Tienes los datos de tráfico web de los últimos cinco meses desglosados por canal: orgánico, pagado y directo. Quieres saber cuál está creciendo más rápido y si hay algún mes en que algo cambió. Un gráfico de barras te mostraría los valores puntuales, pero no la historia que hay detrás. Para eso necesitas un gráfico de líneas.
En esta entrada aprenderás a construir gráficos de líneas comparativos en Python con Matplotlib, desde el caso más simple hasta técnicas más avanzadas como el suavizado de series y las anotaciones. Al final encontrarás una guía rápida para saber cuándo usar líneas y cuándo usar barras.
¿Por qué un gráfico de líneas y no uno de barras?
Antes de escribir una sola línea de código, conviene entender cuándo tiene sentido usar cada tipo de gráfico. En el caso de los gráficos de líneas, la respuesta corta es: cuando existe una relación de continuidad entre los puntos del eje X.
En un gráfico de barras, cada barra es independiente. Tiene sentido comparar el volumen de ventas entre Producto A y Producto B porque son cosas distintas, sin relación entre sí.
En un gráfico de líneas, la línea que conecta los puntos tiene significado: implica que entre un valor y el siguiente hay una transición. Por eso son la herramienta natural para:

- Series temporales: ventas mensuales, temperatura diaria, visitas web por semana.
- Evolución de métricas: precisión de un modelo a lo largo de epochs de entrenamiento.
- Comparación de tendencias: ¿qué canal crece más rápido? ¿qué producto está en declive?
- Datos continuos: funciones matemáticas, señales físicas, distribuciones.
Si el eje X representa categorías sin orden natural (productos, países, departamentos), usa barras. Si representa tiempo o cualquier variable continua, usa líneas.
El gráfico de líneas básico
Empecemos por el caso más simple: una sola serie de datos.
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [10, 15, 13, 20, 18]
plt.plot(x, y)
plt.title("Evolución de ventas")
plt.xlabel("Periodo")
plt.ylabel("Ventas")
plt.show()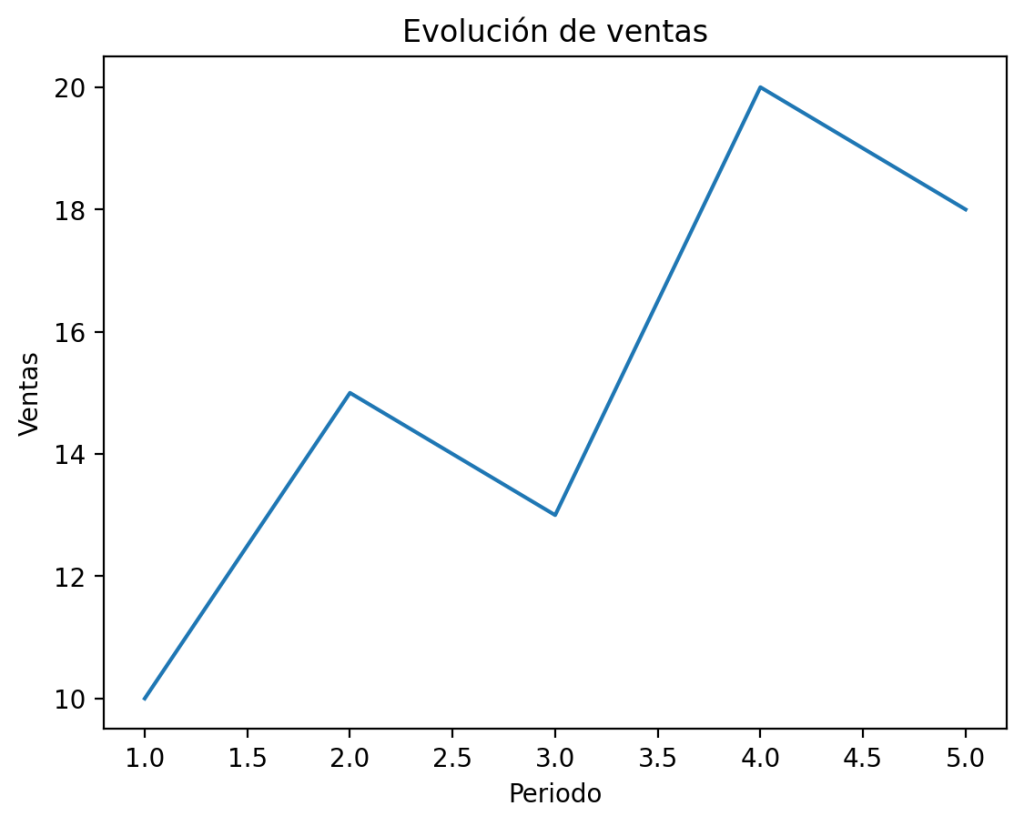
La función plt.plot() conecta automáticamente los puntos mediante una línea. Esto ya nos da información valiosa que no tendríamos en una tabla: podemos ver que las ventas suben, bajan en el periodo 3 y vuelven a recuperarse.
Pero un solo producto no cuenta toda la historia. El análisis se vuelve mucho más interesante cuando comparamos varias series a la vez.
Comparación de múltiples series
A diferencia de los gráficos de barras, donde necesitamos calcular posiciones numéricas y desplazamientos, en los gráficos de líneas comparativos el proceso es más directo: cada llamada a plt.plot() añade una nueva línea al mismo gráfico. Todas comparten el eje X automáticamente.
Ejemplo: comparación de ventas anuales
import matplotlib.pyplot as plt
meses = ['Ene', 'Feb', 'Mar', 'Abr', 'May']
ventas_2023 = [10, 12, 15, 14, 18]
ventas_2024 = [11, 14, 16, 18, 20]
plt.plot(meses, ventas_2023, label='2023')
plt.plot(meses, ventas_2024, label='2024')
plt.title("Comparación de ventas mensuales")
plt.xlabel("Mes")
plt.ylabel("Ventas")
plt.legend()
plt.show()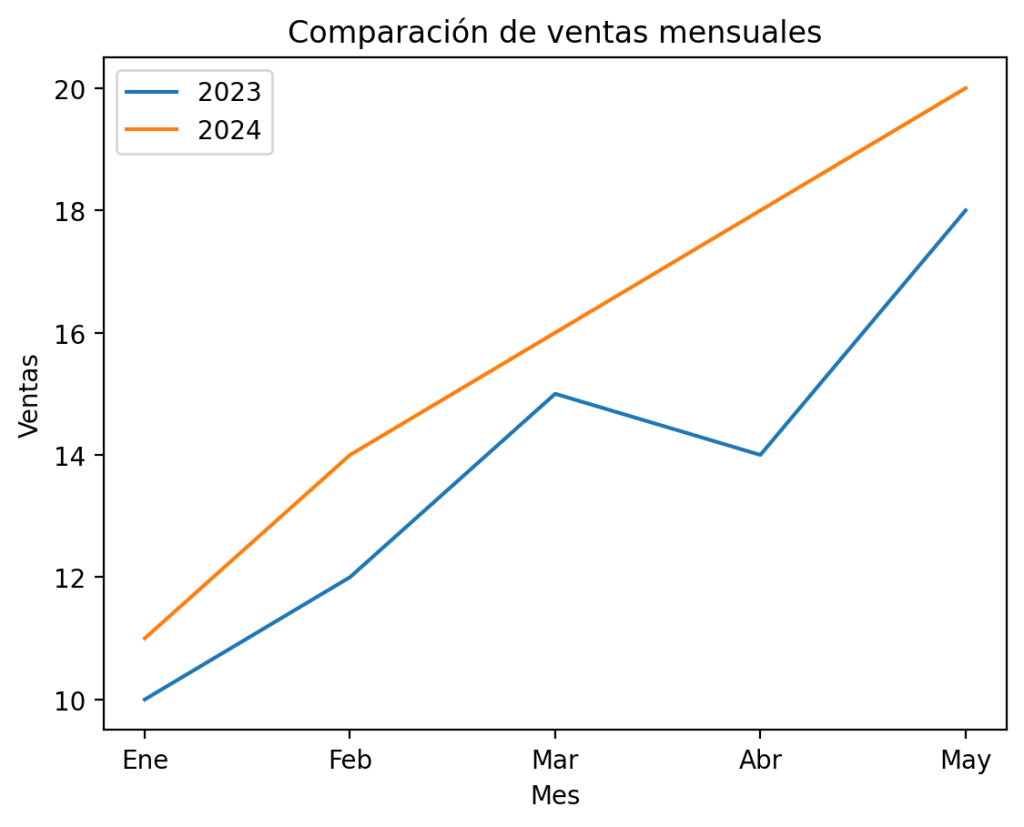
Vamos a detenernos en los detalles de este código:
- Dos llamadas a
plt.plot(): Cada llamada dibuja una línea independiente. Matplotlib asigna automáticamente un color diferente a cada una, siguiendo el ciclo de colores del estilo activo. Si quieres control total sobre los colores, es mejor especificarlos explícitamente (lo veremos en la siguiente sección). - El parámetro
label: Este parámetro no hace nada visible por sí solo. Su único propósito es definir el texto que aparecerá en la leyenda cuando llamemos aplt.legend(). Si te olvidas de añadirlabela alguna serie, esa línea no aparecerá en la leyenda. plt.legend(): Sin esta llamada, las etiquetas que definiste conlabelno se mostrarán. Es un error muy frecuente. Puedes controlar la posición de la leyenda con el parámetroloc:plt.legend(loc='upper left'),loc='lower right', o simplementeloc='best'para que Matplotlib elija automáticamente el lugar menos intrusivo.
Personalización visual: cómo diferenciar las series con claridad
Cuando varias líneas comparten el mismo espacio, la diferenciación visual es fundamental. Matplotlib ofrece tres herramientas principales: colores, estilos de línea y marcadores. Lo ideal es combinar los tres, no depender solo de los colores, especialmente si el gráfico puede ser impreso en blanco y negro o visto por personas con daltonismo.
Colores
plt.plot(meses, ventas_2023, color='steelblue', label='2023') plt.plot(meses, ventas_2024, color='darkorange', label='2024')
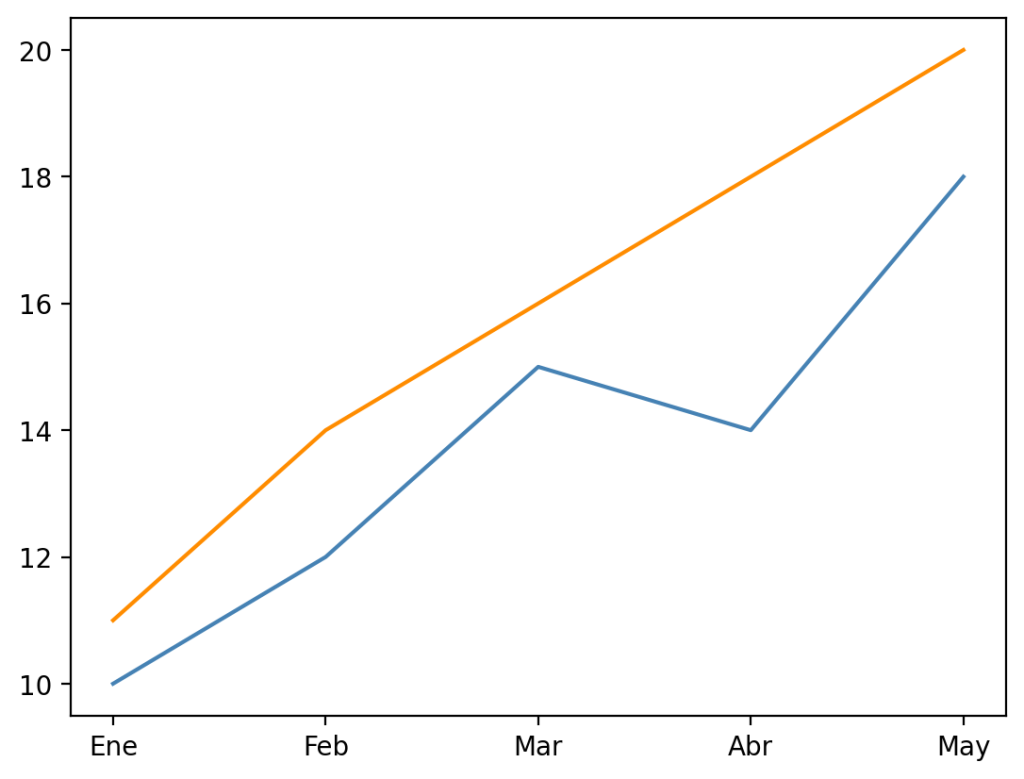
Puedes usar nombres de color de CSS ('red', 'navy'), códigos hexadecimales ('#2196F3') o colores de las paletas de Matplotlib ('C0', 'C1', 'C2'…). Para gráficos accesibles, la paleta tab10 o Set2 son buenas opciones.
Estilos de línea
plt.plot(meses, ventas_2023, linestyle='--', label='2023') plt.plot(meses, ventas_2024, linestyle='-', label='2024')
Los estilos más usados son:
| Código | Estilo |
|---|---|
'-' | Línea continua (por defecto) |
'--' | Línea discontinua |
':' | Línea punteada |
'-.' | Línea punto y raya |
Marcadores
plt.plot(meses, ventas_2023, marker='o', label='2023') plt.plot(meses, ventas_2024, marker='s', label='2024')
Los marcadores cumplen dos funciones: señalan exactamente dónde está cada dato (útil si los puntos están muy espaciados) y añaden otra capa de diferenciación visual. Los más comunes son:
| Código | Forma |
|---|---|
'o' | Círculo |
's' | Cuadrado |
'^' | Triángulo |
'D' | Diamante |
'x' | Cruz |
Combinando los tres elementos
La forma más efectiva es combinarlos en una sola línea usando el parámetro de formato abreviado o los parámetros explícitos:
plt.plot(meses, ventas_2023, color='steelblue', linestyle='--', marker='o', label='2023') plt.plot(meses, ventas_2024, color='darkorange', linestyle='-', marker='s', label='2024')
Este gráfico será distinguible incluso en escala de grises o para un lector con daltonismo.
Escalando a tres o más series
Añadir más series es tan simple como añadir más llamadas a plt.plot():
ventas_2022 = [8, 10, 12, 13, 15]
ventas_2023 = [10, 12, 15, 14, 18]
ventas_2024 = [11, 14, 16, 18, 20]
plt.plot(meses, ventas_2022, marker='o', linestyle=':', label='2022')
plt.plot(meses, ventas_2023, marker='s', linestyle='--', label='2023')
plt.plot(meses, ventas_2024, marker='^', linestyle='-', label='2024')
plt.legend()
plt.title("Evolución de ventas 2022–2024")
plt.xlabel("Mes")
plt.ylabel("Ventas")
plt.show()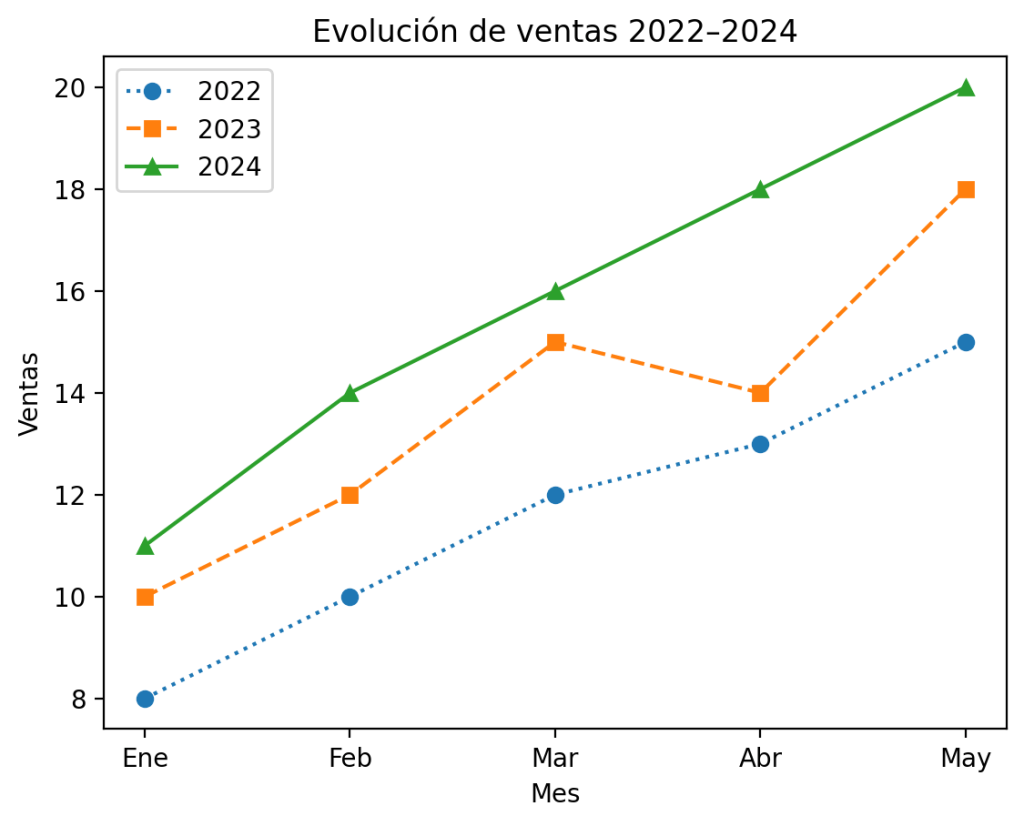
Aunque es importante recodar que existe un límite práctico: a partir de 5–6 series, el gráfico empieza a saturarse y resulta difícil seguir cada línea. Si tienes muchas categorías, considera estas alternativas:
- Dividir en subgráficos (small multiples) con
plt.subplots(). - Destacar solo las series más relevantes y agrupar el resto en una línea gris de “otros”.
- Usar un heatmap si lo que importa es el patrón general, no los valores exactos.
Datos numéricos continuos
Los gráficos de líneas alcanzan todo su potencial cuando el eje X es un valor numérico continuo, como el tiempo en segundos, una frecuencia o el valor de un parámetro. En estos casos, la línea no solo conecta puntos sino que traza una curva continua.
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 10, 200) # 200 puntos entre 0 y 10
y_sin = np.sin(x)
y_cos = np.cos(x)
plt.plot(x, y_sin, label='sin(x)', color='steelblue')
plt.plot(x, y_cos, label='cos(x)', color='darkorange', linestyle='--')
plt.legend()
plt.title("Comparación de funciones trigonométricas")
plt.xlabel("x")
plt.ylabel("f(x)")
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()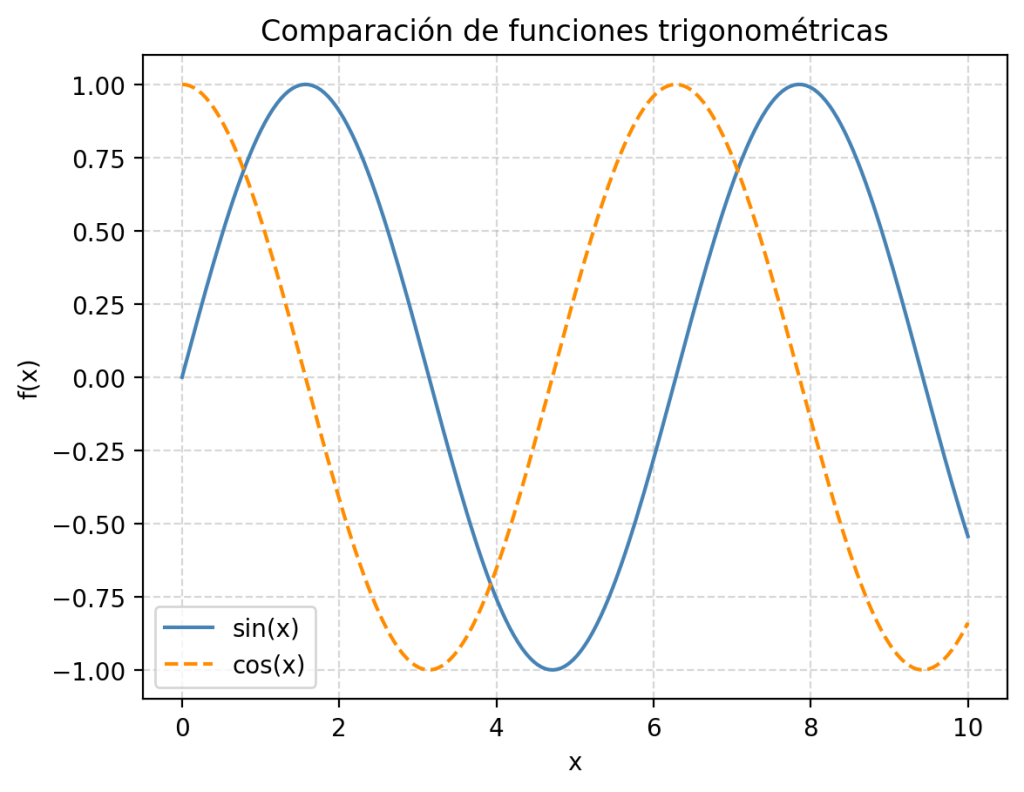
np.linspace(0, 10, 200) genera 200 puntos igualmente espaciados entre 0 y 10. Cuantos más puntos uses, más suave quedará la curva. Para datos de producción reales (como métricas de monitorización), el número de puntos viene dado por tus datos; para representar funciones matemáticas, puedes elegir la densidad que quieras.
Suavizado de series con media móvil
En datos reales, las series suelen tener ruido: fluctuaciones puntuales que no reflejan la tendencia subyacente. Una técnica sencilla y muy útil para reducir ese ruido es la media móvil: en lugar de mostrar el valor de cada punto, muestras el promedio de ese punto y sus vecinos.
import numpy as np
import matplotlib.pyplot as plt
# Simulamos ventas con algo de ruido
ventas = np.array([10, 13, 11, 15, 14, 18, 17, 20, 19, 23])
# Calculamos la media móvil con ventana de 3 periodos
window = 3
media_movil = np.convolve(ventas, np.ones(window) / window, mode='valid')
plt.plot(ventas, marker='o', linestyle=':', color='lightsteelblue', label='Ventas reales')
plt.plot(range(window - 1, len(ventas)), media_movil,
color='steelblue', linewidth=2, label=f'Media móvil ({window} periodos)')
plt.legend()
plt.title("Ventas reales vs tendencia suavizada")
plt.xlabel("Periodo")
plt.ylabel("Ventas")
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()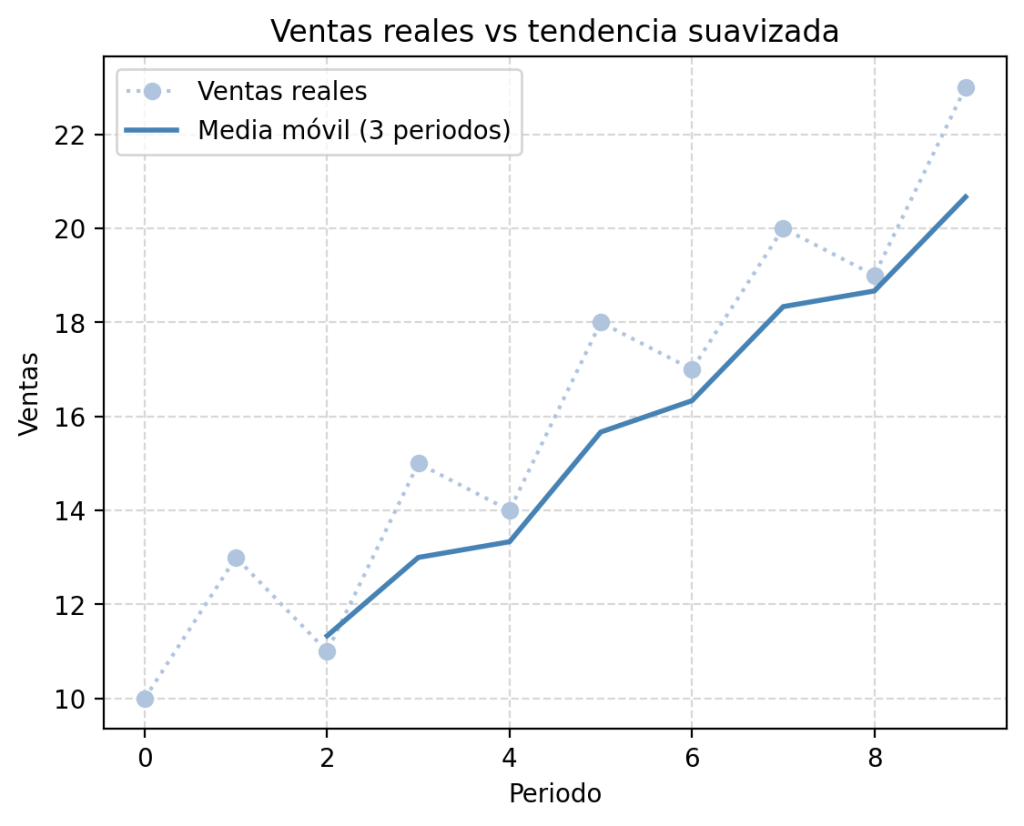
¿Cómo funciona np.convolve?
La función np.convolve aplica una convolución entre la serie original y un filtro. Al usar np.ones(window) / window, el filtro calcula la media simple de window valores consecutivos. El parámetro mode='valid' hace que el resultado solo incluya los puntos donde el filtro cabe completamente, por eso el array resultante es más corto que el original y hay que ajustar el eje X con range(window - 1, len(ventas)).
Mostrar la serie original junto a la suavizada en el mismo gráfico es una práctica habitual en análisis de series temporales: la línea punteada clara representa la realidad con su ruido, y la línea sólida más oscura muestra la tendencia.
Anotaciones en puntos clave
Un gráfico de líneas puede ser mucho más comunicativo si señalamos los momentos importantes directamente sobre la visualización. Esto es especialmente valioso en presentaciones o informes donde el lector no tiene el contexto de los datos.
import matplotlib.pyplot as plt
meses = ['Ene', 'Feb', 'Mar', 'Abr', 'May', 'Jun']
visitas = [100, 120, 115, 140, 180, 160]
plt.plot(meses, visitas, marker='o', color='steelblue', label='Visitas')
# Anotación en el punto máximo
plt.annotate(
'Campaña de primavera',
xy=('May', 180), # Coordenadas del punto a señalar
xytext=('Mar', 175), # Posición del texto
arrowprops=dict(facecolor='gray', arrowstyle='->', lw=1.5),
fontsize=9,
color='darkslategray'
)
plt.title("Tráfico web mensual")
plt.xlabel("Mes")
plt.ylabel("Visitas")
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()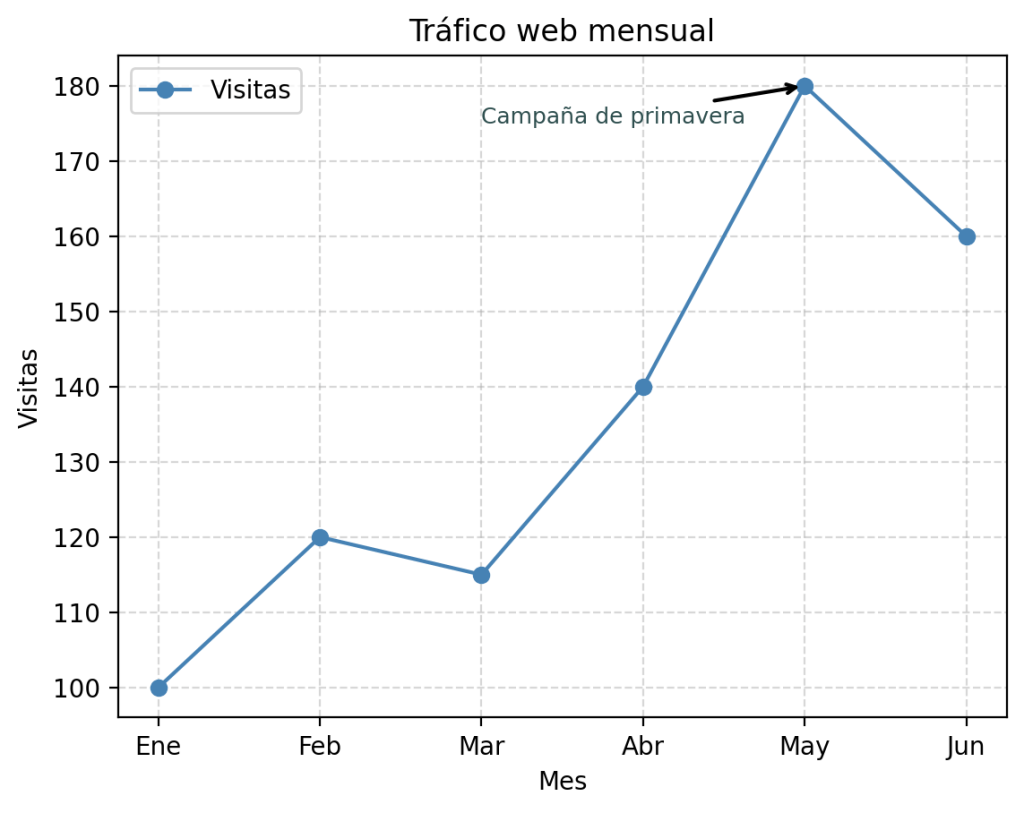
plt.annotate() acepta dos coordenadas: xy es el punto que quieres señalar (donde llegará la punta de la flecha) y xytext es donde aparecerá el texto. El diccionario arrowprops controla el aspecto de la flecha: arrowstyle='->' da una flecha limpia con punta, y lw controla el grosor de la línea.
Una buena práctica es anotar solo los puntos verdaderamente relevantes: un máximo histórico, una caída inesperada, el inicio de una nueva estrategia. Anotar demasiados puntos satura el gráfico y pierde el efecto.
Mejoras estéticas para un resultado profesional
Los los gráficos por defecto que se obtiene con Matplotlib suelen ser bastante buenos, pero siempre se puede mejorar para obtener un resultado más profesional.
Estilo base
plt.style.use('seaborn-v0_8')Este estilo aplica un fondo limpio, colores suaves y elimina el borde exterior del gráfico. Para publicaciones científicas, 'seaborn-v0_8-whitegrid' añade una cuadrícula blanca sobre fondo gris claro.
Cuadrícula
plt.grid(True, linestyle='--', alpha=0.5)
En los gráficos de líneas la cuadrícula es especialmente útil para estimar valores en puntos intermedios. El parámetro alpha=0.5 la hace semitransparente para que no compita visualmente con las líneas de datos.
Grosor de línea
plt.plot(meses, ventas, linewidth=2)
El valor por defecto es 1.5. Para gráficos en presentaciones o con mucho espacio, linewidth=2 o 2.5 mejora la visibilidad. Para gráficos con muchas series, líneas más delgadas reducen la saturación visual.
Rotación de etiquetas
plt.xticks(rotation=45, ha='right')
Si las etiquetas del eje X son fechas o nombres largos, rotarlas 45 grados evita que se solapen. El parámetro ha='right' alinea el texto a la derecha para que quede centrado bajo su punto.
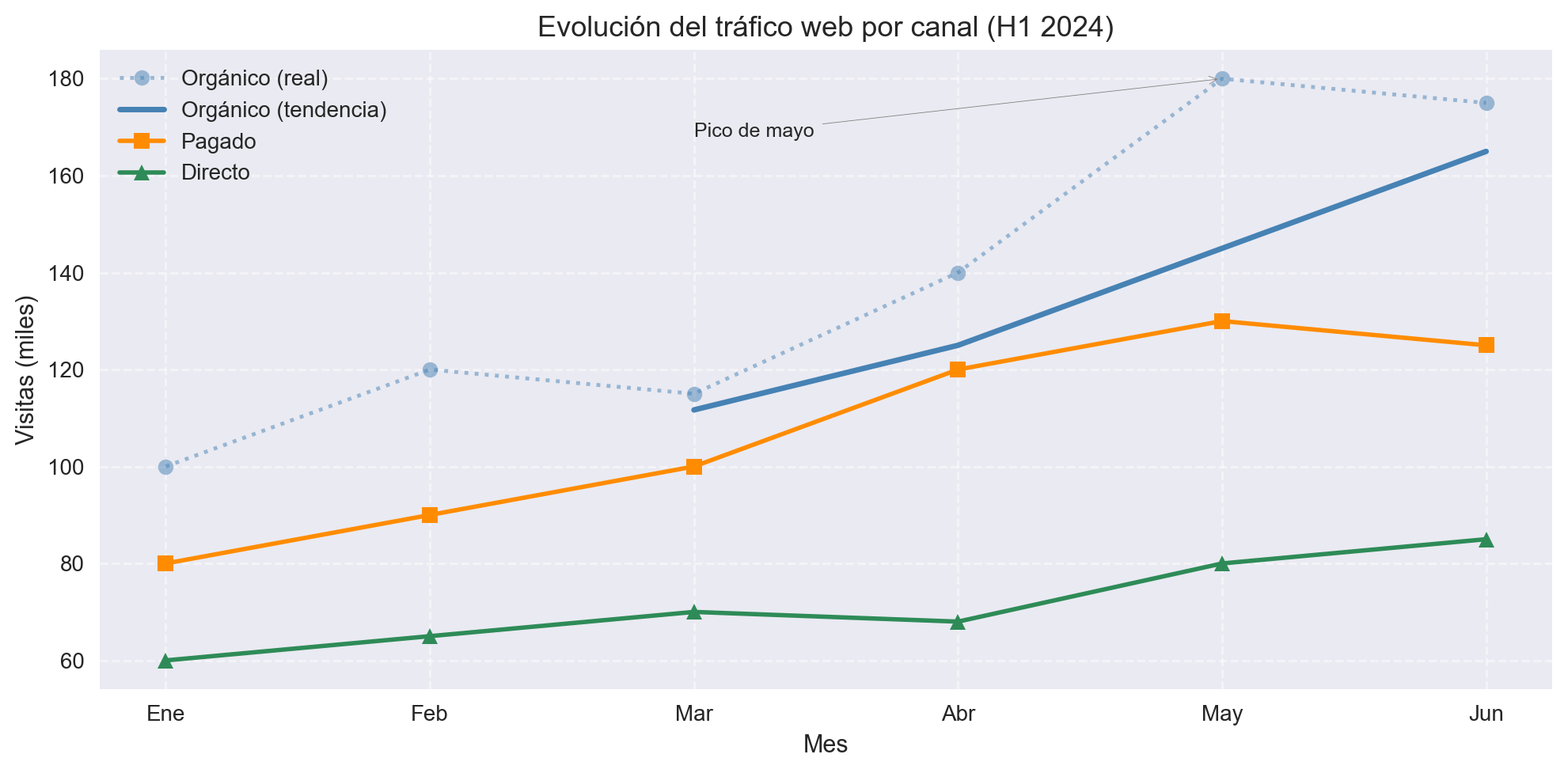
Caso práctico completo
Reunamos todo en un ejemplo realista: comparar el tráfico web por canal durante seis meses, con la serie orgánica suavizada para destacar la tendencia.
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('seaborn-v0_8')
meses = ['Ene', 'Feb', 'Mar', 'Abr', 'May', 'Jun']
organico = np.array([100, 120, 115, 140, 180, 175])
pagado = np.array([80, 90, 100, 120, 130, 125])
directo = np.array([60, 65, 70, 68, 80, 85])
# Media móvil del canal orgánico
window = 3
tendencia_organica = np.convolve(organico, np.ones(window) / window, mode='valid')
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(meses, organico, marker='o', linestyle=':', color='steelblue',
alpha=0.5, label='Orgánico (real)')
ax.plot(meses[window - 1:], tendencia_organica, color='steelblue',
linewidth=2.5, label='Orgánico (tendencia)')
ax.plot(meses, pagado, marker='s', color='darkorange', linewidth=2, label='Pagado')
ax.plot(meses, directo, marker='^', color='seagreen', linewidth=2, label='Directo')
# Anotación en el pico de mayo
ax.annotate('Pico de mayo', xy=('May', 180), xytext=('Mar', 168),
arrowprops=dict(arrowstyle='->', color='gray'), fontsize=9)
ax.set_title("Evolución del tráfico web por canal (H1 2024)", fontsize=13)
ax.set_xlabel("Mes")
ax.set_ylabel("Visitas (miles)")
ax.legend(loc='upper left')
ax.grid(True, linestyle='--', alpha=0.5)
plt.tight_layout()
plt.show()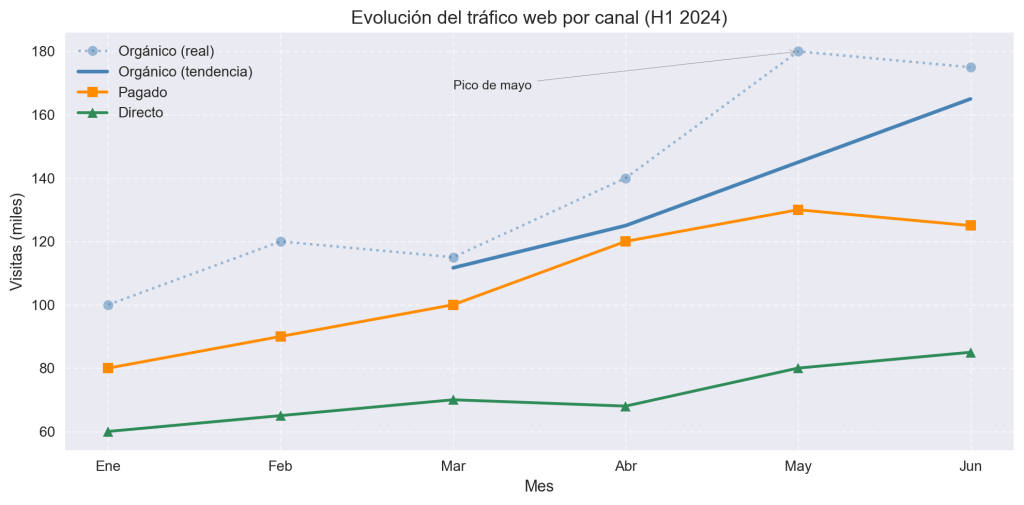
Este ejemplo combina series con distinto tratamiento (original + suavizada para el canal principal), tres tipos de marcadores, una anotación y el uso de fig, ax para un control más explícito del gráfico. Es el tipo de visualización que aparece habitualmente en dashboards de marketing, informes de producto o análisis de rendimiento web.
Errores comunes y cómo evitarlos
A la hora de crear gráficos hay que evitar ciertos problemas que pueden tierra todo el trabajo:
- No añadir leyenda: Si tienes más de una serie y no llamas a
plt.legend(), el gráfico es literalmente ininterpretable para quien no conoce los datos. Inclúyela siempre. - Confiar solo en el color para diferenciar series: En un informe impreso, en una pantalla de baja calidad o para un lector con daltonismo, dos líneas del mismo estilo solo diferenciadas por color pueden ser indistinguibles. Combina siempre color con estilo de línea o marcador.
- Demasiadas líneas en el mismo gráfico: Con 6 o más series, el gráfico se convierte en un espagueti de líneas y resulta imposible seguir cada una. Limita a 4–5 series como máximo, o divide el análisis.
- Usar gráfico de líneas con datos categóricos sin orden: Si tu eje X es algo como
['Madrid', 'Barcelona', 'Valencia', 'Sevilla'], la línea que los conecta no tiene significado: no hay una transición natural de una ciudad a la siguiente. En ese caso, usa barras. - No etiquetar los ejes: Un gráfico sin etiquetas en los ejes obliga al lector a buscar el contexto en el texto que lo rodea. Incluye siempre
xlabel,ylabely un título descriptivo.
Resumen: líneas vs barras
| Situación | Tipo recomendado |
|---|---|
| Eje X es tiempo o variable continua | Líneas |
| Quieres ver evolución o tendencia | Líneas |
| Eje X son categorías sin orden | Barras |
| Quieres comparar magnitudes puntuales | Barras |
| Tienes muchas categorías y pocos grupos | Barras |
| Tienes pocos puntos pero muchos grupos | Líneas |
La regla de oro: si tiene sentido trazar una línea entre dos puntos consecutivos (porque hay una transición real entre ellos), usa líneas. Si no la tiene, usa barras.
Conclusiones
Los gráficos de líneas comparativos son la herramienta más adecuada cuando quieres contar la historia de cómo algo evoluciona. Con Matplotlib puedes construir desde una comparación simple de dos series hasta visualizaciones más elaboradas con suavizado, anotaciones y múltiples capas de información.
Como en cualquier visualización, la clave no está en la técnica sino en la pregunta: ¿qué quieres que el lector vea? ¿Una tendencia? ¿Un punto de inflexión? ¿Una diferencia que crece con el tiempo? La respuesta a esa pregunta debería guiar cada decisión de diseño, desde el tipo de marcador hasta dónde colocar la leyenda.
Deja una respuesta