
La detección de anomalías es una parte del aprendizaje automático resulta clave en múltiples aplicaciones. Poder saber qué registros son atípicos de un conjunto de datos resulta fundamental en sectores como la seguridad informática, el mantenimiento predictivo o la detección de fraudes. Uno de los algoritmos que se pueden emplear en estos casos es Clustering-Based Local Outlier Factor (CBLOF). En esta entrada se analizará en qué consiste, cómo funciona y algunas de sus ventajas respecto a otros métodos.
Tabla de contenidos
Fundamentos de Clustering-Based Local Outlier Factor (CBLOF)
Clustering-Based Local Outlier Factor (CBLOF) es una extensión del algoritmo Local Outlier Factor (LOF) que utiliza el análisis de clúster para dividir los datos en grupos antes de calcular el factor de anomalía local para cada uno de los registros. Un enfoque puede mejorar los resultados. Básicamente, los pasos para implementar CBLOF son los siguientes:
1. Creación de una agrupación de los datos
El primer paso en CBLOF es agrupar los datos en clústeres utilizando un algoritmo como K-Means. Lo que divide el espacio de características en diferentes regiones y realizar de esta forma una evaluación más precisa del factor de anomalía local en cada una de las regiones.
2. Evaluación del factor de anomalía local
Una vez que los datos están agrupados en clústeres, se evalúa el factor de anomalía local de cada uno de los registros solamente en su clúster. No de forma global como es el cómo se hace en LOF. Lo que hace el cálculo más preciso al emplear únicamente los vecinos en el mismo clúster

Para calcular el LOF de un punto p, se sigue este proceso:
- Densidad local: Se calcula la densidad local para cada punto p como la inversa de la distancia promedio a sus k vecinos más cercanos dentro del mismo clúster. \text{Densidad Local}(p) = \frac{1}{\text{Distancia Promedio a los } k \text{ Vecinos Más Cercanos}}
- Densidad de vecinos: Se calcula la densidad de los clústeres vecinos al clúster al que pertenece p. Esto se hace localizando los k vecinos más cercanos de p que pertenecen a diferentes clústeres y calculando la densidad local para cada uno de estos.
- Factor de anomalía local (LOF): El LOF de p se calcula como la razón entre la densidad local de p y la densidad media de sus vecinos. \text{LOF}(p) = \frac{\text{Densidad Local}(p)}{\text{Densidad Media de los Vecinos}}
Un LOF alto indica que p es valor poco probable, lo que sugiere que podría ser una anomalía.
3. Identificación de anomalías
Finalmente, los registros con un LOF alto son identificados como anomalías, ya que tienen una densidad local significativamente menor que la de sus vecinos dentro del mismo clúster. Estos puntos se consideran anómalos en su entorno local y, por lo tanto, son etiquetados como anomalías.
Ventajas de CBLOF
Algunas de las ventajas de Clustering-Based Local Outlier Factor (CBLOF) en comparación con otras técnicas de detección de anomalías son las que se muestra a continuación:
- Robustez en datos con variabilidad en las densidades: CBLOF muestra una gran robustez en conjuntos de datos donde los valores de densidad local es variable. Lo que se debe a la evaluación del factor de anomalía local dentro de los clústeres. Haciendo que sea efectivo para identificar anomalías en regiones densas y dispersas.
- Interpretación intuitiva de los resultados: Al combinar el análisis de clúster con la evaluación del factor de anomalía local los resultados son más fáciles de comprender. Provocando que esto sea más fácil de interpretar que otros algoritmos.
- Mantiene un buen rendimiento en grandes conjunto de datos: CBLOF puede escalar bien a conjuntos en grandes conjuntos de datos debido a su eficiencia a la hora de calcular el factor de anomalía local dentro de los clústeres.
- Detección de patrones anómalos en regiones: Al evaluar el factor de anomalía local dentro de clústeres, CBLOF es capaz de detectar anomalías locales en diferentes regiones. Esto lo hace efectivo para identificar anomalías que pueden estar en áreas específicas.
- No requiere el ajuste de hiperparámetros altamente sensibles: CBLOF no requiere ajuste de hiperparámetros sensibles como el número de árboles en Isolation Forest o la selección de la función de kernel en One-Class SVM. Esto hace más sencillo su utilización por partes de usuarios con poca experiencia.
- Independiente de distribución: A diferencia de otros métodos como Elliptic Envelope, CBLOF no hace suposiciones específicas sobre la distribución subyacente de los datos. Por lo tanto, puede adaptarse a una variedad más amplia de conjuntos de datos con diferentes distribuciones.
Clustering-Based Local Outlier Factor (CBLOF) ofrece varias ventajas, incluida su robustez en conjuntos de datos con variabilidad en la densidad, una interpretabilidad intuitiva, escalabilidad, capacidad para detectar anomalías locales y falta de dependencia de distribución específica. Estas características lo hacen una opción atractiva para la detección de anomalías en una amplia variedad aplicaciones.
Hiperparámetros importantes en CBLOF
Los hiperparámetros CBLOF no son claves como en otros algoritmos, pero aun así los más importantes son:
- n_clusters: El número de clústeres en los que se agruparán los datos. Este parámetro puede afectar significativamente el rendimiento de CBLOF y debe seleccionarse cuidadosamente para cada conjunto de datos.
- contamination: El porcentaje esperado de anomalías en el conjunto de datos. Este parámetro es clave para determinar el umbral a partir del cual se identifican los registros como anomalías.
- alpha: Un parámetro que controla la sensibilidad de CBLOF al ruido en los datos. Al aumentar el valor de alpha se pueden reducir el impacto del ruido en la detección de anomalías, pero también pueden aumentar el riesgo de obtener falsos negativos en la detección de anomalías.
Uso de Clustering-Based Local Outlier Factor (CBLOF) en Python
Actualmente CBLOF no está implementado en Scikit-learn, pero si existe una implementación en la librería PyOD. Una librería de Python especializada en algoritmos de detección de anomalías. Como es habitual se puede instalar a través de pip escribiendo el siguiente comando:
pip install pyod
Alternativamente, para aquellos que usan conda, se puede instalar con el siguiente comando:
conda install -c conda-forge pyod
Una vez instalado PyOD en el sistema, ya se puede usar implementar modelos basado en CBLOF, al igual que otros algoritmos, para la detección de anomalías.
Creación de un conjunto de datos de ejemplo
Antes de poder evaluar CBLOF en Python es necesario contar con un conjunto de datos con anomalías. Una de las opciones es crear un conjunto de datos, por ejemplo, con la función de make_moons() de Scikit-learn, y agregar datos aleatorios al conjunto de datos. Esto es lo que se hace en el siguiente ejemplo.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
# Generar el conjunto de datos de moons con ruido
X, _ = make_moons(n_samples=1000, noise=0.1, random_state=42)
# Agregar algunas anomalías artificiales
outliers = np.random.uniform(low=-2, high=3, size=(50, 2))
X = np.vstack([X, outliers])
# Visualizar el conjunto de datos
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], s=10)
plt.title("Conjunto de Datos de Moons con Anomalías")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()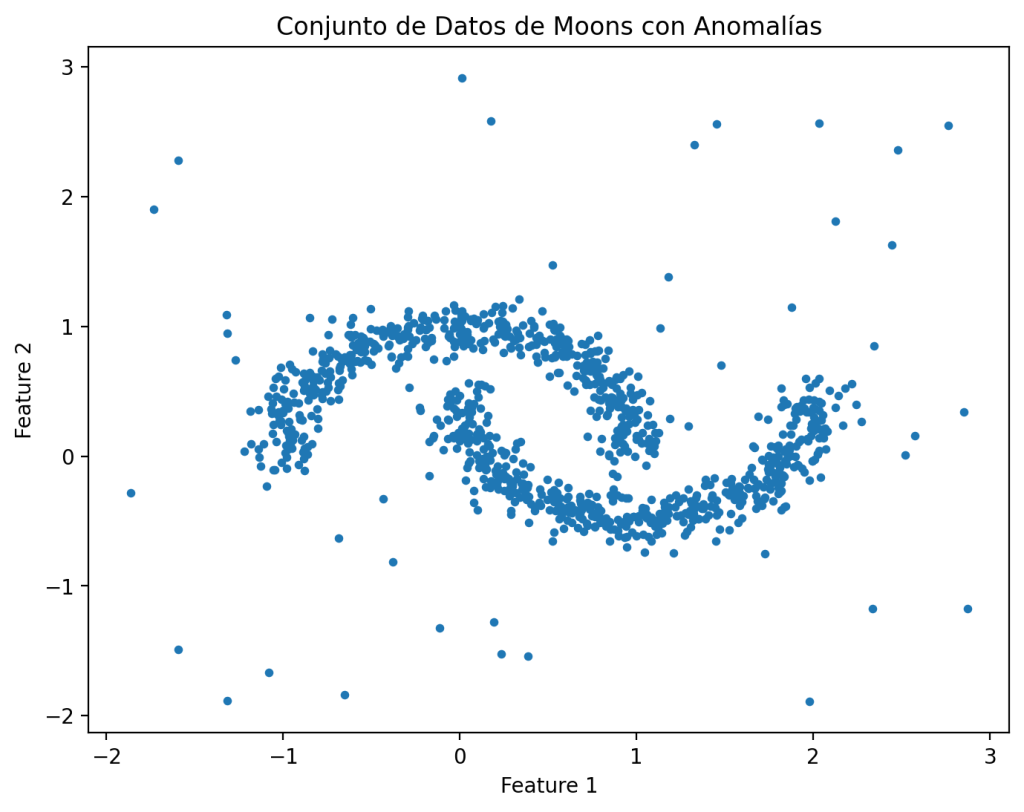
En este ejemplo, en primer lugar, se importan las funciones y se crea un conjunto de datos aleatorios con la make_moons(). Fijando la semilla a 42 para que los resultados sean fácilmente reproducibles. Posteriormente se agregan unos outliers con las funciones aleatorias de NumPy. Finalmente, se crea una gráfica para ver el conjunto de datos generado.
Creación de un modelo
Una vez se dispone de los datos en los que se desea detectar las anomalías solamente se tiene que importar la clase CBLOF de PyOD para entrenar el modelo. Lo que se muestra en el siguiente ejemplo.
from pyod.models.cblof import CBLOF
# Inicializar y ajustar el modelo CBLOF
cblof_model = CBLOF(contamination=0.1, n_clusters=8) # Definimos la proporción de datos que consideramos anomalías y el número de clústeres
cblof_model.fit(X)
# Obtener las puntuaciones de anomalía
anomaly_scores = cblof_model.decision_scores_
# Etiquetar los puntos de datos como anomalías o no anomalías
labels = cblof_model.predict(X)
# Visualizar el conjunto de datos con las anomalías detectadas
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='coolwarm', s=10)
plt.title("Conjunto de Datos de Moons con Anomalías Detectadas (CBLOF)")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
En este caso, una vez importado CBLOF, se crea una instancia del modelo con una contaminación del 10%, la proporción de los datos en el modelo de entrenamiento que se consideran anomalías, y 8 clusters. A continuación, se llama al método fit() con el conjunto de datos usado. Las puntuaciones de las anomalías en el conjunto de datos de entrenamiento se pueden obtener del parámetro decision_scores_. Aunque, como es habitual, es más interesante usar el método predict() para obtener una predicción de las anomalías. Finalmente, se usa el resultado para crear una gráfica donde las anomalías y los datos se representan con un color diferente.
En este ejemplo, se puede ver como CBLOF detecta bastante bien las anomalías en este conjunto de datos. Como es habitual el uso para que el algoritmo muestre más o menos anomalías se puede gestionar con el parámetro contamination. En el ejemplo se ha decidido un 10%, pero es un valor que se puede cambiar.
Conclusiones
Clustering-Based Local Outlier Factor (CBLOF) es un algoritmo para la detección de anomalías que combina la agrupación de datos con la evaluación de la rareza local. Lo que le permite obtener una gran precisión. Al identificar anomalías dentro de clústeres específicos, CBLOF puede proporcionar una detección efectiva de anomalías en conjuntos de datos heterogéneos y con diferentes densidades locales.
Imagen de Nicky ❤️🌿🐞🌿❤️ en Pixabay
Deja una respuesta