
La librería Pandas-Profiling permite automatizar el análisis de datos en Python. Generando automáticamente informes de los conjuntos de datos contenidos en objetos DataFrame.
Introducción
Una de las primeras tareas a realizar cuando recibimos un nuevo conjunto de datos es un análisis exploratorio del mismo. En el que se incluyen tareas como determinar el rango de cada una de las características, identificar los tipos de datos, así como calcular el porcentaje de valores nulos en cada una de las características. Tareas con las que se busca conocer mejor el conjunto de datos e identificar cualquier tipo de problema que pueda existir. Al trabajar el Python el análisis exploratorio de datos se suele realizar con la librería pandas, ya que cuenta con diferentes funciones. Sin embargo, las funcionalidades de estas son limitadas. Además, como las tareas a realizar son casi siempre las mismas, el proceso es monótono. Por ello, disponer de herramientas que permitan automatizar el análisis exploratorio de datos son siempre interesante.
Instalación de Pandas-Profiling
El paquete Pandas-Profiling no está incluido por defecto en Anaconda, por lo que es necesario instalarlo antes de usarlo. La instalación se puede realizar tanto desde pip, para lo que se puede utilizar la siguiente línea de comandos:
pip install pandas-profiling
Alternativamente también se puede instalar utilizando conda, para lo que se tiene que escribir la siguiente línea.

conda install -c anaconda pandas-profiling
Análisis exploratorio de datos básicos con pandas
Antes de crear un informe es necesario importar un conjunto de datos. A modo de ejemplo se pueden utilizar algunos de los incluidos en la librería seaborn, como puede ser el conjunto de propinas. Para lo que se puede emplear el siguiente código.
from seaborn import load_dataset
df = load_dataset("tips")
df.head()total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4
Con lo que se puede observar que el conjunto de datos contiene siete características: total_bill, tip, sex, smoker, day, time y size. Uno de los primeros análisis exploratorios que se puede realizar es mediante la propiedad df.describe().
total_bill tip size count 244.000000 244.000000 244.000000 mean 19.785943 2.998279 2.569672 std 8.902412 1.383638 0.951100 min 3.070000 1.000000 1.000000 25% 13.347500 2.000000 2.000000 50% 17.795000 2.900000 2.000000 75% 24.127500 3.562500 3.000000 max 50.810000 10.000000 6.000000
Un análisis que, a pesar de su utilidad, contiene una información bastante limitada.
Automatizar el análisis exploratorio de datos con Pandas-Profiling
Pandas-Profiling dispone de la clase ProfileReport() con la que se pueden crear automáticamente análisis exploratorios de datos en formato HTML. Este análisis se puede ver en línea, dentro de un notebook o exportar a un archivo en formato HTML. El código que se muestra a continuación guarda los resultados en el archivo output.html.
import pandas_profiling profile = pandas_profiling.ProfileReport(df) profile.to_file(outputfile="output.html")
Informe que se puede ver en la siguiente captura de pantalla.

En la primera sección del informe se muestra información general del conjunto de datos. Posteriormente se muestra detalles de cada una de las características incluyendo el número de valores únicos, el número de nulos y estadísticos como valores máximos, mínimos y medias. Además de también se pueden encontrar secciones con datos de correlación y muestras de los datos.
Detalle de los informes
En cada una de las variables se puede encontrar la opción Toggle details para consultar un análisis más detallado. Si la variable es categórica mostrará el detalle de cada uno de los detalles. A modo de ejemplo, a continuación, se muestra el detalle de la variable day.
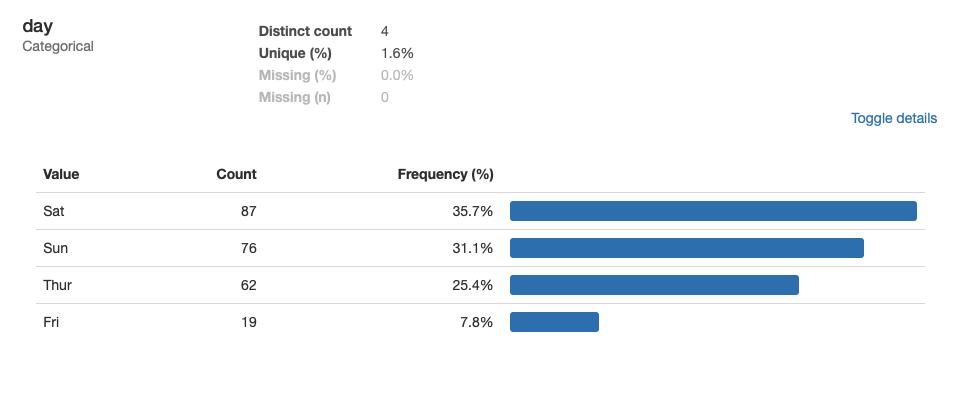
Mientras que si la variable es numérica se podrá acceder a estadísticas, un histograma, el listado de valores más comunes y los valores extremos. A continuación, se muestra el detalle de la variable size.

Conclusiones
En esta entrada se ha mostrado una herramienta con la que se puede automatizar el análisis de datos en Python. Pandas-Profiling permite conseguir casi automáticamente informes que de otra forma se tardaría horas en realizar. Evitando así dedicar tiempo a tareas monótonas y repetitivas.
Imágenes: Pixabay (Pexels)
Deja una respuesta