
La detección de anomalías (también conocidos por su nombre en inglés outliers) son métodos de aprendizaje automático claves en múltiples sectores. Facilitando la identificación de eventos como fraudes, errores en los datos o eventos raros. Entre los métodos existentes para ello, Angle-Based Outlier Detection (ABOD) destaca con un enfoque único al usar los ángulos entre los … [Leer más...] acerca de Detectando anomalías con Angle-Based Outlier Detection (ABOD)
Aprendizaje no supervisado
Explorando Clustering-Based Local Outlier Factor (CBLOF) para la detección de anomalías

La detección de anomalías es una parte del aprendizaje automático resulta clave en múltiples aplicaciones. Poder saber qué registros son atípicos de un conjunto de datos resulta fundamental en sectores como la seguridad informática, el mantenimiento predictivo o la detección de fraudes. Uno de los algoritmos que se pueden emplear en estos casos es Clustering-Based Local Outlier … [Leer más...] acerca de Explorando Clustering-Based Local Outlier Factor (CBLOF) para la detección de anomalías
Descubriendo anomalías con HBOS (Histogram-Based Outlier Score)

Las anomalías, también conocidas como ”outliers”, son puntos que se desvían significativamente de la mayoría de los otros puntos en un conjunto de datos. Por lo que saber detectarlas es una tarea clave en múltiples aplicaciones. Empezando por la seguridad informática, donde los ataques tienen un patrón diferente al uso legítimo de los recursos, hasta en mantenimiento … [Leer más...] acerca de Descubriendo anomalías con HBOS (Histogram-Based Outlier Score)
Desmitificando Elliptic Envelope: Una exploración de la detección de anomalías con estimación de covarianza elíptica

Entre los algoritmos de Machine Learning para la detección de anomalías Elliptic Envelope destaca por su capacidad para modelar la distribución de los datos utilizando una elipse en el espacio de características. Un enfoque efectivo para identificar anomalías en conjuntos de datos multivariados donde la mayoría de los datos se distribuyen de manera normal. Lo que lo convierte … [Leer más...] acerca de Desmitificando Elliptic Envelope: Una exploración de la detección de anomalías con estimación de covarianza elíptica
Explorando Local Outlier Factor (LOF): Un enfoque eficaz para la detección de anomalías

Los modelos de detección de anomalías es una parte del aprendizaje automático en la que cada vez existe un mayor interés. Siendo una tarea crítica en diferentes áreas como la seguridad informática, el mantenimiento predictivo o el monitoreo de la salud. Uno de los algoritmos más populares para esta tarea es Local Outlier Factor (LOF). Este algoritmo identifica las anomalías de … [Leer más...] acerca de Explorando Local Outlier Factor (LOF): Un enfoque eficaz para la detección de anomalías
One-Class SVM: Detección de anomalías con máquinas de vector soporte
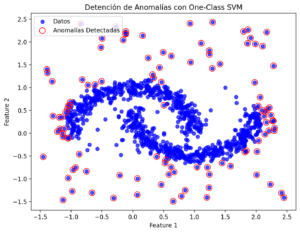
La detección de anomalías es una de las aplicaciones del aprendizaje no supervisado más utilizadas. Siendo una técnica que se emplea en casos tan diferentes como la detección de ataques cibernéticos, la detección de problemas de salud o la identificación de aplicaciones fraudulentas en servicios financieros o seguros. En todos los casos, identificar anomalías requiere localizar … [Leer más...] acerca de One-Class SVM: Detección de anomalías con máquinas de vector soporte
Isolation Forest: Detectando Anomalías con Eficacia

La detección de anomalías es uno de los desafíos más intrigantes del aprendizaje automático. Ya sea en el campo de la seguridad informática, la detección de fraudes financieros o en tareas de mantenimiento predictivo, identificar valores anómalos dentro de grandes conjuntos de datos es clave para evitar problemas en las operaciones. En esta entrada se explicará el algoritmo de … [Leer más...] acerca de Isolation Forest: Detectando Anomalías con Eficacia
Seleccionar el tipo de aprendizaje para un problema de Machine Learning

En Aprendizaje Automático o Machine Learning seleccionar el tipo de aprendizaje a usar en cada proyecto es una tarea clave para garantizar el éxito de este. Escogiendo el que sea más adecuado entre aprendizaje supervisado, no supervisado o por refuerzo. Dado que cada uno tiene características propias, haciéndolo adecuados o no para diferentes aplicaciones, seleccionar un modelo … [Leer más...] acerca de Seleccionar el tipo de aprendizaje para un problema de Machine Learning
Paquetes con el algoritmo Apriori en Python

El algoritmo Apriori es uno de los más empleados para la creación de reglas de asociación. A pesar de ello, no existe un paquete que se puede considerar el "estándar" en Python, como sucede con el caso de arules en R. En esta ocasión voy a analizar algunos paquetes que se pueden encontrar en PyPi en los que se implementa el algoritmo Apriori en Python para tener una comparativa … [Leer más...] acerca de Paquetes con el algoritmo Apriori en Python
Cómo funciona k-modes e implementación en Python

La semana pasada publiqué un artículo donde explicaba el funcionamiento del algoritmo de k-means o k-medias junto a una implementación básica en Python. Este algoritmo es uno de los más utilizados para análisis de clúster. Aunque cuenta con un problema importante, al estar basado en la métrica euclídea solamente se puede utilizar cuando todas las características del conjunto de … [Leer más...] acerca de Cómo funciona k-modes e implementación en Python
Cómo funciona k-means e implementación en Python

El algoritmo de k-means o k-medias es uno de los más utilizados dentro del análisis de clúster. Algo que se puede explicar porque este es un algoritmo sencillo, fácil de interpretar y generalmente ofrece buenos resultados en la mayoría de los conjuntos de datos. Por lo que suele estar implementado en la mayoría de las librerías estadísticas y de aprendizaje automático como … [Leer más...] acerca de Cómo funciona k-means e implementación en Python
Diferencias entre Hard y Soft Clustering
El análisis de clustering o análisis de grupo es una de las técnicas más populares dentro del aprendizaje no supervisado. Cuando se dispone de un conjunto de datos sin etiquetar, esto es no se tiene un valor o etiqueta asociado a cada registro, se puede utilizar el análisis de clustering para agrupar los elementos que son similares entres sí y separa aquellos que son … [Leer más...] acerca de Diferencias entre Hard y Soft Clustering