Al trabajar con conjuntos de datos complejos, a menudo puede ser necesario explorar las relaciones entre las variables de tipo categóricas y continuas. Por ejemplo:
- ¿Cómo varían las ventas mensuales en función de la región y el tipo de producto?
- ¿Cuáles son los grupos demográficos en los que se muestra una tendencia concreta en un estudio científico?
Generalmente, la representación de este tipo de relaciones en un único gráfico puede ser algo confuso y poco claro. Siendo en estos casos donde la clase FacetGrid de Seaborn se convierte en una herramienta imprescindible. FacetGrid permite mostrar los datos en paneles múltiples en función de una o más variables de tipo categórico, creando de este modo gráficos separados para cada subconjunto de datos.
En esta entrada, se mostrará cómo utilizar sns.FacetGrid() para explorar datos categóricos y continuos en paneles múltiples, facilitando el análisis de tendencias complejas.
Para qué sirve la clase sns.FacetGrid() de Seaborn
FacetGrid es una clase de Seaborn que permite:
- Dividir un conjunto de datos en múltiples subconjuntos basados en una o más variables categóricas.
- Crear un gráfico independiente para cada subconjunto.
- Explorar visualmente patrones o tendencias específicas dentro de cada categoría.
Esto resulta útil cuando se desea realizar análisis en función de una variable dependiente de otras variables categóricas.
Uso básico de FacetGrid: Gráficos separados por una categoría
Supongamos que se tiene un conjunto de datos sobre el consumo de combustible en automóviles (que se puede importar de los ejemplos que existen en Seaborn) y se desea analizar cómo varía el consumo en función del tipo de combustible.

import seaborn as sns
import matplotlib.pyplot as plt
# Cargar datos de ejemplo
mpg = sns.load_dataset("mpg")
# Crear un FacetGrid
g = sns.FacetGrid(mpg, col="origin", height=4, aspect=1.2)
# Graficar histogramas de millas por galón (mpg)
g.map(sns.histplot, "mpg", kde=True, color="blue")
# Títulos y etiquetas
g.set_titles("Origen: {col_name}")
g.set_axis_labels("Millas por galón", "Frecuencia")
g.tight_layout()
plt.show()En este ejemplo, una vez importados los datos, se ha llamado al constructor de la clase FacetGrid() con el parámetro col="origin", lo que permite dividir los gráficos en columnas en función de la variable categórica origin. A continuación, se llama al método map() que crea un gráfico (en este caso, un histograma) para cada subconjunto de datos. Representándo cada uno de los paneles un subconjunto diferente de origin. El resultado después de ejecutar este código sería una figura como la que se muestra a continuación.
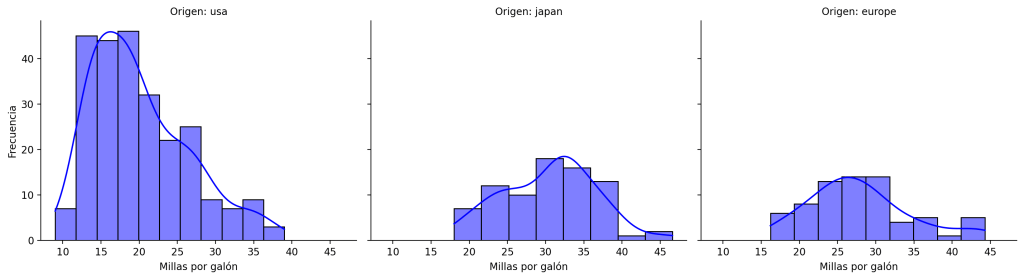
Agregar múltiples dimensiones al análisis: Gráficos separados por filas y columnas
La clase FacetGrid permite añadir otra dimensión categórica usando el argumento row. Por ejemplo, se pueden dividir los datos en base al origin (columnas) y cylinders (filas, para el número de cilindros). Algo que se puede conseguir con el siguiente código:
# Crear un FacetGrid con filas y columnas
g = sns.FacetGrid(mpg, col="origin", row="cylinders", height=3, aspect=1.2)
# Graficar diagramas de dispersión (peso vs millas por galón)
g.map(sns.scatterplot, "weight", "mpg", color="purple", alpha=0.7)
# Títulos y etiquetas
g.set_titles("Origen: {col_name} | Cilindros: {row_name}")
g.set_axis_labels("Peso", "Millas por galón")
g.tight_layout()
plt.show()En este ejemplo, cada panel está definido en función de una combinación de origin y cylinders. Lo que permite observar tendencias en subgrupos más específicos del conjunto de datos. El resultado de este código se puede ver en la siguiente figura.
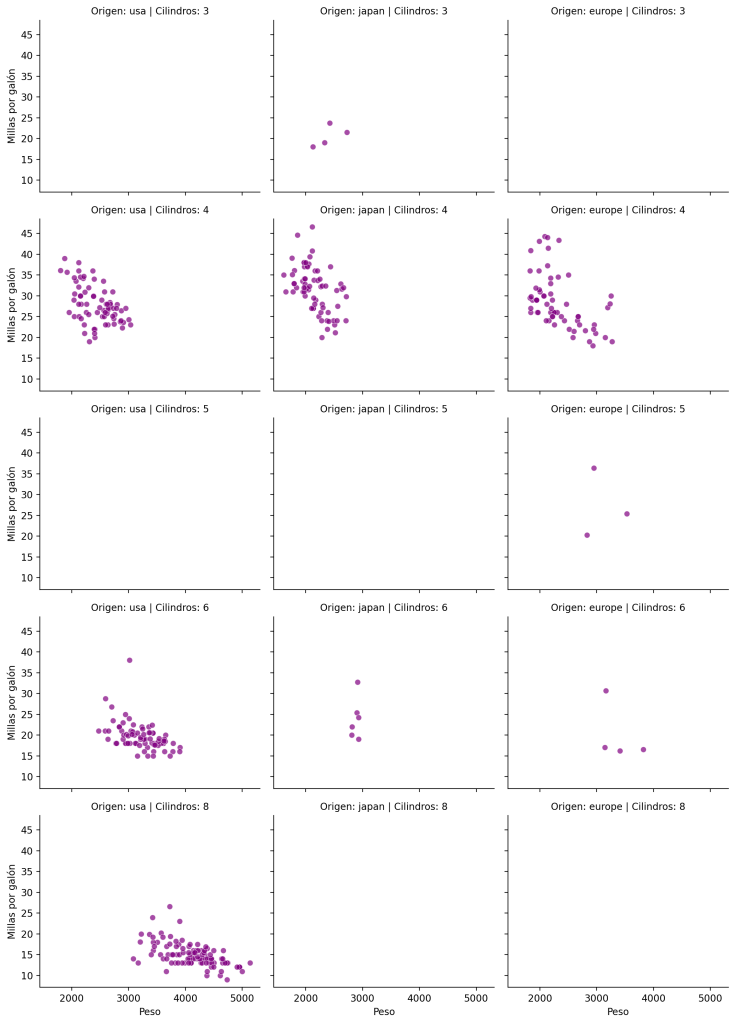
Personalización avanzada con FacetGrid: Agregar colores y estilos personalizados
Los gráficos se pueden personalizar con estilos, paletas de colores y leyendas. Esto es lo que se muestra en el siguiente ejemplo.
# Crear un FacetGrid con paleta de colores personalizada
palette = {"usa": "red", "europe": "green", "japan": "blue"}
g = sns.FacetGrid(mpg, col="origin", hue="origin", height=4, aspect=1.2, palette=palette)
# Graficar diagramas de dispersión
g.map(sns.scatterplot, "weight", "mpg", alpha=0.8)
# Agregar una leyenda
g.add_legend(title="Origen")
g.set_titles("Origen: {col_name}")
g.set_axis_labels("Peso", "Millas por galón")
g.tight_layout()
plt.show()En este código, el parámetro hue colorea los puntos en función de la variable categórica origin. Además, también se agrega una leyenda para interpretar los colores. El resultado se muestra en la siguiente figura:
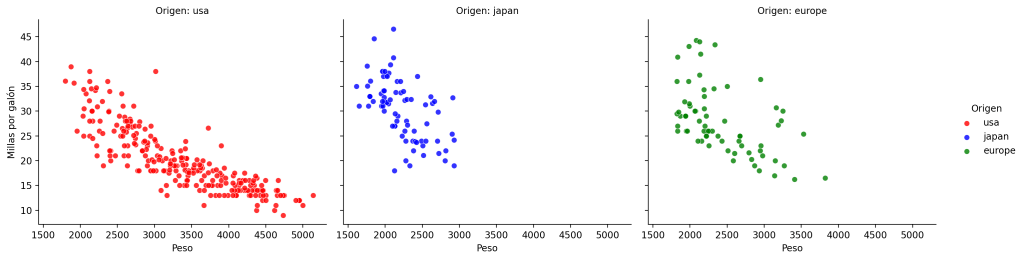
Uso de funciones personalizadas en FacetGrid: Mapear funciones personalizadas
FacetGrid también permite el uso de funciones personalizadas para aplicar cálculos adicionales o personalizar el propio gráfico. Esto se puede ver en el siguiente ejemplo.
# Función personalizada para agregar líneas de tendencia
import numpy as np
def scatter_with_trend(x, y, **kwargs):
sns.scatterplot(x=x, y=y, **kwargs)
z = np.polyfit(x, y, 1)
p = np.poly1d(z)
plt.plot(x, p(x), color="orange", linestyle="--")
# Crear un FacetGrid
g = sns.FacetGrid(mpg, col="origin", height=4, aspect=1.2)
# Aplicar la función personalizada
g.map(scatter_with_trend, "weight", "mpg", alpha=0.7)
g.set_titles("Origen: {col_name}")
g.set_axis_labels("Peso", "Millas por galón")
g.tight_layout()
plt.show()Aquí, la función personalizada scatter_with_trend añade líneas de tendencia a cada uno de los gráficos.
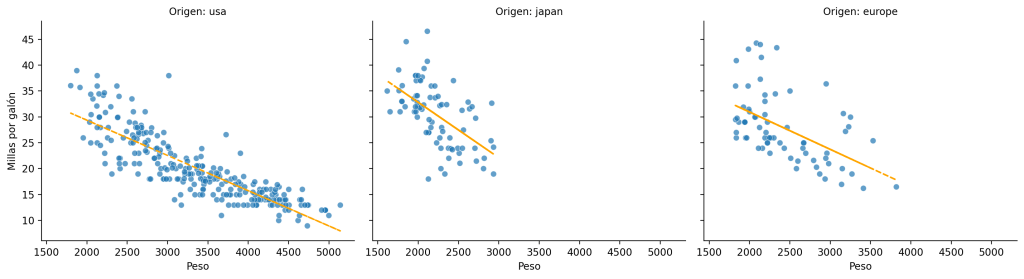
Conclusiones
La clase FacetGrid de Seaborn es una opción interesante para la creación de gráficos complejos donde es necesario relacionar variables categorías con continuas. Algo que hace mediante la creación de gráficos con múltiples paneles. Facilitando con esto el análisis de tendencias y patrones en subconjuntos de datos, lo que permite la identificación de valores clave en los datos.
Ya sea para trabajar con datos demográficos, series temporales o cualquier otro tipo de información, FacetGrid permite crear visualizaciones claras y efectivas que destacan las relaciones más importantes.
Deja una respuesta