
En una entrada anterior se explico cómo puede afectar la forma de preguntar a las respuestas obtenidas cuando se pregunta sobre tendencia. En esta nueva entrada se explicará el efecto que puede tener el entorno en la precisión de los valores obtenidos. Analizando cómo se puede relacionar la precisión y entorno.
Las herramientas empleadas para la realización de medidas de distancia, volumen, peso, tiempo o, especialmente, dinero suelen ser bastante precisas. Los valores son siempre comparados con un patrón de referencia determinado, por ejemplo, el metro o el segundo. Los metros, básculas y relojes ofrecen siempre los mismos valores para las mismas magnitudes. Esto es independiente del entorno en que se realicen las medidas. Por otro lado, al obligar a las personas a estimar cualquiera magnitud lo realizará mediante contraste. Para ello emplea los valores conocidos existentes en el entorno en ese momento. Esto provoca que se puede obtener un valor diferente para la misma magnitud en función del entorno.
Efectos del entorno en las evaluaciones
Existen multitud de ejemplos visuales con los que se puede explorar cómo el entorno cambia la visión que se tiene de la realidad. Un ejemplo se puede apreciar en la siguiente figura donde se rodean dos círculos huecos con seis de diferente tamaño. En ambos casos el tamaño de los círculos centrales es exactamente el mismo, pero no se aprecia así. Aquí el contraste con el entorno de cada uno de los círculos hace pensar que el círculo central de la derecha es más grande que el de la izquierda. En hecho de que ambos círculos son iguales se puede comprobar con simplemente utilizando un metro.

Otro ejemplo de cómo afecta el entorno se puede ver en la siguiente figura. En esta se han dibujado dos líneas rectas con la misma longitud, pero terminadas de diferente manera. La mayoría de las personas suelen indicar que la línea superior en más larga que la de abajo. Al igual que en el caso anterior un metro permite comprobar el error de apreciación.
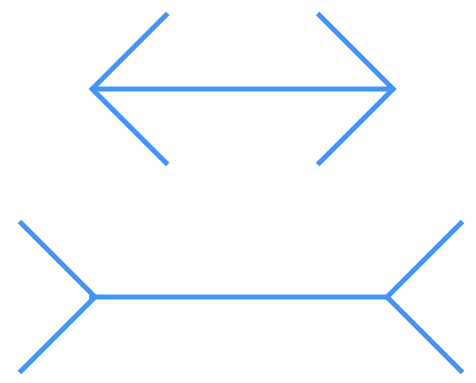
Este error introducido por el entorno se ha de tener en cuenta a la hora de evaluar la respuesta en los formularios. Al realizar una comparación, aunque esta sea inconsciente, puede provocar que se infravaloran o sobrevaloren las magnitudes preguntadas. Por ejemplo, en un entorno habituados a registros en torno a 500 un valor de 1.000 no es un suele ser valor elevado, si este mismo ejercicio se realiza en un entorno donde los registros se sitúan en torno a 100 el valor de 1.000 es muy elevado pudiendo inducir a sea infravalorado
Precisión y entorno en la Torre de Pisa
Finalmente, los ejemplos visuales presentados previamente pueden parecer un poco forzados, pero los efectos pueden ser tan sutiles como el de la siguiente figura. En esta figura se muestran dos imágenes de la Torre Inclinada de Pisa, la imagen de la derecha la torre parece más inclinada que en la de la izquierda, siendo realmente la misma. Este efecto es debido a que se toman ambas imágenes como si fuesen una única escena. En un entorno natural cuando dos torres vecinas se alzan hacia el cielo la imagen de sus contornos convergerá cuanto más se alejen de la vista. Esta norma básica de perspectiva es dada por sentada por el sistema visual y como en este caso las torres no convergen el sistema visual se ve obligado a pensar que las dos torres están separadas una de la otra.

Conclusiones
En esta entrada se ha comprobado cómo se relaciona la precisión que se puede esperar de una respuesta en función del entorno. Las personas evalúan los resultados de forma cualitativa comparando los valores con los de su entorno. Al encontrarse con un entorno donde los valores habituales son elevados, la respuesta se adaptará estimará por comparación.
En la próxima entrada de la serie abordará los efectos del pastoreo (“herding”) y auto-pastoreo (“self-herding”). Explicándole cómo se adaptan dinámicamente los valores de las respuestas a los ofrecidos anteriormente.
Imágenes: Pixabay (rawpixel) | Pixabay (John-Silver)






Deja una respuesta