Llevas un rato analizando datos y tienes cuatro gráficos abiertos en ventanas separadas: ventas, usuarios, conversión e ingresos. Para comparar cualquier par de ellos tienes que cambiar de ventana, recordar lo que acabas de ver y volver. Tu cerebro está haciendo el trabajo que debería hacer el gráfico.
La solución es tan simple como reunirlos todos en una sola figura usando subplots. En esta entrada verás cómo hacerlo en Matplotlib, desde el caso más básico hasta patrones avanzados como compartir ejes, iterar sobre subplots y construir un dashboard funcional.
Tabla de contenidos
- 1 Dos formas de crear subplots en Matplotlib: cuál usar y cuándo
- 2 Cuadrículas de múltiples filas y columnas
- 3 Compartir ejes para comparaciones justas
- 4 Iterar sobre subplots para código más limpio
- 5 Ajuste fino del espacio entre subplots
- 6 Caso práctico completo: dashboard de métricas
- 7 Errores comunes y cómo evitarlos
- 8 Resumen: cuándo y cómo usar subplots
- 9 Conclusiones
Dos formas de crear subplots en Matplotlib: cuál usar y cuándo
Matplotlib ofrece dos funciones para crear múltiples gráficos: plt.subplot() y plt.subplots(). No son lo mismo y no se usan igual.
plt.subplot(): la forma básica
import matplotlib.pyplot as plt
plt.subplot(1, 2, 1) # 1 fila, 2 columnas, posición 1
plt.plot([1, 2, 3], [10, 15, 20])
plt.title("Gráfico 1")
plt.subplot(1, 2, 2) # 1 fila, 2 columnas, posición 2
plt.bar(['A', 'B', 'C'], [5, 7, 3])
plt.title("Gráfico 2")
plt.show()
La sintaxis plt.subplot(filas, columnas, índice) crea una cuadrícula y activa uno de sus huecas. Cada vez que llamas a la función, el siguiente comando de dibujo se aplica al subplot activo.

El problema es que este enfoque es implícito: dependes de cuál de los dos subplot esté “activo” en cada momento, lo que se vuelve confuso rápidamente en cuanto el código crece. Si añades o reordenas gráficos, es fácil que los índices de estos queden descolocados.
plt.subplots(): el enfoque recomendado
fig, ax = plt.subplots(1, 2)
ax[0].plot([1, 2, 3], [10, 15, 20])
ax[0].set_title("Líneas")
ax[1].bar(['A', 'B', 'C'], [5, 7, 3])
ax[1].set_title("Barras")
plt.show()
Esta función devuelve dos objetos: fig (la figura completa) y ax (los ejes individuales). En lugar de activar un subplot implícitamente, accedes a cada uno por su posición en el array ax. El código es más explícito, más fácil de depurar y escala mucho mejor.
Por eso, en esta entrada, usaremos siempre la segunda opción, plt.subplots(), al ser más escalable y fácil de entender.
Nota sobre la nomenclatura: en Matplotlib, un eje (ax) es el área de dibujo de un gráfico individual, con sus propios ejes X e Y, título y leyenda. La figura (fig) es el contenedor que los agrupa todos. Esta distinción es importante porque cada objeto tiene sus propios métodos: ax.set_title() afecta a un gráfico, fig.suptitle() afecta a toda la figura.
Cuadrículas de múltiples filas y columnas
El uso más habitual de los subplots es organizar gráficos en una cuadrícula de filas y columnas. Esto es la base de cualquier dashboard simple.
import matplotlib.pyplot as plt
import numpy as np
fig, ax = plt.subplots(2, 2, figsize=(10, 8))
x = [1, 2, 3, 4, 5]
ax[0, 0].plot(x, [v**2 for v in x], color='steelblue')
ax[0, 0].set_title("Crecimiento cuadrático")
ax[0, 1].plot(x, [v**3 for v in x], color='darkorange')
ax[0, 1].set_title("Crecimiento cúbico")
ax[1, 0].bar(['A', 'B', 'C', 'D'], [3, 5, 2, 6], color='seagreen')
ax[1, 0].set_title("Comparación por categoría")
ax[1, 1].scatter(np.random.rand(20), np.random.rand(20), color='tomato')
ax[1, 1].set_title("Dispersión aleatoria")
plt.tight_layout()
plt.show()
Cuando plt.subplots() recibe dos argumentos (filas y columnas), ax se convierte en una matriz bidimensional. Accedes a cada subplot con dos índices: ax[fila, columna], donde ambos empiezan en 0.
La distribución espacial es intuitiva:
| Posición | Índice |
|---|---|
| Arriba izquierda | ax[0, 0] |
| Arriba derecha | ax[0, 1] |
| Abajo izquierda | ax[1, 0] |
| Abajo derecha | ax[1, 1] |
figsize=(10, 8) controla las dimensiones de la figura completa en pulgadas. Con cuatro subplots, el tamaño por defecto suele ser demasiado pequeño y los títulos o etiquetas quedan cortados. Un buen punto de partida es multiplicar el número de columnas por 4–5 y el de filas por 3–4.
plt.tight_layout() ajusta automáticamente los márgenes entre subplots para que no se solapen. Sin esta llamada, es frecuente que los títulos de una fila choquen con los ejes de la fila de arriba. Inclúyela siempre antes de plt.show().
Compartir ejes para comparaciones justas
Uno de los errores más comunes en visualización es comparar gráficos con escalas distintas. Si el gráfico de ventas va de 0 a 100 y el de usuarios va de 0 a 10.000, una subida del 10 % parece idéntica visualmente cuando en realidad representa magnitudes completamente distintas.
Matplotlib permite resolver esto con los parámetros sharex y sharey.
Compartir el eje Y (misma escala vertical)
fig, ax = plt.subplots(1, 3, sharey=True, figsize=(12, 4))
meses = ['Ene', 'Feb', 'Mar', 'Abr', 'May']
ax[0].plot(meses, [10, 12, 15, 14, 18], marker='o', color='steelblue')
ax[0].set_title("Canal A")
ax[1].plot(meses, [8, 11, 13, 16, 15], marker='s', color='darkorange')
ax[1].set_title("Canal B")
ax[2].plot(meses, [12, 14, 11, 18, 20], marker='^', color='seagreen')
ax[2].set_title("Canal C")
plt.tight_layout()
plt.show()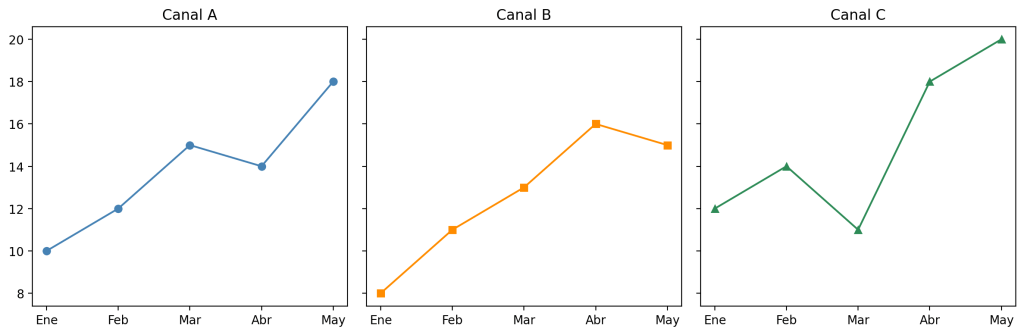
Con sharey=True, los tres subplots usan exactamente la misma escala vertical. Ahora una subida que parece grande en un gráfico también lo parece en los otros, y una diferencia pequeña se ve pequeña en todos. La comparación es honesta.
Cuando compartes ejes, Matplotlib elimina automáticamente las etiquetas numéricas redundantes: en una cuadrícula con sharey=True, solo el subplot de la izquierda mostrará los valores del eje Y. Esto reduce el ruido visual sin perder información.
Compartir el eje X (misma escala temporal)
fig, ax = plt.subplots(3, 1, sharex=True, figsize=(8, 8))
meses = ['Ene', 'Feb', 'Mar', 'Abr', 'May']
ax[0].plot(meses, [100, 120, 140, 130, 160], color='steelblue')
ax[0].set_title("Ventas")
ax[0].set_ylabel("Unidades")
ax[1].plot(meses, [50, 55, 60, 58, 70], color='darkorange')
ax[1].set_title("Usuarios activos")
ax[1].set_ylabel("Personas")
ax[2].plot(meses, [2.1, 2.3, 2.5, 2.4, 2.8], color='seagreen')
ax[2].set_title("Tasa de conversión")
ax[2].set_ylabel("%")
plt.tight_layout()
plt.show()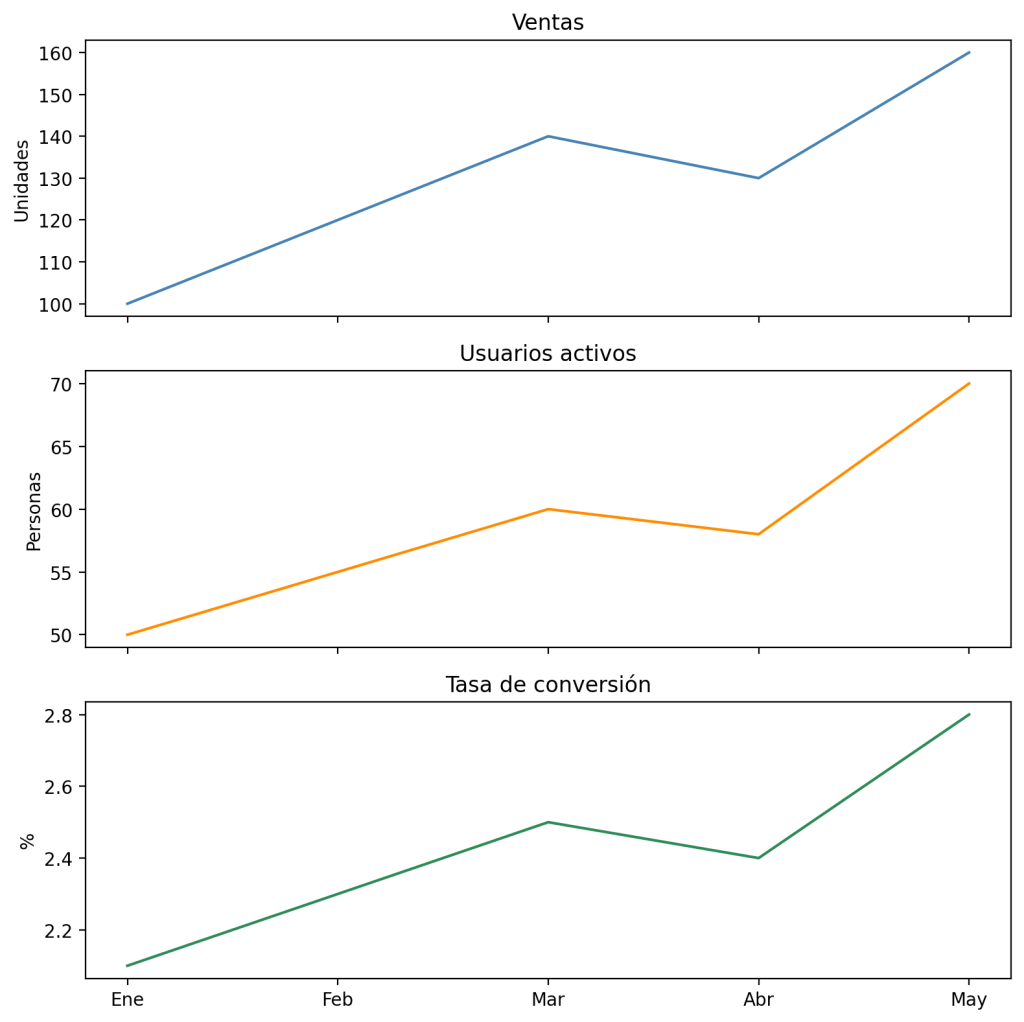
Este patrón es especialmente útil cuando quieres ver cómo evolucionan varias métricas distintas en el mismo periodo de tiempo. Con sharex=True, las columnas del eje X están perfectamente alineadas entre los tres subplots, así que puedes leer verticalmente y ver qué ocurrió en cada mes en todas las métricas a la vez.
Iterar sobre subplots para código más limpio
Cuando tienes muchos subplots con contenido similar, escribir ax[0, 0], ax[0, 1]… manualmente se vuelve repetitivo y propenso a errores. La solución es iterar.
Con ax.flatten()
import numpy as np
import matplotlib.pyplot as plt
datasets = [
([1, 2, 3, 4, 5], [v**1.5 for v in range(1, 6)], 'Raíz 1.5'),
([1, 2, 3, 4, 5], [v**2 for v in range(1, 6)], 'Cuadrado'),
([1, 2, 3, 4, 5], [v**2.5 for v in range(1, 6)], 'Raíz 2.5'),
([1, 2, 3, 4, 5], [v**3 for v in range(1, 6)], 'Cubo'),
]
fig, ax = plt.subplots(2, 2, figsize=(10, 7))
for axis, (x, y, titulo) in zip(ax.flatten(), datasets):
axis.plot(x, y, marker='o')
axis.set_title(titulo)
axis.grid(True, linestyle='--', alpha=0.5)
plt.tight_layout()
plt.show()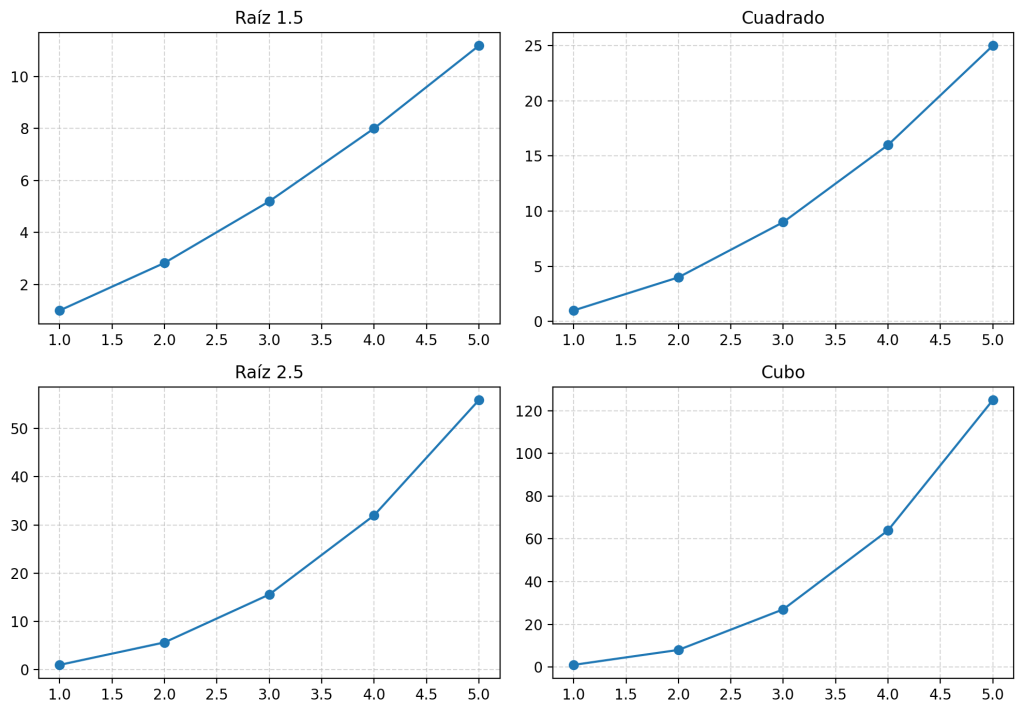
ax.flatten() convierte la matriz bidimensional de ejes en un array unidimensional, lo que permite recorrerla con un bucle for. Combinado con zip(), puedes emparejar cada subplot con sus datos en una sola línea.
Este patrón escala muy bien: si mañana tienes seis datasets en lugar de cuatro, solo tienes que cambiar plt.subplots(2, 2) por plt.subplots(2, 3) y añadir dos elementos a la lista. El bucle no cambia.
Deshabilitar subplots vacíos
Si el número de datasets no es un múltiplo exacto del número de subplots, algunos quedarán vacíos. Para ocultarlos en lugar de dejar un recuadro en blanco:
for axis in ax.flatten()[len(datasets):]:
axis.set_visible(False)Ajuste fino del espacio entre subplots
plt.tight_layout() resuelve la mayoría de los problemas de solapamiento automáticamente, pero a veces necesitas más control.
subplots_adjust
plt.subplots_adjust(hspace=0.4, wspace=0.3)
hspace: espacio vertical entre filas (en fracción de la altura de cada subplot). Un valor de0.4equivale al 40 % de la altura de un subplot.wspace: espacio horizontal entre columnas. Funciona igual pero en anchura.
No mezcles tight_layout() con subplots_adjust() en el mismo gráfico; pueden interferir entre sí. Elige uno de los dos enfoques.
Título general de la figura
Cuando tienes varios subplots que forman un análisis conjunto, puedes añadir un título a la figura completa (no a cada subplot individualmente):
fig.suptitle("Dashboard de métricas mensuales", fontsize=14, fontweight='bold')
plt.tight_layout(rect=[0, 0, 1, 0.96]) # Deja espacio para el título superiorEl parámetro rect en tight_layout() define el área disponible para los subplots como fracción de la figura: [izquierda, abajo, derecha, arriba]. Al usar 0.96 como límite superior, dejamos un 4 % de margen para que el título de la figura no se solape con los gráficos.
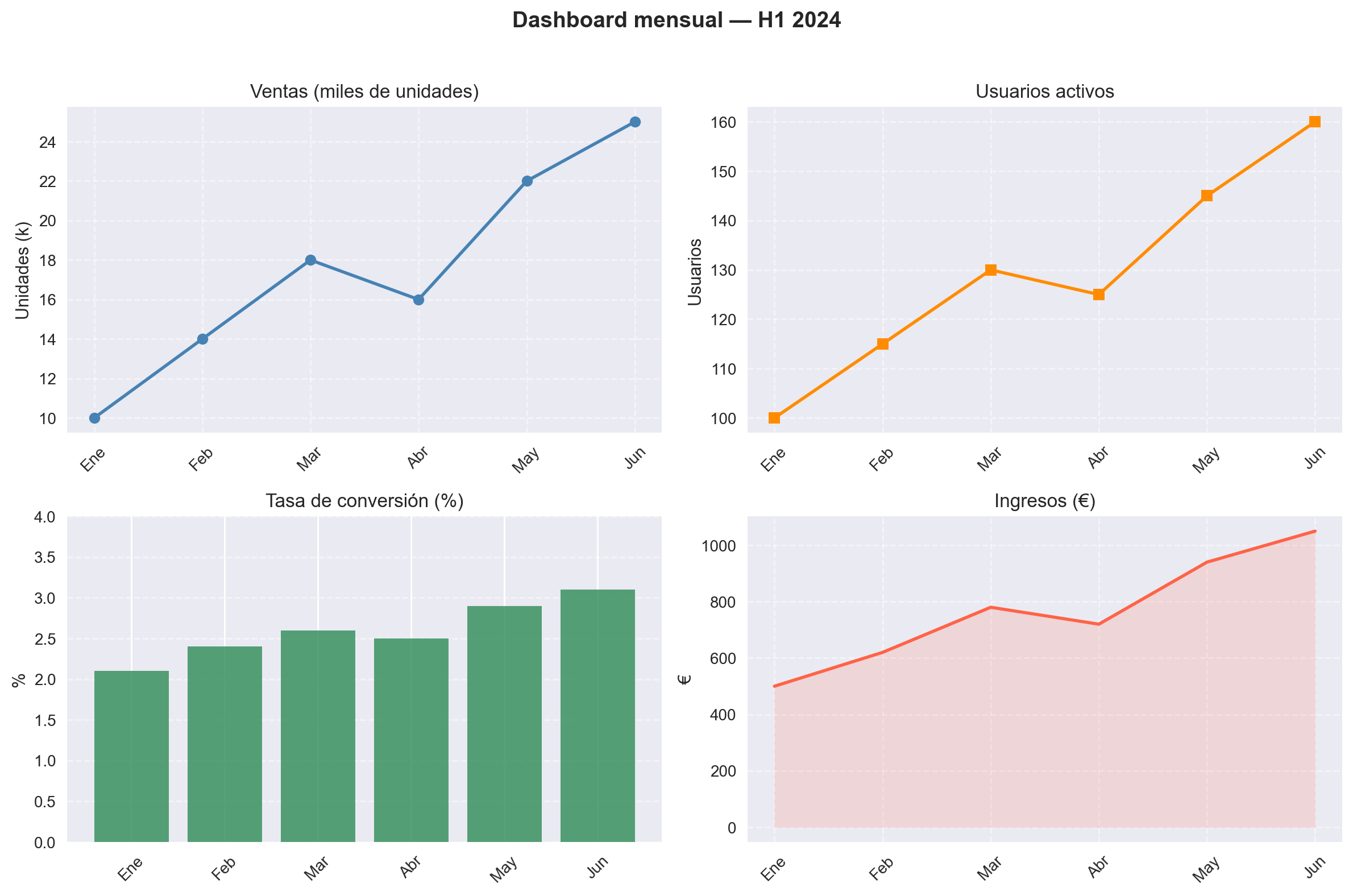
Caso práctico completo: dashboard de métricas
Reunamos todo en un ejemplo realista: un dashboard de cuatro métricas con ejes compartidos donde corresponde, títulos claros y un buen diseño visual.
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('seaborn-v0_8')
meses = ['Ene', 'Feb', 'Mar', 'Abr', 'May', 'Jun']
ventas = [10, 14, 18, 16, 22, 25]
usuarios = [100, 115, 130, 125, 145, 160]
conversion = [2.1, 2.4, 2.6, 2.5, 2.9, 3.1]
ingresos = [500, 620, 780, 720, 940, 1050]
fig, ax = plt.subplots(2, 2, figsize=(12, 8))
fig.suptitle("Dashboard mensual — H1 2024", fontsize=14, fontweight='bold')
# Ventas
ax[0, 0].plot(meses, ventas, marker='o', color='steelblue', linewidth=2)
ax[0, 0].set_title("Ventas (miles de unidades)")
ax[0, 0].set_ylabel("Unidades (k)")
ax[0, 0].grid(True, linestyle='--', alpha=0.5)
# Usuarios activos
ax[0, 1].plot(meses, usuarios, marker='s', color='darkorange', linewidth=2)
ax[0, 1].set_title("Usuarios activos")
ax[0, 1].set_ylabel("Usuarios")
ax[0, 1].grid(True, linestyle='--', alpha=0.5)
# Tasa de conversión (barras, no líneas, porque es una métrica por periodo)
ax[1, 0].bar(meses, conversion, color='seagreen', alpha=0.8)
ax[1, 0].set_title("Tasa de conversión (%)")
ax[1, 0].set_ylabel("%")
ax[1, 0].set_ylim(0, 4)
ax[1, 0].grid(axis='y', linestyle='--', alpha=0.5)
# Ingresos con área sombreada
ax[1, 1].plot(meses, ingresos, color='tomato', linewidth=2)
ax[1, 1].fill_between(meses, ingresos, alpha=0.15, color='tomato')
ax[1, 1].set_title("Ingresos (€)")
ax[1, 1].set_ylabel("€")
ax[1, 1].grid(True, linestyle='--', alpha=0.5)
# Rotar etiquetas del eje X en todos los subplots
for axis in ax.flatten():
axis.tick_params(axis='x', rotation=45)
plt.tight_layout(rect=[0, 0, 1, 0.96])
plt.show()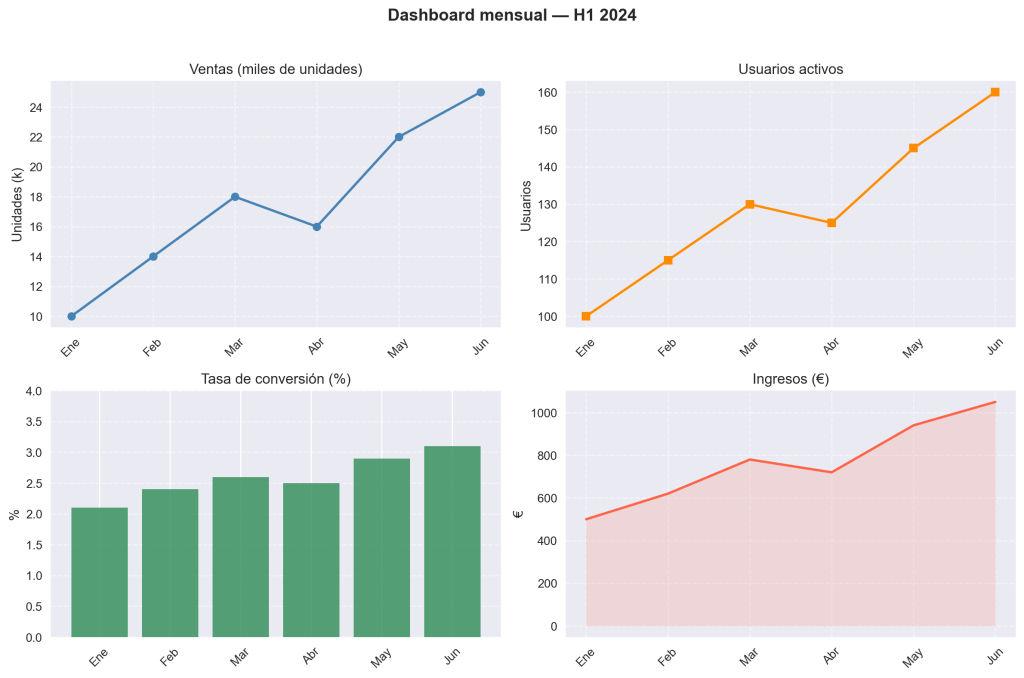
Este ejemplo introduce una técnica adicional: ax.fill_between(), que rellena el área bajo una línea. Es muy útil para métricas acumuladas o para añadir énfasis visual a la tendencia sin necesidad de texto adicional.
Errores comunes y cómo evitarlos
A la hora de crear gráficos es importante evitar ciertos problemas que pueden tierra todo el trabajo. En el caso de lo subplots es importante evitar:
- Usar
plt.subplot()en código que va a crecer: La versión con índice implícito es difícil de mantener. En cuanto añades, eliminas o reordenas subplots, los índices se descolocan. Usa siempreplt.subplots()y accede a los ejes por nombre. - Olvidar
plt.tight_layout(): Sin este ajuste, los títulos de una fila se superponen con los ejes de la fila siguiente. Es un error tan frecuente que conviene añadirplt.tight_layout()por defecto en todos los gráficos con subplots, aunque aparentemente no haga falta. - No compartir ejes cuando los datos son comparables: Si muestras la evolución de ventas de dos canales distintos sin
sharey=True, una escala de 0–100 en uno y 0–1000 en el otro hace que tendencias idénticas parezcan completamente distintas. Comparte siempre el eje relevante cuando la comparación directa sea el objetivo. - Demasiados subplots en una figura: Una cuadrícula de 4×4 con dieciséis gráficos suele ser ilegible en pantalla y completamente inútil impresa. A partir de 6 subplots, considera dividirlos en varias figuras, usar pequeños múltiplos (facets) con una librería como Seaborn, o priorizar las métricas más importantes.
- Mezclar
tight_layout()ysubplots_adjust()
Estas dos funciones pueden interferir entre sí. Elige una:tight_layout()para el caso general,subplots_adjust()cuando necesites control milimétrico del espaciado.
Resumen: cuándo y cómo usar subplots
| Situación | Solución |
|---|---|
| Dos o tres gráficos para comparar | plt.subplots(1, N) con sharey=True |
| Dashboard de métricas distintas | plt.subplots(2, 2) con tight_layout() |
| Misma variable en múltiples grupos | Bucle con ax.flatten() |
| Métricas en el mismo periodo | plt.subplots(N, 1, sharex=True) |
| Título general para la figura | fig.suptitle() con rect en tight_layout() |
Conclusiones
Los subplots son el puente entre hacer un gráfico y construir un análisis visual. En cuanto tienes más de una métrica que contar, organizarlas en una sola figura con escalas coherentes y ejes bien alineados hace que la historia que cuentan los datos sea inmediatamente visible.
La clave, como siempre, es empezar por la pregunta: ¿qué quieres que el lector compare? Si son magnitudes del mismo tipo, comparte el eje Y. Si son evoluciones en el mismo periodo, comparte el eje X. Si son métricas distintas que se influyen entre sí, ponlas en columnas o filas alineadas. El código vendrá solo una vez que tengas clara la respuesta.
Deja una respuesta