Los gráficos de cascada (Waterfall charts) son una herramienta para visualizar de una forma sencilla cómo se acumulan los valores positivos y negativos en una serie de datos. Pudiendo ofrecer en algunos casos más información que los gráficos de barras o líneas. Actualmente no existe en Matplotlib o Seaborn una forma sencilla de crear estos gráficos, pero existen otros paquetes como waterfallcharts que si lo implementan en Python.
Instalación de waterfallcharts en Python
Dado que actualmente no existe una función ni en Matplotlib ni en Seaborn con la que se pueda crear fácilmente un gráfico de cascada en Python es necesario recurrir a otros paquetes. Uno de los más sencillos de usar es waterfallcharts que se puede instalar a través de PyPI abriendo una terminal o símbolo de sistema y ejecutando el siguiente comando
pip install waterfallcharts
Una vez hecho eso ya se podrá usar la librería para crear este tipo de gráficos.
Ver la evolución de un valor a lo largo del tiempo en una gráfica
Supongamos que se dispone de los valores de una variable a lo largo del tiempo y se desea comprobar su evolución. Saber los meses en los que el valor ha subido o ha bajado. Para lo que se puede recurrir a una gráfica de líneas. Por ejemplo, tal como se hace en el siguiente código.

import matplotlib.pyplot as plt # Importación de la serie de datos month = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'] value = [27.66, 26.03, 20.52, 24.57, 28.55, 27.11, 28.72, 22.81, 23.33, 27.99, 28.45, 24.72] # Creación del gráfico plt.plot(month, value) # Mostrar el gráfico plt.show()

En este ejemplo se han definido dos vectores, uno con los meses y otro con la variable. Como se puede ver en la gráfica los valores de esta suben y bajan a lo largo del tiempo de una forma que parece aleatoria. En febrero baja, baja más en marzo para subir en abril y mayo. Así todo el año. En la gráfica se puede apreciar la tendencia, pero no los meses que suben y bajan los valores.
Alternativamente se puede probar con una gráfica de barras, pero el resultado no es mucho mejor como se puede ver el siguiente ejemplo.
# Creación de gráfico de barras plt.bar(month, value) # Mostrar el gráfico plt.show()

Los gráficos de cascada muestran la evolución de los datos
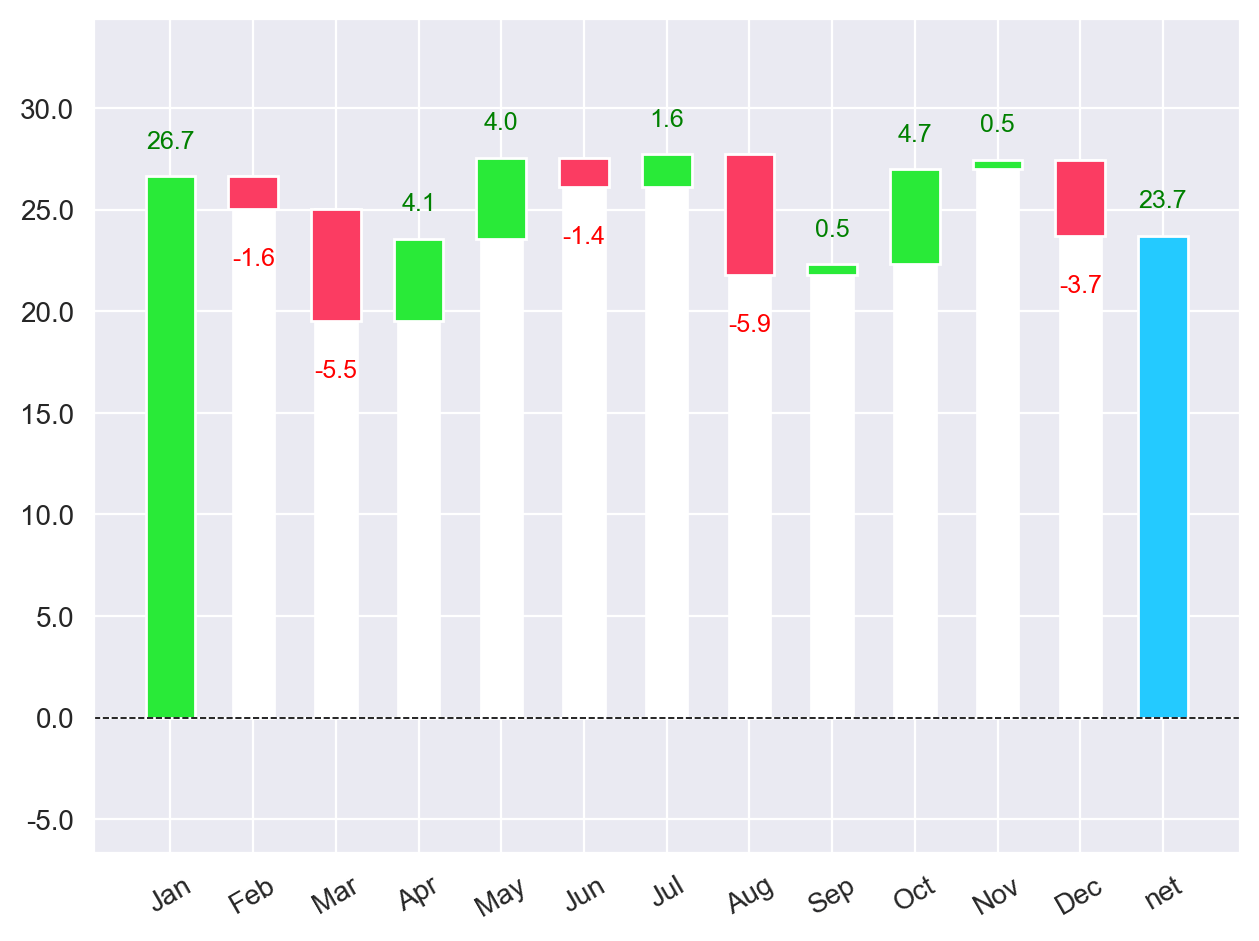
Una forma de poder ver la evolución de los datos es usar un gráfico de cascada, para lo que se ha instalado anteriormente la librería waterfall_chart. Ahora solo es necesario preparar los datos, importar la librería y llamar a la función plot() de esta. Lo que se hace en el siguiente código.
import numpy as np import waterfall_chart # Obtener la variación de datos para cada mes diff_value = np.diff(value, prepend=1) # Creación del gráfico de cascada waterfall_chart.plot(month, diff_value)

En este ejemplo lo primero que se hace es crear una variable con las diferencias de los valores para cada uno de los meses. Un paso necesario ya que este tipo de gráficos necesitan las variaciones de los valores. Para lo que se ha empleado la función np.diff() con la opción prepend, de modo que el primer valor del nuevo vector aparezca como valor inicial. Así se consigue que la variable con los meses (month) y la variable con la variación de los valores (diff_value) tenga el mismo tamaño. En caso contrario la salida de np.diff() tendría un registro menos, algo que provocaría que la función plot() devolviese un fallo. Posteriormente se crea la gráfica que se muestra.
Esta gráfica ofrece más información que las anteriores, se puede ver fácilmente cómo evoluciona el valor desde los 26,7 iniciales a los 23,7 finales comprobando cuánto se incrementa o reduce cada uno de los meses. Pudiendo ver de una manera sencilla los meses que han sido positivos o negativos y en qué grado. Algo que en muchos casos puede ser más interesante que las conclusiones extraídas de los gráficos anteriores.
Analizar las componentes de un valor con un gráfico de cascada
Otra utilidad de los gráficos de cascada es mostrar cuales son las componentes de un valor. Por ejemplo, si se dispone de los ingresos y gastos de un proyecto para ver cuál ha sido su beneficio neto. Lo que se muestra en el siguiente ejemplo.
concepto = ['Ingresos publicidad', 'Ingresos cuotas', 'Gastos fijos', 'Gastos variables', 'Impuestos'] cantidad = [12023, 3012, -8443, -1324, -1239] waterfall_chart.plot(concepto, cantidad)

En este caso, no es necesario diferenciar los valores ya que estos son datos originales son los que se usan para crear la gráfica.
Conclusiones
Los gráficos de cascada son una herramienta con la que se puede mostrar de forma clara la variación de los valores de una serie de datos. Ofreciendo esta información de una forma más precisa que los gráficos de barras o de líneas. Por eso, para los casos en lo que esto es lo que se desea es bueno contar con esta herramienta.
Deja una respuesta