
La mayoría de los algoritmos de aprendizaje automático solamente pueden trabajar con datos numéricos. Pero, en muchas ocasiones, lo que se tienen son datos de tipo categórico. Debido a que los algoritmos no pueden realizar las operaciones matemáticas sobre estos, es necesario transformarlos antes de poder emplearlos en el entrenamiento de cualquier modelo de aprendizaje … [Leer más...] acerca de Creación de variables dummies con Pandas (variables binarias para aprendizaje automático)
Python
Python es un lenguaje de programación interpretado con una filosofía basada en la legibilidad del código. Un lenguaje que gracias posee un gran ecosistema de librerías para la ciencia de datos. Por lo que es uno de los más populares en la actualidad entre los científicos de datos. Además, es uno de los lenguajes más deseados y adorados por los programadores según las encuestas de Stack Overflow.
Python es un lenguaje de programación interpretado de propósito general que obliga al uso de una sintaxis clara, gracias a la cual el código es altamente legible. Siendo un lenguaje potente y fácil de aprender. Además, permite utilizar múltiples paradigmas de programación. Lo que permite usar desde programación orientada a objetos, pasando por programación imperativa o funcional.
Los paquetes de Python más utilizados por los científicos son:
- NumPy: permite el tratamiento de datos basados en matrices,
- Pandas: ideal para la manipulación de datos heterogéneos mediante objetos DataFrame,
- SciPy: implementa tareas habituales en computación científica,
- Matplotlib: facilita la visualización de datos y scikit-learn creación de modelos de aprendizaje automático.
Las publicaciones de esta sección versan sobre estas librerías y las bases del lenguaje.
Reemplazo condicional de valores en Pandas
Los objetos DataFrame de Pandas son unas estructuras de datos fantásticas para el análisis y manipulación de los datos. Facilitando muchas tareas en el día a día. Por ejemplo, cuando se necesita reemplazar ciertos registros en función de los valores de estos u otros, esto es, cuando se desea realizar un reemplazo condicional de valores.Conjunto de datos de ejemploEn … [Leer más...] acerca de Reemplazo condicional de valores en Pandas
Calcular diferencia entre elementos de un DataFrame con diff
En los objetos DataFrame de Pandas existe un método con el que se puede obtener la diferencia entre un elemento y el anterior, o cualquier otra posición. Este método es diff(). Su uso permite obtener la diferencia entre los elementos de un DataFrame, lo que se puede usar para ver de una forma rápida cómo crece o decrece una magnitud.El método diff() en PandasEl … [Leer más...] acerca de Calcular diferencia entre elementos de un DataFrame con diff
Acotar los valores en un DataFrame de Pandas
Existen diferentes motivos por los que puede ser necesario limitar o acotar los valores en un DataFrame. Por ejemplo, eliminar valores atípicos o garantizar la consistencia de los datos. Esto es algo que se puede conseguir mediante asignaciones condicionales de valores, aunque también existe el método clip() que lo permite hacer de una manera más legible y con la que es más … [Leer más...] acerca de Acotar los valores en un DataFrame de Pandas
Análisis de sentimientos en español con spaCy en Python

La semana pasada se vio cómo se puede realizar análisis se sentimientos en inglés con NLTK. A pesar de que NLTK es una librería muy potente, no cuenta con un lematizador para español, por lo que no es adecuado para trabajar en nuestro idioma. Una alternativa que sí permite realizar análisis de sentimientos en español en Python es spaCy, la cual también es bastante fácil de … [Leer más...] acerca de Análisis de sentimientos en español con spaCy en Python
Análisis de sentimientos con NLTK en Python

La librería de referencia el Python para realizar procesado del lenguaje natural (PLN) es NLTK (Natural Language Toolkit). Lo que se debe a que prácticamente incluye todas las herramientas necesarias para trabajar con PLN, entre las que se incluyen tokenización, lematización, etiquetado gramatical, análisis sintáctico y análisis de sentimientos. Facilitando de esta manera el … [Leer más...] acerca de Análisis de sentimientos con NLTK en Python
Ordenar textos en Python con acentos en diferentes idiomas

Las listas que contienen cadenas de texto se pueden ordenar el Python mediante el uso de la función sorted(). Cuando se trabaja con cadenas de texto en inglés el resultado de la ordenación es correcto, pero no así en otros idiomas como el español donde existen acentos los cuales Python no ordena correctamente. Una solución a este problema se puede conseguir con el paquete … [Leer más...] acerca de Ordenar textos en Python con acentos en diferentes idiomas
Diferencias entre fit(), predict() y fit_predict() en Scikit-learn

Scikit-learn (muchas veces reverenciada como sklearn) es posiblemente la librería de Aprendizaje Automático más popular actualmente en Python. Lo que se debe a la cantidad de modelos que implementa y su sencillez. En la mayoría de los objetos de esta librería se encuentran implementados los métodos fit(), predict() y fit_predict() usados para entrenar y realizar predicciones … [Leer más...] acerca de Diferencias entre fit(), predict() y fit_predict() en Scikit-learn
Uso de comillas simples o dobles en Python

A diferencia de otros lenguajes de programación Python ofrece la posibilidad de escribir las cadenas de texto dentro de comillas simples o dobles. Aunque en la mayoría de los casos es posible usar indistintamente unas u otras, existen situaciones en las que no es así. Ante la duda de cual usar se podría consultar PEP8, pero en este caso el estándar no hace ninguna recomendación … [Leer más...] acerca de Uso de comillas simples o dobles en Python
Eliminar las filas con valores nulos en Pandas
Cuando se importa un conjunto de datos en un DataFrame de Pandas es posible que existan valores nulos. Cuya presencia puede afectar a las conclusiones de los análisis que se desean realizar. Para evitar esto una posible solución es eliminar las filas con valores nulos, tanto sea en una única columna, en cualquiera o en un subconjunto.Conjuntos de datos con valores nulos en … [Leer más...] acerca de Eliminar las filas con valores nulos en Pandas
Obtener los índices de los N valores máximos en NumPy

En NumPy existe la función np.max() para obtener el máximo de un vector o matriz y np.argmax() para obtener la posición del máximo. De forma análoga también existen las funciones np.min() y np.argmin() para el caso de querer obtener el mínimo o su posición. Pero, en el caso de que se desee obtener los índices de los N valores máximos en NumPy no existe una función directa y es … [Leer más...] acerca de Obtener los índices de los N valores máximos en NumPy
Gráficos de cascada: visualizar la evolución de los datos en Python
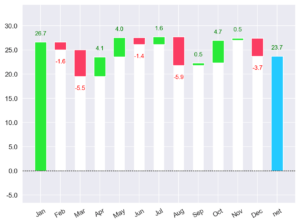
Los gráficos de cascada (Waterfall charts) son una herramienta para visualizar de una forma sencilla cómo se acumulan los valores positivos y negativos en una serie de datos. Pudiendo ofrecer en algunos casos más información que los gráficos de barras o líneas. Actualmente no existe en Matplotlib o Seaborn una forma sencilla de crear estos gráficos, pero existen otros paquetes … [Leer más...] acerca de Gráficos de cascada: visualizar la evolución de los datos en Python