
Una característica bastante desconocida de Pandas es la posibilidad de cambiar el formato de los DataFrame. Incluso de forma condicional. Lo que se puede hacer utilizando los diferentes métodos que se encuentran dentro de la propiedad style de los DataFrame. Siendo esta una opción que resulta interesante a la hora de la creación de informes ya hace innecesario salir de Python para aplicar formatos condicionales a las tablas. A continuación vamos a ver como aplicar los formatos condicionales en Pandas.
Dando formato a un DataFrame con estilo
Para poder dar formato a un documento primero se tiene que crear un DataFrame de ejemplo. Lo que se puede hacer con el siguiente código en el que hemos incluido valores NaN e infinitos.
import pandas as pd
import numpy as np
df = pd.DataFrame({'id': np.linspace(1, 6, 6)})
df = pd.concat([df, pd.DataFrame(np.random.randn(6, 4), columns=list('ABCD'))],axis=1)
df.iloc[0, 2] = np.nan
df.iloc[2, 3] = np.PINF
df.iloc[4, 4] = np.NINF
df.iloc[5, 2] = np.nan
df
En este caso el DataFrame se muestra en un notebook de la siguiente forma
Cambiar el formato decimal
Por defecto los valores en los DataFrame se muestran con seis cifras decimales. Si esto es no aporta información o es insuficiente, es posible indicar a Pandas que el DataFrame se muestre con un formato diferente. Para lo que se debe usar el método format() de la propiedad style del DataFrame. Así para indicar que solo se muestran dos decimales solo se tiene que escribir la siguiente línea de código

df.style.format("{:.2f}")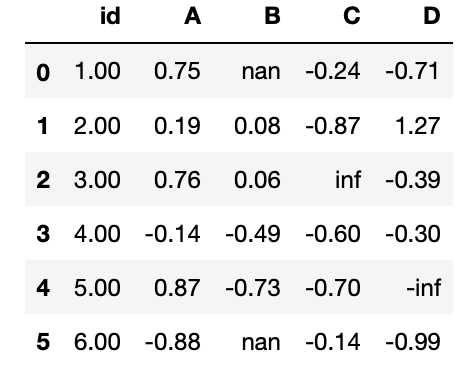
En donde se ha indicado que se use un formato de tipo real con dos decimales.
Sacar porcentajes en los DataFrame
Si los datos del DataFrame se tiene que expresar como porcentajes no es necesario multiplicar los valores por cien, ya que se le puede indicar en lugar de reales se puede indicar que el formato sea de tipo decimal. Así para obtener decimales en todas las columnas de DataFrame se puede usar
df.style.format("{:.1%}")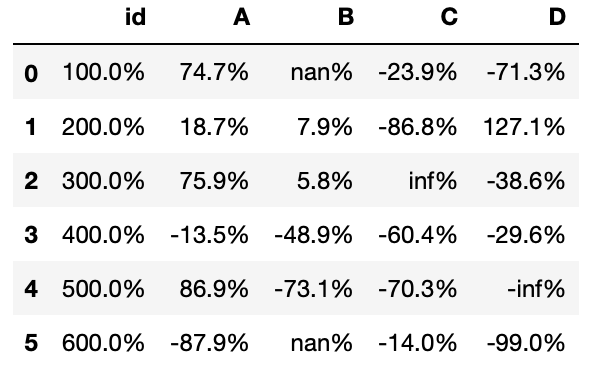
Aplicar el formato solo a algunas columnas
En la mayoría de los casos no es necesario que todas las columnas del DataFrame tengan el mismo formato. Por ejemplo, en los ID no es necesario decimales y puede existir columnas que sean porcentajes y otras no. En estos casos se le puede indicar mediante un diccionario cuales son las columnas sobre las que se aplica el formato. Por ejemplo, para hacer que en la columna Id aparezcan números enteros, en la columna A reales con dos decimales y en la columna C porcentajes se puede usar escribir la siguiente línea de código
df.style.format({'id':'{:.0f}', 'A':'{:.2f}', 'C': '{:.1%}'}, na_rep='-')
Además, en este caso se ha utilizado la propiedad na_rep con la que es posible reemplazar los valores NaN por un símbolo. En este caso una línea.
Resaltar valores
También puede ser interesante resaltar algunos valores como pueden ser los máximos o los mínimos. Para lo que se puede utilizar la propiedad highlight_max y highlight_min respectivamente. Al utilizarse por defecto se resaltan en amarillo los valores máximos en cada una de las columnas.
df.style.highlight_max()
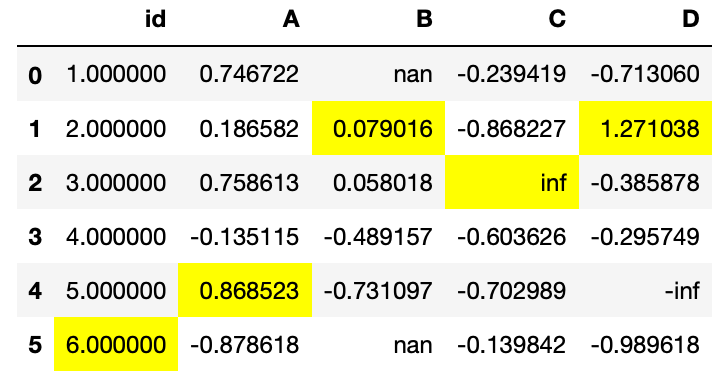
Aunque también se puede indicar mediante la propiedad axis que se busquen los máximos o mínimos en cada una de las filas.
df.style.highlight_max(axis=1)
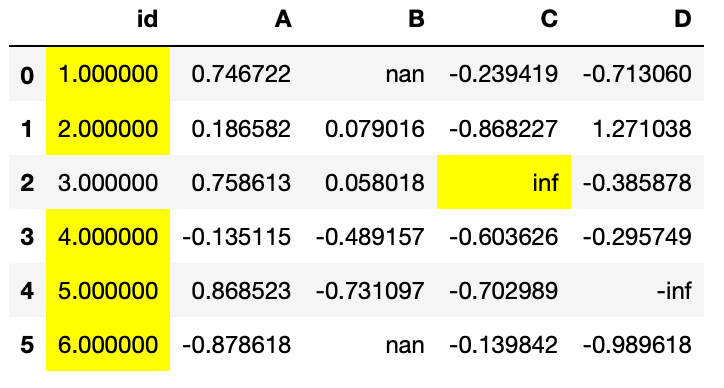
Barras en las celdas
Otra forma que se suele emplear bastante para ver los valores relativos en las celdas son las barras. Para esto en los DataFrame de Pandas se puede usar el método bar. Al aplicarlo en cada una de las celdas de las columnas se mostrarán barras relativas entre el valor mínimo y máximo de cada columna.
df.style.bar(subset=['id', 'A'], color='blue')

Estilos personalizados
Además de los métodos que incorpora Pandas también se pueden crear estilos personalizados mediante apply y applymap. Al usar apply se aplica una función a cada una de las columnas la cual puede modificar el estilo de la celda. Por otro lado, si se quiere aplicar una función a cada uno de los elementos se debería usar la propiedad applymap. Por ejemplo, para resaltar los valores mínimos, en lugar de highlight_min, se puede usar el comando.
df.style.apply(lambda x : ['background-color: green' if v else '' for v in x == x.min()])
Por otro lado, para marcar en rojo los valores negativos se puede usar:
df.style.applymap(lambda x : 'color: red' if x < 0 else 'color: black')
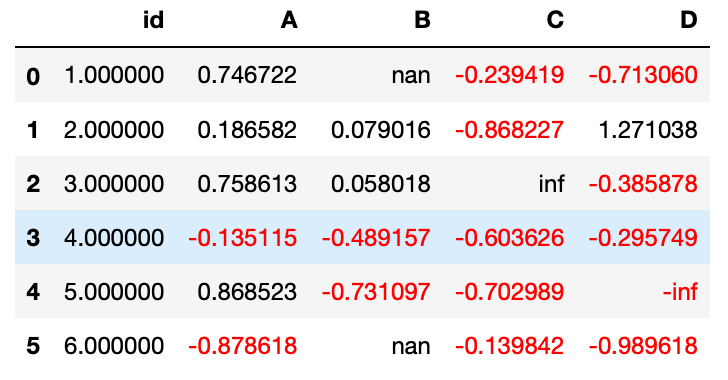
Combinación de formatos
Una de las grandes ventajas de estos métodos es que se pueden llamar más de uno en un DataFrame, con lo que se puede conseguir formatos condicionales en Pandas tan complejos como sea necesario. Por ejemplo, se puede combinar todo lo que se ha mostrado en la entrada.
df.style.\
apply(lambda x : ['background-color: green' if v else '' for v in x == x.max()]).\
applymap(lambda x : 'color: red' if x < 0 else 'color: black').\
bar(subset=['id'], color='blue').\
format({'id':'{:.0f}'})
Conclusiones
En esta entrada se ha realizado una introducción a los formatos condicionales en Pandas. Una opción que nos ofrece esta librería para poder mostrar los datos de una forma completamente personalizada.
buenas
como seria el formato de miles y millones?
Simplemente se tiene que indicar que se desea usar el separador de miles con una coma, esto es, solamente se tiene que hacer
df.style.format('{:,}')Lo que se pude combinar la limitación de decimales, por ejemplo, para fijar dos se pude usar:
df.style.format('{:,.2f}')