
Dentro del aprendizaje automático, es habitual tener que trabajar con conjuntos de datos multidimensionales donde las variables están interrelacionadas. En estos casos, para cuantificar la similitud entre puntos, es aconsejable tener en cuenta la estructura de los propios datos. Algo que no sucede en las distancias usadas habitualmente como la Euclídea. Una métrica que si tiene … [Leer más...] acerca de La distancia de Mahalanobis
Integración de aplicaciones locales en Internet con servicios en desarrollo mediante Serveo

Durante el desarrollo de una aplicación a menudo nos encontramos con la necesidad de integrar servicios externos que requieren de una dirección pública para responder. Por ejemplo, servicios de autenticación o API de terceros. Algo que es problemático cuando la aplicación solo responde en localhost. Una solución es publicar está en un servidor de desarrollo que tenga una … [Leer más...] acerca de Integración de aplicaciones locales en Internet con servicios en desarrollo mediante Serveo
Limpieza de datos con Pyjanitor: Optimizando los flujos de trabajo

Contar con unos datos de calidad es clave para que los resultados de un análisis de datos sean válidos. Sin embargo, en la mayoría de las ocasiones, los conjuntos de datos suelen tener múltiples problemas de calidad. Por ejemplo, la presencia de valores nulos, nombres de columnas no estandarizados y datos mal formateados. En esta entrada se analizará las opciones existentes … [Leer más...] acerca de Limpieza de datos con Pyjanitor: Optimizando los flujos de trabajo
Explorando Local Outlier Factor (LOF): Un enfoque eficaz para la detección de anomalías

Los modelos de detección de anomalías es una parte del aprendizaje automático en la que cada vez existe un mayor interés. Siendo una tarea crítica en diferentes áreas como la seguridad informática, el mantenimiento predictivo o el monitoreo de la salud. Uno de los algoritmos más populares para esta tarea es Local Outlier Factor (LOF). Este algoritmo identifica las anomalías de … [Leer más...] acerca de Explorando Local Outlier Factor (LOF): Un enfoque eficaz para la detección de anomalías
Solución del error 504 Gateway Timeout en NGINX

Uno de los problemas más habituales que se suelen observar en los servidores proxy son los errores 504 Gateway Timeout. Lo que indica que el servidor proxy no ha podido recibir la respuesta del otro servidor en el tiempo asignado. La causa por la que se muestra este error puede ser múltiple: un problema de saturación temporal en el servidor, un problema de conectividad entre … [Leer más...] acerca de Solución del error 504 Gateway Timeout en NGINX
Introducción a Pyjanitor: Simplificando la limpieza y transformación de datos en Python
El proceso de limpieza y transformación de datos es una fase clave que se debe realizar antes de cualquier análisis en un proyecto de ciencia de datos. Siendo una fase clave para el éxito del proyecto. Generalmente, trabajar con datos desordenados o mal formateados es una tarea ardua que puede llegar a consumir mucho tiempo. Para solucionar esto existen bibliotecas como … [Leer más...] acerca de Introducción a Pyjanitor: Simplificando la limpieza y transformación de datos en Python
Introducción a XGBoost: Instalación y primeros pasos

XGBoost (Extreme Gradient Boosting) es un algoritmo que ha ganado popularidad entre los científicos de datos debido a su potencia y eficiencia. En esta entrada se explicará qué es XGBoost, cómo instalarlo en Python y un cómo se puede usar en un caso práctico.¿Qué es XGBoost?XGBoost es un algoritmo de aprendizaje supervisado basado en árboles de decisión, diseñado para … [Leer más...] acerca de Introducción a XGBoost: Instalación y primeros pasos
Creación de certificados SSL con OpenSSL

La seguridad de las conexiones es algo clave en la era digital. Para garantizar la seguridad en las comunicaciones entre los navegadores y los servidores web es necesario contar con certificados SSL (del inglés Secure Sockets Layer). Estos certificados cifran los datos y autentican la identidad del servidor. En el caso de tener un servidor público en Internet estos deben ser … [Leer más...] acerca de Creación de certificados SSL con OpenSSL
Uso del método df.describe() de Pandas para el análisis de datos

Pandas es la biblioteca de referencia para el análisis de datos en Python. Lo que es debido a ofrecer una gran cantidad de funciones para la manipulación y análisis altamente eficientes y fáciles de utilizar. Posiblemente uno de los mejores ejemplos de estos es el método df.describe(). Una función que produce un resumen estadístico del contenido de un DataFrame que permite … [Leer más...] acerca de Uso del método df.describe() de Pandas para el análisis de datos
Semana sin publicaciones

Como es habitual durante esta semana no habrá nuevas publicaciones en Analytics Lane, pero no os preocupes ya que volveremos con nuevas publicaciones el lunes 1 de abril.Quiero recordaros que para estar al día de todas las publicaciones y no perderos nada disponéis de varios medios. El boletín de noticias se envía todos los lunes, para recibirlo os podéis daros de alta … [Leer más...] acerca de Semana sin publicaciones
Normalización de datos: Maximizando el rendimiento de los modelos de Aprendizaje Automático

La preparación de los datos es una parte clave del éxito de los modelos de aprendizaje automático o Machine Learning. Siendo una parte fundamental del trabajo para garantizar que los modelos puedan aprender de manera efectiva y eficiente. Una de las técnicas más sencillas y utilizadas durante la fase de preparación de los datos es la normalización de datos. En esta entrada, se … [Leer más...] acerca de Normalización de datos: Maximizando el rendimiento de los modelos de Aprendizaje Automático
Herramienta para evaluar el rendimiento de código JavaScript
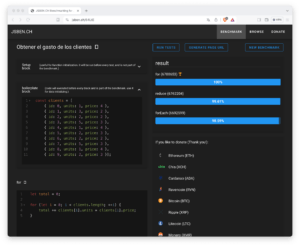
En JavaScript es habitual que exista más de una forma para implementar la misma tarea. Pero no todas son igual de rápidas, eficaces ni igual de fáciles de leer. La mejor opción para seleccionar el método más adecuado es realizar un benchmark en el que se compara el rendimiento de cada una de las opciones con un conjunto de datos. Algo que se ha hecho anteriormente en el blog … [Leer más...] acerca de Herramienta para evaluar el rendimiento de código JavaScript