
Cuando importamos un conjunto de datos para un análisis es habitual que los registros no estén como los necesitamos. Uno de estos casos es cuando en alguna de las columnas contiene más de un valor que necesitamos procesar por separados. Como puede ser el nombre completo o una lista de características. En esto casos se pueden utilizar el método .str.split que se puede encontrar en todas la columnas de un DataFrame. Con lo que se puede separar fácilmente el texto en columnas con Pandas.
Conjunto de datos de ejemplo
En esta situación vamos a trabajar con un conjunto de datos de ejemplo generados en Mockaroo los cuales contienen el nombre, título, correo electrónico y huso horario de unos usuarios. Conjunto de datos que importamos en Pandas con el siguiente código:
import pandas as pd
df = pd.read_csv('MOCK_DATA.csv')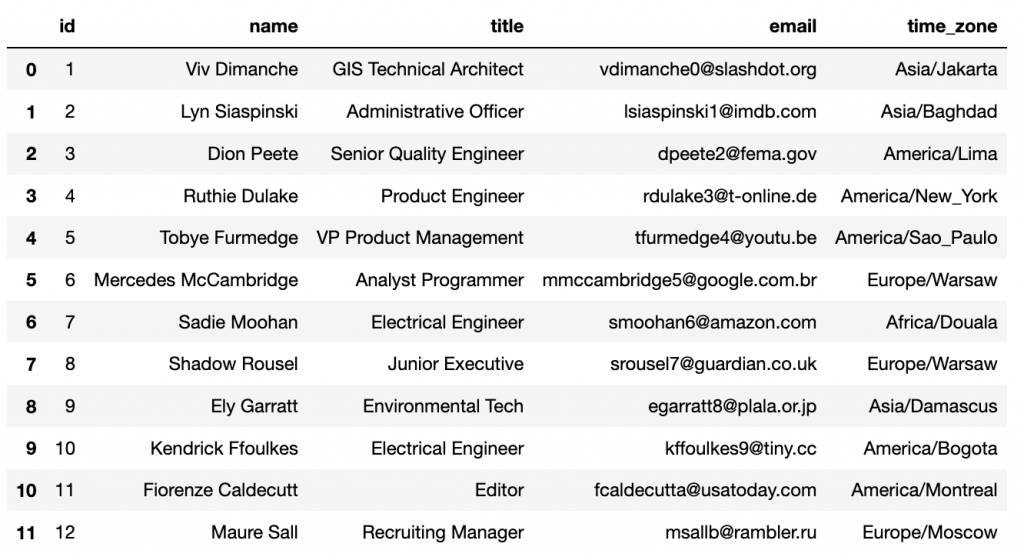
Separar nombre y apellido
Lo primero que se puede observar en este conjunto de datos es que en la columna name del DataFrame se encuentra el nombre y el apellido cada uno de los usuarios. Para separarlos podemos usar directamente la función .str.split() para obtener el siguiente resultado.

df["name"].str.split()
0 [Viv, Dimanche] 1 [Lyn, Siaspinski] 2 [Dion, Peete] 3 [Ruthie, Dulake] 4 [Tobye, Furmedge] 5 [Mercedes, McCambridge] 6 [Sadie, Moohan] 7 [Shadow, Rousel] 8 [Ely, Garratt] 9 [Kendrick, Ffoulkes] 10 [Fiorenze, Caldecutt] 11 [Maure, Sall]
En el que se ha obtenido una serie de listas de valores. En cada uno de los elementos de la serie se tiene una lista de dos elementos con el nombre y apellido de los usuarios. Pero normalmente vamos a querer una Data Frame en lugar de una lista. Lo que se puede conseguir con la propiedad adecuada en la función.
Generar un nuevo Data Frame con los valores separados
Para obtener un DataFrame en lugar de una lista como resultado del método .str.split() es necesario indicar que la propiedad expand sea verdadera. Obteniendo el siguiente resultado.
df["name"].str.split(expand=True)
0 1 0 Viv Dimanche 1 Lyn Siaspinski 2 Dion Peete 3 Ruthie Dulake 4 Tobye Furmedge 5 Mercedes McCambridge 6 Sadie Moohan 7 Shadow Rousel 8 Ely Garratt 9 Kendrick Ffoulkes 10 Fiorenze Caldecutt 11 Maure Sall
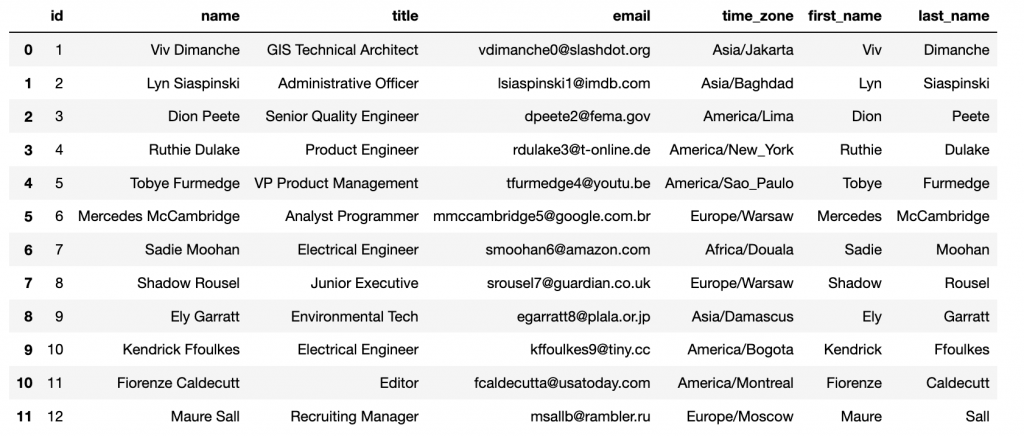
Ahora podemos combinar este nuevo Data Frame con el original para obtener un único objeto con todos los datos.
name = df["name"].str.split(expand=True) name.columns = ['first_name', 'last_name'] df = pd.concat([df, name], axis=1) df
Utilizar otros separadores
Por defecto el método .str.split() separa las cadenas de texto utilizando el espacio. Pero no siempre es lo que deseamos. Por eso se puede indicar la cadena de texto que utilizados para separar como una propiedad de la función. Algo que se puede aplicar a la zona horaria, donde tenemos el continente y la ciudad separada por /. Así podemos separar ambos valores mediante el siguiente código
df["time_zone"].str.split('/', expand=True)0 1 0 Asia Jakarta 1 Asia Baghdad 2 America Lima 3 America New_York 4 America Sao_Paulo 5 Europe Warsaw 6 Africa Douala 7 Europe Warsaw 8 Asia Damascus 9 America Bogota 10 America Montreal 11 Europe Moscow
Utilizar más de un separador
Finalmente, si queremos utilizar más de un separador se puede conseguir indicando todos los separadores entre corchetes. En el conjunto de datos de ejemplo esto se puede usar en las direcciones de correo para obtener todos los subdominios y separar además el nombre. Algo que se puede ver en el siguiente ejemplo.
df["email"].str.split('[.@]', expand=True)0 1 2 3 0 vdimanche0 slashdot org None 1 lsiaspinski1 imdb com None 2 dpeete2 fema gov None 3 rdulake3 t-online de None 4 tfurmedge4 youtu be None 5 mmccambridge5 google com br 6 smoohan6 amazon com None 7 srousel7 guardian co uk 8 egarratt8 plala or jp 9 kffoulkes9 tiny cc None 10 fcaldecutta usatoday com None 11 msallb rambler ru None
En este caso se pude ver que cuando el número de valores que se obtiene en un fila es diferente, el Data Frame resultante es de la longitud mayor y el resto de valores se completan con None.
Conclusiones
El método .str.split de las series Pandas es útil para poder separar texto en columnas en Python. Un recursos que puede solucionar muchos problemas durante el preprocesado de los datos.
Imagen de Manfred Antranias Zimmer en Pixabay
Muy bueno! me ayudó con mi practica