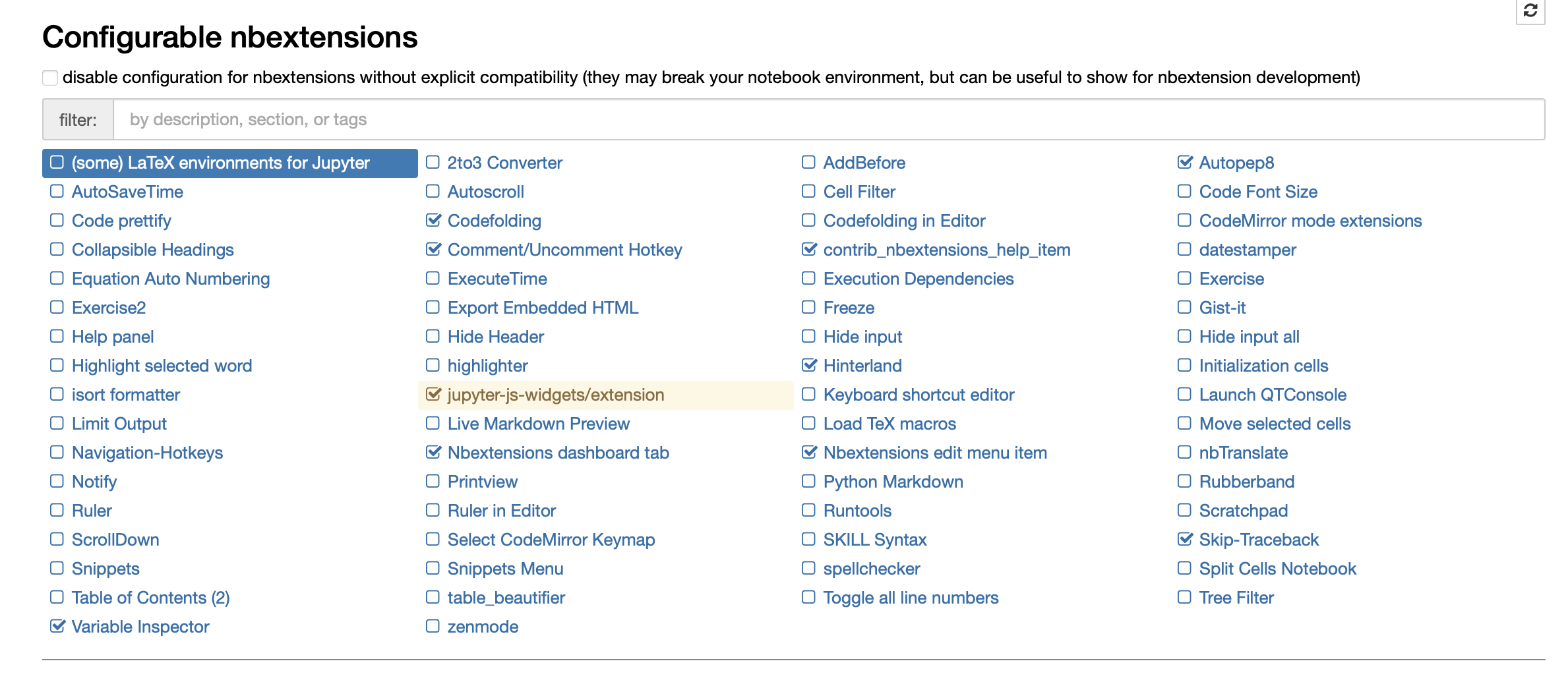
Una de las grandes virtudes de Jupyter Notebook es la posibilidad de instalar complementos con los que extender las funcionalidades. Entre los paquetes disponibles en la actualidad posiblemente uno de los más completos es jupyter_contrib_nbextensions. Un paquete que contiene más de 60 extensiones del que podéis encontrar dos entradas anteriores analizando algunas de sus herramientas para reducir las distracciones y mejorar la productividad. En el siguiente video se muestran seis extensiones de Jupyter Notebook para facilitar las tareas de codificación.
Tabla de contenidos
Instalación de jupyter_contrib_nbextensions
El proceso de instalación de jupyter_contrib_nbextensions se puede realizar de una forma sencilla gracias al comando pip. Para ello solamente se tiene que escribir en la terminal
pip install jupyter_contrib_nbextensions
Una vez hecho esto hay que configurar en Jupyter las extensiones para que este sepa de su existencia. Algo que también se puede hacer mediante la terminal escribiendo la siguiente línea
jupyter contrib nbextension install --user
comando con el que únicamente se instalará solamente en la cuenta actual, si se desea instalar para todos los usuarios es necesario cambiar la opción --user por --system.
Extensiones vistas en el video
Las extensiones que se han visto en el video son las siguientes.

Hinterland
Mejora las funciones de autocompletado de código de los Notebooks ofreciendo opciones después de cada pulsación de teclas. Facilitando de esta manera la escritura de código al evitar errores y recordar el nombre de las opciones disponibles.
Skip traceback
Al producirse un error durante la ejecución de una celda se muestra todo el rastro de este, una información que puede llegar a ser abrumadora. Si se activa la extensión Skip traceback solamente se mostrará la descripción del error ocultando la traza completa. Siendo posible consultar toda la información cuando sea necesario. De este modo, el mensaje de error generalmente únicamente requiere una línea, generando un resultado de la celda más limpio.
Autopep8
Al escribir código para pruebas puede que no respetemos todas algunas de las normas de estilo de Python. Para solucionar este problema existen los formateadores de código como autopep8. La activación de este complemento permite integrar esta herramienta en Jupyter Notebook, de modo que solamente pulsado un botón se formatee automáticamente el código de la celda activa.
El complemento no incluye el autopep8, por lo que es necesario instalarlo previamente. Para lo que solamente deberemos ir a la línea de comandos y escribir
pip install autopep8
Codefolding
A medida que crece el código, por ejemplo, al escribir múltiples métodos para una clase, puede que no sea interesante ver todos los detalles. Para estas situaciones, en los editores de textos modernos existe la posibilidad de compactar las funciones, métodos, clases y comentarios. En Jupyter Notebook esta funcionalidad se puede conseguir mediante este complemento.
Coment/Uncoment
En muchas ocasiones es necesario comentar o quitar el comentario en múltiples líneas de código. Por desgracia en Python no existe un comentario de bloque, siendo necesario hacerlo en cada una de las líneas. Para solucionar este problema se puede activar el completo Coment/Uncoment gracias al cual se puede definir un atajo de teclado para realizar esta tarea.
Variable Inspector
Finalmente, el complemento Variable Inspector permite ver todas las variables que existen en la sesión actual y eliminar las que ya no sean necesarias.
Conclusiones
En el video de esta entrada se han visto seis extensiones de Jupyter Notebook para facilitar las tareas de codificación que se pueden obtener con el paquete jupyter_contrib_nbextensions. Si queréis ver videos con otras extensiones de este paquete lo podéis dejar en los comentarios del post o del video de Youtube.
Deja una respuesta