Vivimos en un mundo saturado de datos, estadísticas, informes y gráficos. Cada día, en los medios de comunicación, las redes sociales o conversaciones cotidianas, escuchamos frases como: “Las personas que hacen ejercicio viven más” o “Los países con mayor consumo de chocolate tienden a tener más premios Nobel”. Estas afirmaciones, aunque pueden estar basadas en datos reales y parecer lógicas, nos pueden conducir a conclusiones erróneas si no sabemos diferenciar claramente entre dos conceptos fundamentales: correlación y causalidad.
La correlación indica una relación entre dos variables, pero no implica necesariamente que una cause a la otra. Los que sí implica la causalidad. Confundirnos entre estos dos conceptos puede llevar a errores graves, desde tomar decisiones personales equivocadas hasta diseñar políticas públicas ineficientes o peligrosas.
En esta entrada vamos a explorar con profundidad qué significan realmente los conceptos de correlación y causalidad, cómo se calculan, cómo pueden confundirse y, sobre todo, cómo evitar caer en la trampa de asumir que si dos cosas ocurren juntas (están correlacionadas), una debe ser la causa de la otra (existe una causalidad entre ambas). Usaremos ejemplos cotidianos, visuales, históricos y también tocaremos métodos más rigurosos para identificar relaciones causales. Al final, tendrás una comprensión mucho más sólida de estos conceptos esenciales para el pensamiento crítico y la interpretación correcta de la información.

Tabla de contenidos
- 1 ¿Qué es la correlación?
- 2 ¿Qué es la causalidad?
- 3 Ejemplos clásicos de confusión entre correlación y causalidad
- 4 ¿Por qué confundimos correlación con causalidad?
- 5 Cómo identificar relaciones causales correctamente
- 6 Consecuencias reales de confundir correlación con causalidad
- 7 Recomendaciones para lectores críticos
- 8 Conclusiones
¿Qué es la correlación?
La correlación es una medida estadística que indica en qué los valores de dos variables están relacionadas. En términos simples, nos dice si, cuando una variable cambia, la otra tiende a cambiar también, y en qué dirección lo hace.
- Una correlación positiva significa que ambas variables tienden a aumentar o disminuir juntas. Por ejemplo, a mayor número de horas de estudio, mayores suelen ser las calificaciones.
- Una correlación negativa indica que cuando una variable aumenta, la otra tiende a disminuir. Por ejemplo, cuanto más se falta a clase, peor suele ser el rendimiento académico.
- Una correlación nula o cercana a cero significa que no hay una relación lineal clara entre las variables.
Por ejemplo, existe una fuerte correlación positiva entre el consumo de helado y el número de personas que se ahogan en la playa. ¿Significa esto que el helado causa ahogamientos? Claro que no. Lo que ocurre es que ambas variables aumentan durante los meses de verano, lo que nos lleva a…
El tercer factor: la variable oculta
A menudo, dos variables pueden estar correlacionadas porque ambas están influenciadas por una tercera variable que no se ha considerado. En el ejemplo anterior, esa tercera variable es la temperatura que se da en la estación del año (verano). Este tipo de confusión es una de las principales razones por las que la correlación no debe interpretarse como causalidad.
¿Qué es la causalidad?
La causalidad implica una relación directa entre dos eventos: uno provoca el otro. En otras palabras, un cambio en una variable produce un cambio en otra.
Por ejemplo, si en un estudio bien diseñado se demuestra que un medicamento reduce la presión arterial, podemos decir que el medicamento causa esa reducción.
La causalidad es mucho más difícil de demostrar que la correlación. Para poder establecerla con certeza, es necesario que se cumplan ciertas condiciones:
- Relación temporal: la causa debe preceder al efecto.
- Relación estadística: debe haber alguna asociación entre las variables.
- Eliminación de explicaciones alternativas: se deben descartar otras variables que puedan explicar el fenómeno.
Esto requiere experimentos bien controlados o técnicas estadísticas avanzadas que puedan simular las condiciones de un experimento, como los modelos de regresión, métodos de control instrumental, análisis de series temporales, o los experimentos naturales y cuasi-experimentos.
Ejemplos clásicos de confusión entre correlación y causalidad
Veamos ahora algunos ejemplos clásicos (y bastante curiosos) en los que se confunde la existencia de una correlación estadística con una relación de causa y efecto.
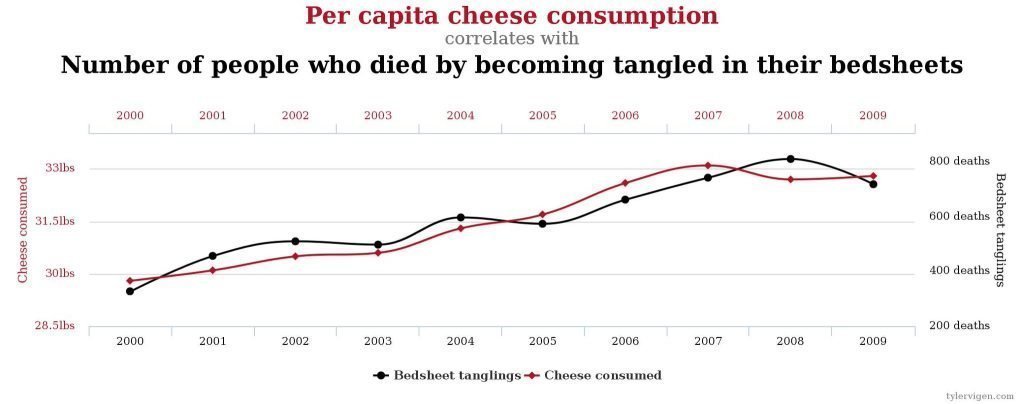
Consumo de queso y muertes por asfixia en la cama
En Estados Unidos, se ha observado una fuerte correlación entre el consumo per cápita de queso y el número de personas que mueren asfixiadas en su cama. A todas luces, es absurdo pensar que el queso provoca asfixias nocturnas. Este es un claro ejemplo de correlación espuria, donde dos variables parecen relacionadas, pero en realidad están influidas por otros factores o simplemente coinciden por azar.
Películas de Nicolas Cage y ahogamientos en piscinas
Otro caso famoso es la correlación entre el número de películas estrenadas por Nicolas Cage y la cantidad de personas que mueren ahogadas en piscinas en un año determinado. Aunque la correlación es estadísticamente significativa, no existe una relación causal plausible entre estos dos fenómenos.
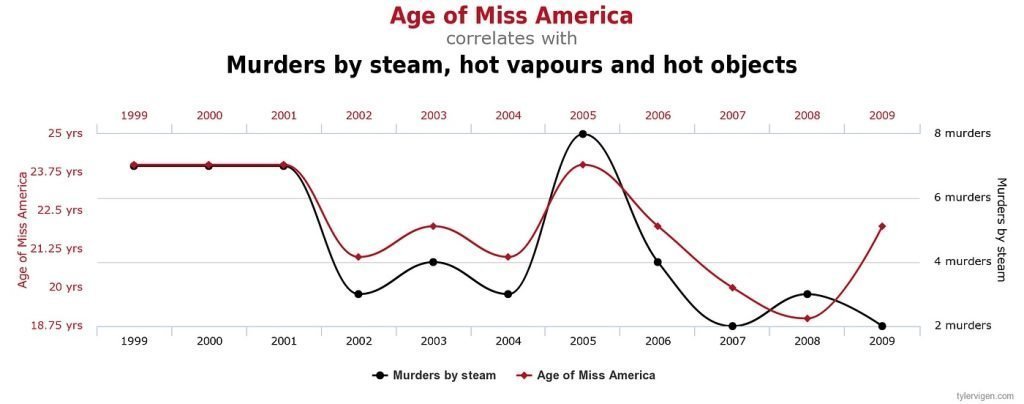
Edad de Miss América y asesinatos por vapor caliente
Entre 1999 y 2009, se observó una sorprendente correlación entre la edad de la ganadora de Miss América y el número de personas asesinadas por vapor, gases calientes y objetos calientes en Estados Unidos. Aunque las líneas de tendencia coinciden notablemente, es evidente que no existe una relación causal entre estos dos fenómenos.
Los tres ejemplos pueden encontrarse en este recopilatorio de correlaciones espurias. Además, hay muchos ejemplos humorísticos similares en la web Spurious Correlations, que ilustran de forma divertida lo fácil que es encontrar correlaciones llamativas… y lo peligroso que puede ser interpretarlas sin un análisis crítico.
¿Por qué confundimos correlación con causalidad?
La confusión entre correlación y causalidad es muy común, y no es solo un problema de falta de rigor académico. Existen varias razones, tanto cognitivas como culturales, que explican por qué tendemos a caer en este error:
- Nuestra mente busca patrones: desde una perspectiva evolutiva, nuestro cerebro está diseñado para detectar relaciones de causa y efecto rápidamente. Este instinto ha sido clave para nuestra supervivencia: si comías una fruta y luego te enfermabas, lo prudente era evitar esa fruta en el futuro, aunque no fuera la causa real. Sin embargo, este atajo mental puede fallar cuando enfrentamos sistemas complejos donde muchas variables interactúan entre sí.
- Los medios de comunicación simplifican los hallazgos científicos: titulares como “Beber vino mejora la memoria” o “Comer chocolate ayuda a bajar de peso” captan la atención y se comparten fácilmente. Pero detrás de esos titulares suele haber estudios observacionales, asociaciones débiles o resultados con múltiples matices que se pierden en la simplificación mediática. Esta distorsión puede reforzar la falsa impresión de causalidad.
- Falta de formación estadística: muchos lectores (y a veces incluso comunicadores o responsables de políticas) no tienen la formación necesaria para interpretar adecuadamente conceptos como correlación, sesgo de selección, regresión a la media, o intervalos de confianza. Esta carencia facilita malentendidos y decisiones basadas en evidencia mal interpretada.
Cómo identificar relaciones causales correctamente
A diferencia de la correlación, que puede detectarse fácilmente con un simple coeficiente estadístico, identificar una relación causal requiere mucho más trabajo y cuidado. El hecho de que dos variables se mueven juntas no implica que una cause a la otra. Para establecer causalidad es necesario aplicar métodos rigurosos que minimicen sesgos y confusiones. Algunos enfoques clave son los siguientes:
- Diseño experimental: los ensayos clínicos aleatorizados (randomized controlled trials, RCTs) son el estándar de oro para establecer relaciones causales. Consisten en asignar aleatoriamente tratamientos a distintos grupos y comparar los resultados. La aleatorización ayuda a distribuir equitativamente las variables de confusión, reduciendo el riesgo de sesgos.
- Estudios longitudinales: observar a los sujetos a lo largo del tiempo permite identificar si un evento precede a otro, lo cual es un requisito para la causalidad. Estos estudios son especialmente útiles en epidemiología y ciencias sociales, donde los experimentos controlados no siempre son viables.
- Análisis multivariable: utilizando modelos estadísticos que controlan por múltiples factores (como regresión múltiple), es posible aislar el efecto de una variable sobre otra, controlando por posibles variables de confusión. Sin embargo, esto requiere datos de buena calidad y una correcta especificación del modelo.
- Técnicas como variables instrumentales: cuando no se puede experimentar directamente, se pueden usar variables instrumentales: variables que están relacionadas con la causa pero no con el efecto directamente, excepto a través de esa causa. Esta técnica permite obtener estimaciones causales en presencia de variables no observadas que podrían sesgar los resultados.
- Experimentos naturales: en algunos casos, eventos externos (como cambios en leyes o políticas públicas) generan condiciones que se asemejan a un experimento aleatorizado. Estos experimentos naturales pueden ser aprovechados para inferir causalidad si se analiza correctamente el contexto.
Consecuencias reales de confundir correlación con causalidad
Confundir correlación con causalidad no es solo un error teórico: puede tener consecuencias negativas reales en distintos ámbitos de la sociedad. Algunos ejemplos incluyen:
- Salud pública: asumir que un alimento, hábito o sustancia causa una enfermedad solo porque están correlacionados puede generar alarmas infundadas o incluso decisiones médicas erróneas. Esto puede conducir a dietas ineficaces, miedo innecesario o desconfianza en la ciencia.
- Políticas públicas: implementar programas o leyes costosas basadas en correlaciones sin respaldo causal puede significar una mala asignación de recursos, con intervenciones poco efectivas o contraproducentes.
- Decisiones personales: adoptar suplementos, rutinas o productos por haber leído que “están relacionados con” beneficios o riesgos, sin entender si hay causalidad detrás, puede ser inútil, caro, o incluso perjudicial para la salud o el bienestar.
En todos estos casos, actuar sin evidencia causal sólida puede acarrear consecuencias serias, tanto para individuos como para comunidades enteras.

Recomendaciones para lectores críticos
Vivimos rodeados de titulares llamativos, gráficos impactantes y estudios que se viralizan con facilidad. Para evitar caer en interpretaciones erróneas, aquí van algunas recomendaciones para pensar con espíritu crítico:
- Pregunta siempre: ¿podría haber otra explicación para esta correlación? ¿Puede haber una tercera variable involucrada?
- Examina el diseño del estudio: ¿se trata de un estudio observacional o experimental? ¿Hubo control de variables?
- Desconfía de las coincidencias sorprendentes: si la relación parece demasiado extraña o graciosa para ser verdad… probablemente lo sea.
- Lee más allá del titular: muchas veces los títulos exageran o simplifican; en el cuerpo del artículo se suelen incluir matices importantes.
- Consulta fuentes confiables: prioriza medios especializados, literatura científica, y divulgadores con formación en el tema.
Conclusiones
En un mundo donde los datos están en todas partes, es esencial aprender a pensar con claridad. Comprender la diferencia entre correlación y causalidad es un paso crucial hacia una ciudadanía informada y un pensamiento crítico más agudo. No todo lo que ocurre al mismo tiempo está relacionado causalmente, y no todo lo que se presenta como verdad en un gráfico lo es. Cultivar esta capacidad analítica nos permite distinguir entre hechos y coincidencias, tomar mejores decisiones y evitar manipulaciones estadísticas.
Así que la próxima vez que veas una afirmación como “quienes toman café tienen más éxito profesional”, recuerda hacerte esta simple pero importante pregunta: ¿correlación o causalidad?
Nota: Las imágenes de este artículo fueron generadas utilizando un modelo de inteligencia artificial.
Deja una respuesta