
En el análisis de redes, no es suficiente identificar únicamente los nodos más conectados. A menudo, es igual o mas importante reconocer aquellos que ocupan posiciones estratégicas como fuentes confiables de información o como nodos intermediarios clave. Es decir, identificar aquellos que poseen una posición de prestigio o autoridad dentro de la red. En este contexto, el modelo HITS (Hyperlink-Induced Topic Search), propuesto por Jon Kleinberg en 1999, introduce dos conceptos fundamentales: autoridades y hubs (centros de referencia). Conceptos a partir de los cuales se construyen las métricas de centralidad de prestigio y autoridad.
Este modelo es especialmente útil para analizar redes de información, como la web o las redes de citaciones académicas, donde ciertos nodos funcionan como fuentes de conocimiento y otros como puentes que conectan dichas fuentes.
A diferencia de algoritmos como PageRank, que calculan la importancia de un nodo en función de los enlaces que recibe este, HITS establece una relación recíproca entre dos tipos de nodos: los hubs, aquellos que apuntan a buenas autoridades, y las autoridades, los nodos a los apunta buenos hubs. Esta doble perspectiva permite capturar de forma más precisa la dinámica de influencia que existe en las redes dirigidas.
En esta entrada, explicaremos la teoría detrás de la centralidad de prestigio y autoridad, su aplicación en el análisis de redes, cómo implementarla en R utilizando la librería igraph para finalizar con un ejemplo práctico que demuestra su utilidad.

Tabla de contenidos
¿Cómo funciona el modelo HITS? Explicando los hubs y autoridades
El algoritmo HITS asigna a cada nodo dos puntuaciones complementarias que capturan las diferentes formas de relevancia que existen dentro de una red:
- Puntuación de autoridad: mide cuán confiable es un nodo como fuente de información. Una autoridad fuerte es aquella que es referenciada frecuentemente por nodos importantes.
- Puntuación de hub: mide cuán útil es un nodo como conector hacia buenas fuentes. Un hub fuerte es aquel que enlaza a múltiples autoridades relevantes.
En esencia, los hubs y las autoridades se refuerzan mutuamente: los buenos hubs apuntan a buenas autoridades, y las buenas autoridades son apuntadas por buenos hubs.
A nivel computacional, HITS se basa en la estructura de enlaces del grafo, utilizando la matriz de adyacencia para calcular ambas puntuaciones de forma iterativa. El procedimiento se repite hasta alcanzar la convergencia, es decir, hasta que las puntuaciones de los nodos se estabilizan.
Además, para evitar que los valores crezcan indefinidamente durante el proceso iterativo, las puntuaciones se normalizan en cada iteración (por ejemplo, dividiendo entre su norma euclidiana).
Este modelo resulta particularmente útil en redes donde los nodos cumplen roles distintos en la difusión del conocimiento (como en redes académicas, sistemas de recomendación, o la propia estructura de la web) y ofrece una visión más matizada que otros algoritmos de centralidad que solo consideran el número de conexiones entrantes o salientes.
Representación matemática del algoritmo HITS
Supongamos que tenemos un grafo dirigido representado por su matriz de adyacencia A, donde A_{ij} = 1 si existe un enlace desde el nodo [látex]i[/latex] hacia el nodo j y A_{ij} = 0 en caso contrario.
Ahora, se pueden definir los siguientes vectores:
- \mathbf{h} el vector de puntuaciones de hub.
- \mathbf{a} el vector de puntuaciones de autoridad.
El algoritmo HITS se define mediante el siguiente sistema de ecuaciones iterativas: \mathbf{a}^{(t+1)} = A^T \mathbf{h}^{(t)} \mathbf{h}^{(t+1)} = A \mathbf{a}^{(t+1)}
Después de cada iteración, ambos vectores se normalizan para mantener la estabilidad numérica y asegurar la convergencia del algoritmo. Una vez que \mathbf{a} y [/latex]\mathbf{h}[/latex] convergen a valores estables (dentro de una tolerancia numérica), obtenemos las puntuaciones finales de autoridad y de hub para cada nodo de la red.
Interpretación de los resultados de HITS
Una vez calculadas las puntuaciones de autoridad y hub, es importante comprender qué nos indica cada uno de estos valores sobre la estructura de la red:
- Un nodo con alta autoridad es considerado una fuente confiable de información. En una red de citas académicas, por ejemplo, son los artículos frecuentemente citados por otros trabajos relevantes.
- Un nodo con alto hub actúa como un buen conector o índice, apuntando hacia muchas autoridades importantes. En el mismo contexto académico, podría tratarse de un artículo de revisión que enlaza (cita) numerosos trabajos influyentes.
Ambas métricas no son absolutas, sino relativas al conjunto de la red. Es decir, un nodo puede tener alta puntuación solo si está bien conectado con otros nodos relevantes en su rol. Esto significa que:
- Un nodo no puede ser una buena autoridad si no se encuentra enlazado por buenos hubs.
- Un nodo no puede ser un buen hub si no apunta a buenas autoridades.
Comparación con otras métricas
Es común confundir estas puntuaciones con otras medidas de centralidad como PageRank o la centralidad de grado. Sin embargo:
- PageRank combina popularidad e importancia en una única puntuación basada en enlaces entrantes, y es más adecuada cuando no se hace distinción entre tipos de nodos.
- HITS, en cambio, diferencia explícitamente entre dos roles complementarios: autor y conector, lo que lo hace más informativo en contextos donde esta distinción tiene sentido (como motores de búsqueda, bibliografía académica, o análisis de influencers).
Limitaciones de la centralidad de prestigio y autoridad
A pesar de esto, es importante comprender que HITS cuenta con algunas limitaciones a la hora de medir las relaciones en la red:
- HITS puede ser sensible a la estructura local de la red y tender a sobrevalorar ciertos nodos en subredes densamente conectadas.
- Se basa únicamente en la estructura de enlaces, sin tener en cuenta el contenido o contexto semántico de los nodos o conexiones.
Por estas razones, la interpretación de los resultados debe hacerse siempre considerando el contexto de la red y, si es posible, en combinación con otras métricas de centralidad.
Aplicación en redes información y búsqueda
El modelo HITS es especialmente útil en sistemas donde la relevancia de la información depende de la estructura de los enlaces. Algunas aplicaciones clave incluyen:
- Motores de búsqueda: Antes de la consolidación de PageRank, HITS fue utilizado para clasificar páginas web según su relevancia temática. Identificar hubs y autoridades permitía mejorar los resultados de búsqueda en función de la estructura de enlaces de la web.
- Redes de citaciones académicas: Los artículos con muchas citas de trabajos influyentes se consideran autoridades, mientras que los artículos que citan múltiples fuentes de prestigio actúan como hubs.
- Redes sociales: En plataformas como Twitter, los usuarios que enlazan a fuentes confiables pueden ser considerados hubs, mientras que los perfiles con muchos enlaces de usuarios destacados actúan como autoridades.
- Análisis de comunidades: Permite identificar qué nodos son clave en la difusión de información dentro de un ecosistema. Esto puede ser útil en estudios de redes de influencia política, marketing viral y análisis de redes de colaboración científica.
La capacidad de HITS para diferenciar entre autoridades y hubs lo hace particularmente valioso en estos contextos, ya que permite un análisis más detallado de cómo la información fluye a través de una red.
En igraph, el cálculo de las puntuaciones de autoridad y hub se realiza de manera directa usando las funciones authority_score() y hub_score(). Estas funciones implementan el algoritmo HITS, iterando sobre la matriz de adyacencia del grafo hasta alcanzar la convergencia.
A continuación, se presenta un ejemplo práctico en R, donde se crea un grafo dirigido y se calculan las puntuaciones correspondientes.
library(igraph)
# Crear un grafo dirigido
g <- graph(edges = c("A", "B", "A", "C", "B", "D", "B", "E", "C", "F", "E", "F", "D", "E", "C", "D"), directed = TRUE)
# Calcular las puntuaciones de autoridad y hub
authority <- authority_score(g)$vector
hub <- hub_score(g)$vector
# Mostrar resultados
cat("Puntuaciones de autoridad:\n")
print(round(authority, 3))
cat("Puntuaciones de hub:\n")
print(round(hub, 3))En este ejemplo, el grafo dirigido contiene seis nodos (A–F) conectados de manera que algunos actúan como fuentes de enlaces y otros como destinos. Esto nos permite ilustrar bien cómo el algoritmo HITS distingue entre hubs (nodos que enlazan a otros) y autoridades (nodos que son enlazados por otros).
Los resultados obtenidos son:
Puntuaciones de autoridad:
A B C D E F
0.000 0.000 0.000 1.000 0.707 0.707
Puntuaciones de hub:
A B C D E F
0.000 1.000 1.000 0.414 0.414 0.000
Interpretación de los resultados
Con lo que se pueden obtener las siguientes conclusiones:
- Los nodos D, E y F presentan las puntuaciones más altas de autoridad. Esto se debe a que son los principales destinos de enlaces en la red, es decir, otros nodos apuntan hacia ellos. En particular:
- D recibe enlaces de B y C, y a su vez apunta a E.
- E recibe enlaces desde B y D.
- F es el destino final de varios caminos (por ejemplo, desde C y E).
- Por otro lado, los nodos B y C alcanzan las puntuaciones más altas de hub. Esto refleja que estos nodos tienen un rol relevante como intermediarios que enlazan a autoridades. En concreto:
- B enlaza a D y E, ambos con alta autoridad.
- C enlaza a D y F, también con alta autoridad.
- El nodo A tiene puntuaciones nulas en ambos casos. Aunque A inicia algunos enlaces, estos son a B y C, que a su vez funcionan como hubs, no como autoridades directamente. Por ello, A no acumula puntuación de hub ni de autoridad.
Este contraste numérico entre las puntuaciones pone de manifiesto cómo HITS distingue claramente entre:
- Los productores de información relevante o autoridades (nodos apuntados por otros importantes).
- Los organizadores o conectores de conocimiento, es decir, los hubs (nodos que enlazan hacia muchas autoridades).
Esta diferenciación es especialmente útil en análisis de redes como las de hipertexto, donde algunas páginas web (como Wikipedia o directorios) actúan como hubs, mientras que otras (como artículos científicos o páginas de referencia) funcionan como autoridades.
Visualización del grafo
Para una mejor comprensión, podemos visualizar la red, para lo que se usa el siguiente código:
# Dibujar el grafo con tamaños de nodo según puntuaciones
plot(g,
vertex.size = 30 * authority + 15,
vertex.label = V(g)$name,
vertex.color = "lightblue",
edge.arrow.size = 0.5,
main = "Tamaños según puntuación de autoridad")
# Alternativamente, tamaño por hub:
plot(g,
vertex.size = 30 * hub + 15,
vertex.label = V(g)$name,
vertex.color = "orange",
edge.arrow.size = 0.5,
main = "Tamaños según puntuación de hub")En los siguientes gráficos, los tamaños de los nodos están escalados según sus puntuaciones de autoridad y hub.
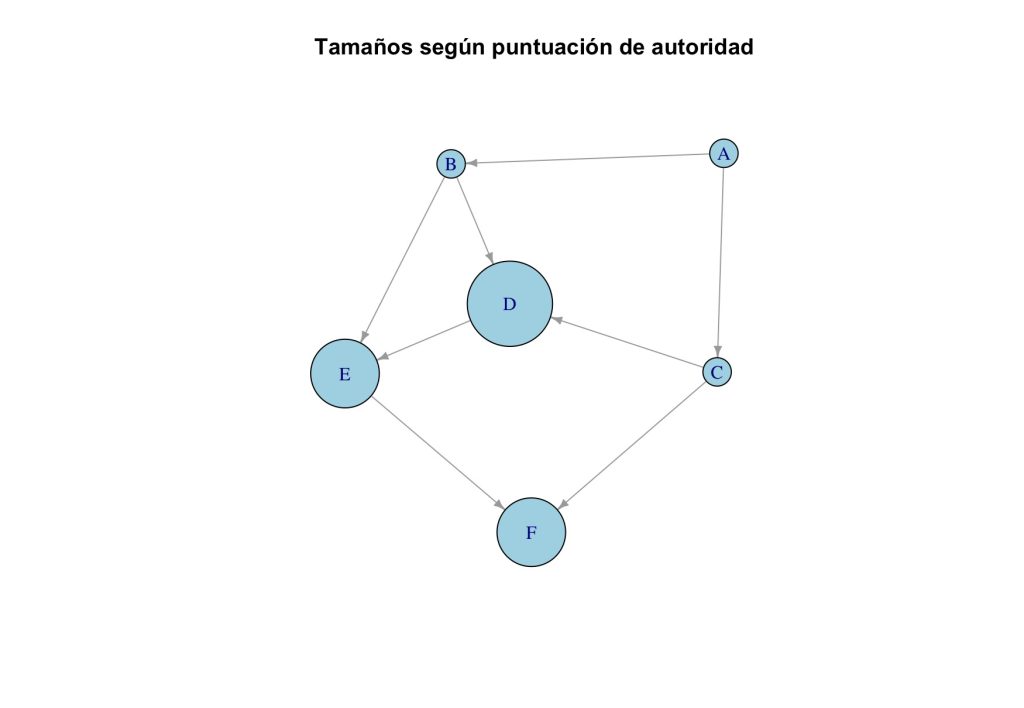
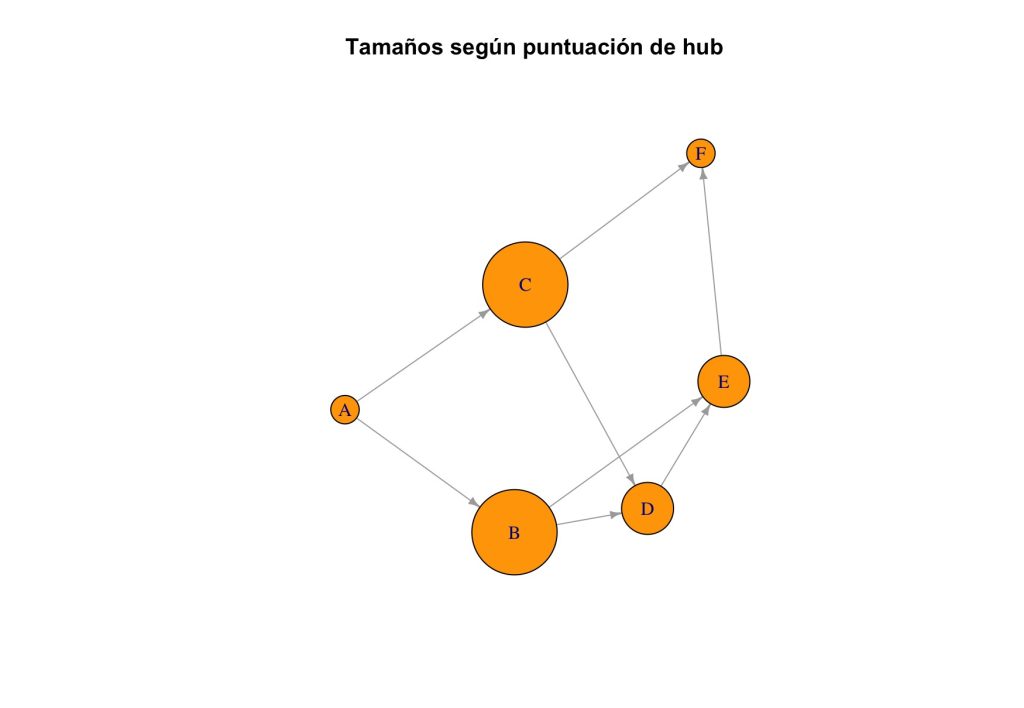
Estas figuras ayudan a interpretar visualmente los resultados del algoritmo:
- En el primer gráfico, los nodos más grandes son aquellos con mayor autoridad.
- En el segundo, los más grandes son los que tienen un papel destacado como hubs.
Ejemplo aplicado: Red de páginas web
Para ilustrar el uso del algoritmo HITS en un contexto más cercano a aplicaciones reales, vamos a simular una pequeña red de páginas web. Imaginemos que tenemos un sitio con una página principal (“Inicio”), un blog que enlaza a artículos, y enlaces entre las diferentes secciones del sitio:
# Crear una red web simulada
web <- graph(edges = c("Inicio", "Blog",
"Inicio", "Contacto",
"Blog", "Articulo1",
"Blog", "Articulo2",
"Articulo1", "Contacto",
"Articulo2", "Contacto",
"Articulo2", "Inicio"),
directed = TRUE)
# Calcular puntuaciones de autoridad y hub
authority_web <- authority_score(web)$vector
hub_web <- hub_score(web)$vector
# Mostrar resultados redondeados
cat("Puntuaciones de autoridad:\n")
print(round(authority_web, 3))
cat("Puntuaciones de hub:\n")
print(round(hub_web, 3))Al ejecutar el algoritmo HITS sobre nuestra red web simulada, obtenemos las siguientes puntuaciones:
Puntuaciones de autoridad:
Inicio Blog Contacto Articulo1 Articulo2
0.366 0.366 1.000 0.000 0.000
Puntuaciones de hub:
Inicio Blog Contacto Articulo1 Articulo2
1.000 0.000 0.000 0.732 1.000
En base a lo que se puede llegar a las siguientes conclusiones:
- “Contacto” se posiciona como la principal autoridad con una puntuación de 1.000. Esto se debe a que múltiples páginas la enlazan (desde Inicio, Articulo1, Articulo2), lo que indica que es una página considerada importante dentro del sitio.
- “Inicio” y “Articulo2” obtienen las puntuaciones más altas como hubs (1.000 cada uno), ya que ambos enlazan a varias páginas de relevancia (como Blog, Contacto, Inicio), cumpliendo el rol de conectores o distribuidores de enlaces.
- “Blog”, aunque conceptualmente parece un hub, no recibe puntuación como tal, probablemente porque enlaza a páginas (Articulo1, Articulo2) que no son consideradas autoridades según la estructura de enlaces. Sin embargo, sí tiene una puntuación de autoridad intermedia (0.366), ya que es enlazada por Inicio y Articulo2.
- “Articulo1” y “Articulo2” no son considerados autoridades, pues nadie los enlaza (ellos solo apuntan hacia otras páginas), pero sí actúan parcialmente como hubs, especialmente Articulo1, que enlaza a Contacto.
Este contraste ilustra cómo HITS distingue entre páginas que reúnen y distribuyen enlaces relevantes (hubs) y páginas que reciben múltiples enlaces de hubs (autoridades). Además, permite visualizar de forma clara el flujo de la relevancia dentro de una estructura web.
Representación gráfica del ejemplo
Al igual que antes se puede usar el siguiente código para generar una figura en la se muestra el tamaño del nodo en función de la puntuación de autoridad y otro en base a la puntuación del hub.
# Visualización: tamaño por autoridad
plot(web,
vertex.size = authority_web * 35 + 25,
vertex.label = V(web)$name,
vertex.color = "lightblue",
edge.arrow.size = 0.5,
main = "Tamaño de nodo según puntuación de autoridad")
# Visualización: tamaño por hub
plot(web,
vertex.size = hub_web * 35 + 25,
vertex.label = V(web)$name,
vertex.color = "orange",
edge.arrow.size = 0.5,
main = "Tamaño de nodo según puntuación de hub")Obteniendo como resultado:
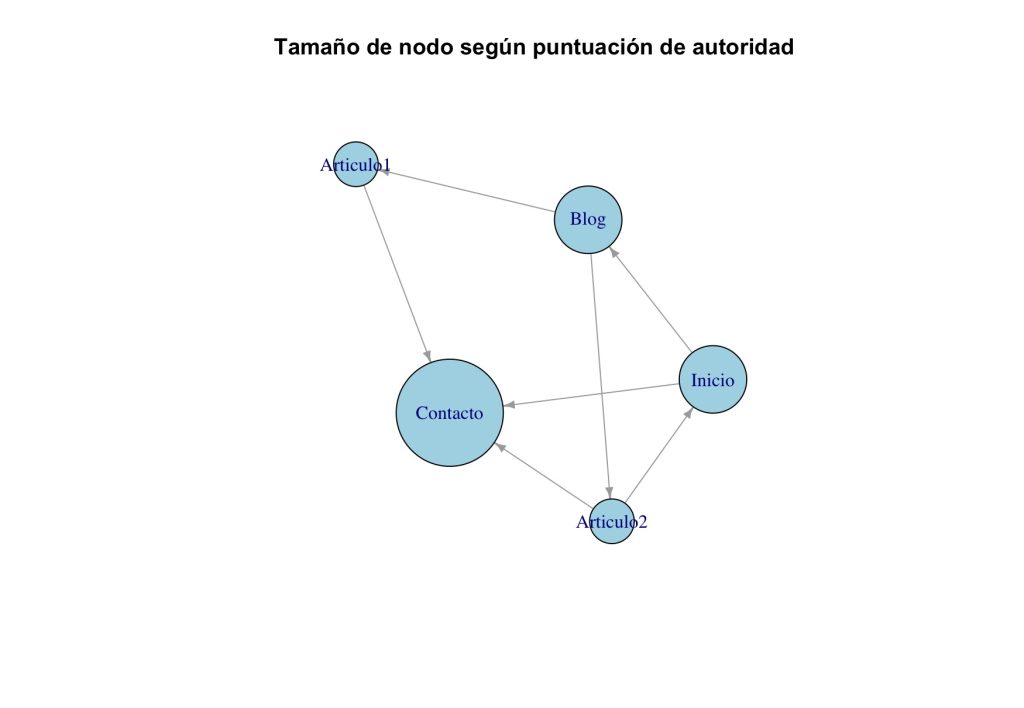
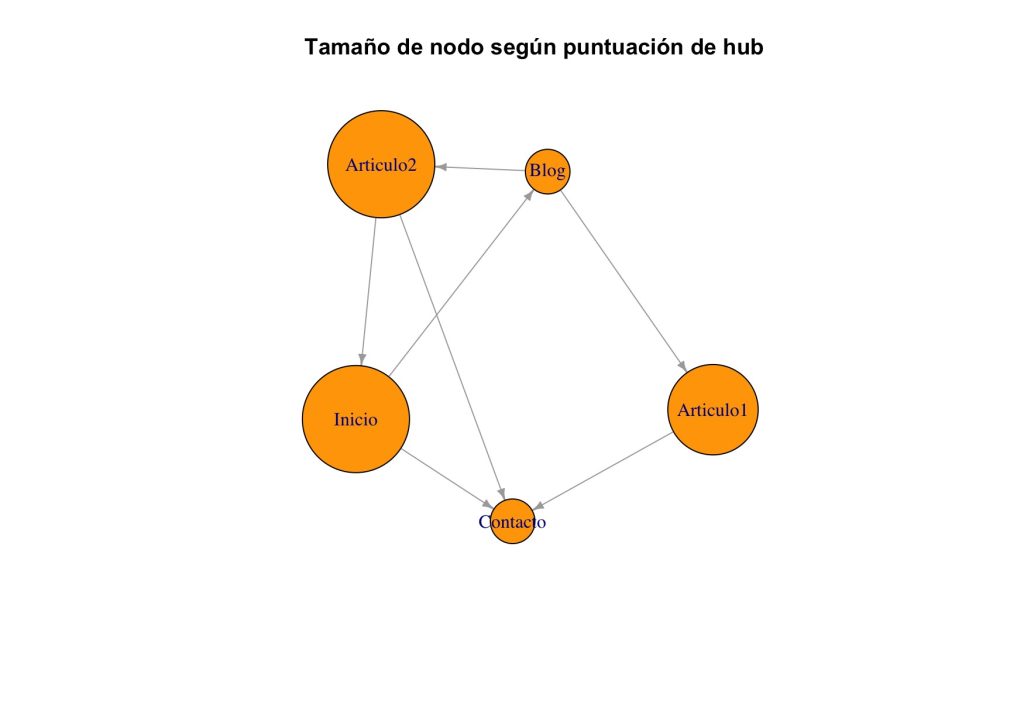
Conclusiones
El modelo HITS proporciona una perspectiva valiosa en el análisis de redes, diferenciando entre nodos que actúan como autoridades y aquellos que cumplen funciones de hubs o conectores. Esta dualidad permite capturar no solo quién es importante por ser referenciado, sino también quién contribuye a destacar a otros dentro de una red.
A diferencia de otras métricas como el grado o el PageRank, HITS no asigna una única medida de centralidad, sino que ofrece dos puntuaciones complementarias. Esto es especialmente útil en contextos como el análisis de hipervínculos, redes académicas o flujos de información, donde el rol de cada nodo puede diferir entre influencia directa y capacidad de curaduría.
A través de igraph, su implementación en R es directa y flexible, lo que facilita su aplicación a redes dirigidas reales o simuladas. A lo largo de los ejemplos mostrados, hemos visto cómo HITS puede detectar estructuras jerárquicas, flujos de influencia y relaciones asimétricas entre nodos.
En la próxima entrega, finalizamos esta serie con un Resumen y Comparativa de Centralidades, en la que revisaremos los principales tipos de centralidad estudiados (grado, cercanía, eigenvector, PageRank y HITS), evaluando sus diferencias, fortalezas y casos de uso recomendados.
Nota: La imagen de este artículo fue generada utilizando un modelo de inteligencia artificial.
Deja una respuesta