
Python dispone de un gran ecosistema para el cálculo numérico, el análisis estadístico y el aprendizaje automático. Siendo el entorno favorito de muchos científicos de datos. Por otro lado, R es también un gran entorno para el análisis estadístico que dispone de una amplia colección de paquetes. A pesar de ellos, cada uno tiene sus ventajas e inconvenientes. Por este motivo … [Leer más...] acerca de Utilizar R desde Python con rpy2
Python
Python es un lenguaje de programación interpretado con una filosofía basada en la legibilidad del código. Un lenguaje que gracias posee un gran ecosistema de librerías para la ciencia de datos. Por lo que es uno de los más populares en la actualidad entre los científicos de datos. Además, es uno de los lenguajes más deseados y adorados por los programadores según las encuestas de Stack Overflow.
Python es un lenguaje de programación interpretado de propósito general que obliga al uso de una sintaxis clara, gracias a la cual el código es altamente legible. Siendo un lenguaje potente y fácil de aprender. Además, permite utilizar múltiples paradigmas de programación. Lo que permite usar desde programación orientada a objetos, pasando por programación imperativa o funcional.
Los paquetes de Python más utilizados por los científicos son:
- NumPy: permite el tratamiento de datos basados en matrices,
- Pandas: ideal para la manipulación de datos heterogéneos mediante objetos DataFrame,
- SciPy: implementa tareas habituales en computación científica,
- Matplotlib: facilita la visualización de datos y scikit-learn creación de modelos de aprendizaje automático.
Las publicaciones de esta sección versan sobre estas librerías y las bases del lenguaje.
Implementación del método descenso del gradiente en Python

Una de las fases clave en los proyectos de aprendizaje automático es el entrenamiento de los modelos. El futuro rendimiento de los modelos dependerá en gran medida del éxito en esta fase. En esta es necesario identificar los parámetros de un modelo o método de aprendizaje automático con los que se consigue el máximo rendimiento sobre el conjunto de datos de entrenamiento. … [Leer más...] acerca de Implementación del método descenso del gradiente en Python
Algunas librerías interesantes de Python para ciencia de datos

En una entrada anterior se recopilaron las cuatro librerías más importantes de Python para los científicos de datos. En esta entrada se van a ver otras seis librerías también interesantes de Python para ciencia de datos. Cada una de ellas permite trabajar en un tipo de problema concreto.imbalanced-learnEl entrenamiento de los algoritmos de clasificación funciona mejor … [Leer más...] acerca de Algunas librerías interesantes de Python para ciencia de datos
Selección de una submuestra en Python con pandas

La generación de muestras aleatorias a partir de conjunto de datos es una tarea bastante habitual. Al realizar el entrenamiento de un modelo supervisado es habitual dejar un conjunto de datos para una validación posterior. También en algunos estudios estadísticos pueden realizarse únicamente con un conjunto de los datos originales. Por este motivo los objetos DataFrame de … [Leer más...] acerca de Selección de una submuestra en Python con pandas
Utilizar el portapapeles en Python con pandas

El portapapeles es una forma rápida de mover datos entre las aplicaciones abiertas en una sesión. Por ejemplo, es posible copiar el código publicado e insertarlo en un editor de texto. Otra aplicación es copiar una parte de los datos de una hoja de cálculo e insertarlos en otra o en una sesión de Python. Para esto último se puede utilizar la función read_clipboard() disponible … [Leer más...] acerca de Utilizar el portapapeles en Python con pandas
Convertir un diccionario en DataFrame en Python

Los diccionarios son unas estructuras de datos muy flexibles que relacionan una clave con un valor. En Python la clave puede ser cualquier tipo de dato inmutable y el valor puede ser cualquier tipo de dato. La principal diferencia entre los diccionarios y las listas o tuplas es el cómo se acceden a los valores. Mientras que en las listas o tuplas se accede mediante índices en … [Leer más...] acerca de Convertir un diccionario en DataFrame en Python
Tablas dinámicas en Python con pandas

Es muy probable que la mayoría de los lectores tengan experiencia con las tablas dinámicas de Excel. Estas son un tipo especial de tablas en las que es posible resumir de forma dinámica el contenido de hojas calculo. A la hora de su definición es posible indicar los campos a utilizar como columna, como fila y los estadísticos que se mostraran en estas. Otro nombre por el que … [Leer más...] acerca de Tablas dinámicas en Python con pandas
Medir y reducir el consumo de memoria en Python

La disponible memoria en los sistemas informáticos es un recurso limitado. En la implementación de un algoritmo esto se ha de tener en cuenta. Reducir el consumo de la memoria es clave para permitir que el programa se ejecute en sistemas con menos recursos. Además de mejorar el rendimiento en sistemas con más recursos. Para reducir el consumo de memoria en Python es necesario … [Leer más...] acerca de Medir y reducir el consumo de memoria en Python
Cuatro librerías para ciencia de datos en Python

Hoy en día Python es uno de los lenguajes de referencia para los científicos de datos. En él se pueden implementar desde los análisis de datos más básicos hasta los modelos de aprendizaje automático más avanzados. Permitiendo llevar estos posteriormente a directamente a producción de una forma fácil. Esta popularidad es debida a múltiples factores. Entre ellos se puede destacar … [Leer más...] acerca de Cuatro librerías para ciencia de datos en Python
Visualización de árboles de decisión en Python con PyDotPlus

Los árboles de decisión son un de la familia de modelos de aprendizaje automático más utilizados. Se pueden utilizar tanto para resolver problemas de clasificación como de regresión. Una de sus principales ventajas es la facilidad con la que se puede interpretar los resultados en base a reglas. Permitiendo no solo obtener un resultado, sino que inspeccionar los motivos por los … [Leer más...] acerca de Visualización de árboles de decisión en Python con PyDotPlus
Sistemas de ecuaciones lineales con numpy
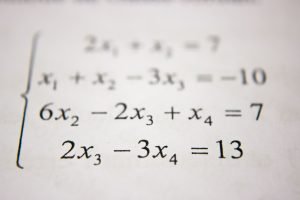
Un problema de cálculo que se puede resolver fácilmente con Python son los sistemas de ecuaciones lineales. Gracias a las matrices de numpy se puede conseguir el resultado poco más de un par de líneas. Por ejemplo, para resolver un sistema de ecuaciones lineales con numpy solamente se ha de utilizar el siguiente bloque de código:Al ejecutar el código se puede comprobar … [Leer más...] acerca de Sistemas de ecuaciones lineales con numpy
Utilización de pantallas retina en Jupyter Notebook

Las pantallas con una alta densidad de pixeles son cada vez más populares, volviéndose en muchos casos el estándar de la industria. Esto es porque la calidad en la imagen de las pantallas es considerable. Hoy en día se pueden encontrar una gran oferta de ordenadores o monitores con resolución HiDPI o Retina Display en el mundo Apple. Por defecto la calidad de las pantallas … [Leer más...] acerca de Utilización de pantallas retina en Jupyter Notebook