obtiene ningún error.
> lint('my_std.R')
>Integración con RStudio
Los usuarios de RStudio pueden disfrutar de una integración excelente de lintr en el entorno de desarrollo. Cuando se ejecuta el linter todos los errores se pueden ver en una pestaña especial, permitiendo ir directamente al problema haciendo click sobre cada una de las recomendaciones. Algo que es de gran utilidad en grandes archivos.

Conclusiones
Al igual que se ha visto en Python, el uso de analizadores estáticos de código permite encontrar de una forma automática errores de estilo y de codificación. Errores que no evitan que el código funcione, pero que puede afectar al mantenimiento o al rendimiento. Por eso es aconsejable usar estas herramientas como puede ser lintr para auditar el código R.
Deja una respuesta