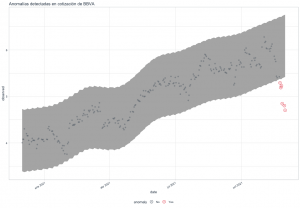
La detección de anomalías es un campo del aprendizaje automático con múltiples aplicaciones prácticas. Poder identificar automáticamente los datos que son atípicos para una variable permite lanzar alarmas para comprobar la existencia temprana de algún problema. Pudiendo actuar en consecuencia y minimizar las posibles consecuencias. Recientemente he descubierto un paquete de R, … [Leer más...] acerca de Detección de anomalías en series temporales
R
R nació como una implementación libre del S, un lenguaje de programación muy utilizado por la comunidad estadística. Actualmente es el lenguaje de programación más popular para el análisis estadístico. Gozando de una gran popularidad en campos como la minería de datos, la bioinformática y finanzas. Una gran parte de su popularidad es debido a que se puede extender fácilmente gracias a los más de 15.000 paquetes disponibles hoy en día en el CRAN. Por lo que casi siempre se puede encontrar un paquete que implementa el algoritmo necesario en cada momento
Diferencias entre Apache Arrow y Parquet

Apache Arrow y Parquet son dos formatos modernos para con los que es posible conseguir archivos más pequeños que CSV, además de unos menores tiempos de lectura y escritura. Veamos a continuación las diferencias que existen entre Apache Arrow y Parquet.Apache ArrowApache Arrow es una biblioteca, disponible para múltiples lenguajes de programación, que proporciona … [Leer más...] acerca de Diferencias entre Apache Arrow y Parquet
Lectura y escritura de archivos Apache Arrow o Feather en R

En entradas recientes hemos hablado de las ventajas que ofrecen los archivos Apache Arrow o Feather frente a los tradicionales CSV. No solo ocupan menos espacio en disco, sino que los procesos de lectura y escritura son varios órdenes de magnitud más rápidos. Siendo ambas son grandes ventajas cuando se trabaja con conjunto de datos de gran tamaño. La única desventaja podría ser … [Leer más...] acerca de Lectura y escritura de archivos Apache Arrow o Feather en R
Cómo combinar dataframes en R

Suele ser habitual que los conjuntos de datos con los que trabajamos no se encuentren en una única tabla. Por ejemplo, los datos que identifican al cliente y las operaciones que este ha realizado. Una forma puede ser unirlos en una base de datos mediante un comando SQL. Aunque también se pueden combinar dataframes en R directamente, usando para ello la función … [Leer más...] acerca de Cómo combinar dataframes en R
Cómo ordenar dataframe en base a múltiples columnas en R

Una tarea bastante habitual cuando se trabaja con conjuntos de datos es ordenar los registros en base los valores de una o varias columnas. Por ejemplo, buscar los clientes con mayor número de visitas y, a igual número de visitas, ordenarlos por gasto. Lo que se pude conseguir fácilmente en R. Únicamente hay que combinar el uso de order() con with() para poder ordenar dataframe … [Leer más...] acerca de Cómo ordenar dataframe en base a múltiples columnas en R
Obtener la media móvil en R

La media móvil es una herramienta que se utiliza habitualmente en análisis de series temporales para eliminar las fluctuaciones a corto plazo. Lo que facilita la observación de las tendencias a largo plazo de la serie. Existen diferentes métodos para calcular la media móvil, siendo el más empleado es media móvil simple (Moving Average), en la que se utilizan la media aritmética … [Leer más...] acerca de Obtener la media móvil en R
Diferencias entre library() y require() en R

En R existen dos funciones con las que se puede cargar los paquetes que tenemos instalados en nuestras sesiones: library() y require(). Aunque ambas funciones parece que hacen lo mismo: adjuntan los espacios de nombres de los nuevos paquetes sin recargar los ya cargados. Existen algunas diferencias entre library() y require() que son importante conocer, para utilizar así la más … [Leer más...] acerca de Diferencias entre library() y require() en R
Introducción al paquete dplyr del Tidyverse

Uno de los paquetes que más me gustan del R Tidyverse es dplyr. Un paquete del que no recuerdo cuántos años llevo utilizando para procesar los conjuntos de datos en R. En esta entrada vamos a ver algunas operaciones básicas que se pueden realizar con las funciones de este paquete, para lo que utilizaremos la sintaxis que nos ofrece el operador de tubería (pipe) que vimos la … [Leer más...] acerca de Introducción al paquete dplyr del Tidyverse
Las tuberías del Tidyverse (Pipeline)

Posiblemente una de las características más llamativas del Tidyverse es el operador tubería o "pipeline" (%>%). Un operador que permite concatenar varias operaciones de una forma sencilla y eficiente. Ofreciendo una forma bastante clara de expresar las operaciones a realizar sobre un conjunto de datos. Veamos a continuación como funcionan las tuberías del Tidyverse.El … [Leer más...] acerca de Las tuberías del Tidyverse (Pipeline)
Introducción al Tidyverse

La preparación de los datos es una de las tareas más tediosas y frustrantes a las que nos enfrentamos los científicos de datos. En R tenemos una colección de paquetes que nos permite realizar estas tareas de una forma eficiente: el Tidyverse. En esta introducción a Tidyverse quiero explicar qué es el Tidyverse y cuales son los paquetes que los forman. Dejando para futuras … [Leer más...] acerca de Introducción al Tidyverse
Truco R: Creación de diagramas de Venn en R

Los diagramas de Venn es una gráfica en la que se muestran las relaciones entre diferentes colecciones de conjuntos. En estos diagramas los conjuntos se representan como regiones cerradas y las intersecciones indican el grado de relación. Veamos cómo se pueden crear fácilmente diagramas de Venn en R.Paquete eulerrPara la creación de los diagramas de Venn en R vamos a … [Leer más...] acerca de Truco R: Creación de diagramas de Venn en R
Crear imagen Docker con Shiny Server

A la hora de distribuir aplicaciones creadas con Shiny nos podemos plantar la idea de usar imágenes de Docker. Algo que nos permite evitar posibles problemas de incompatibilidad debido a no disponer de la versión correcta de R, Shiny o cualquier otro paquete en el servidor. Una vez creada la aplicación crear una imagen de Docker con Shiny Server es relativamente sencillo, por … [Leer más...] acerca de Crear imagen Docker con Shiny Server