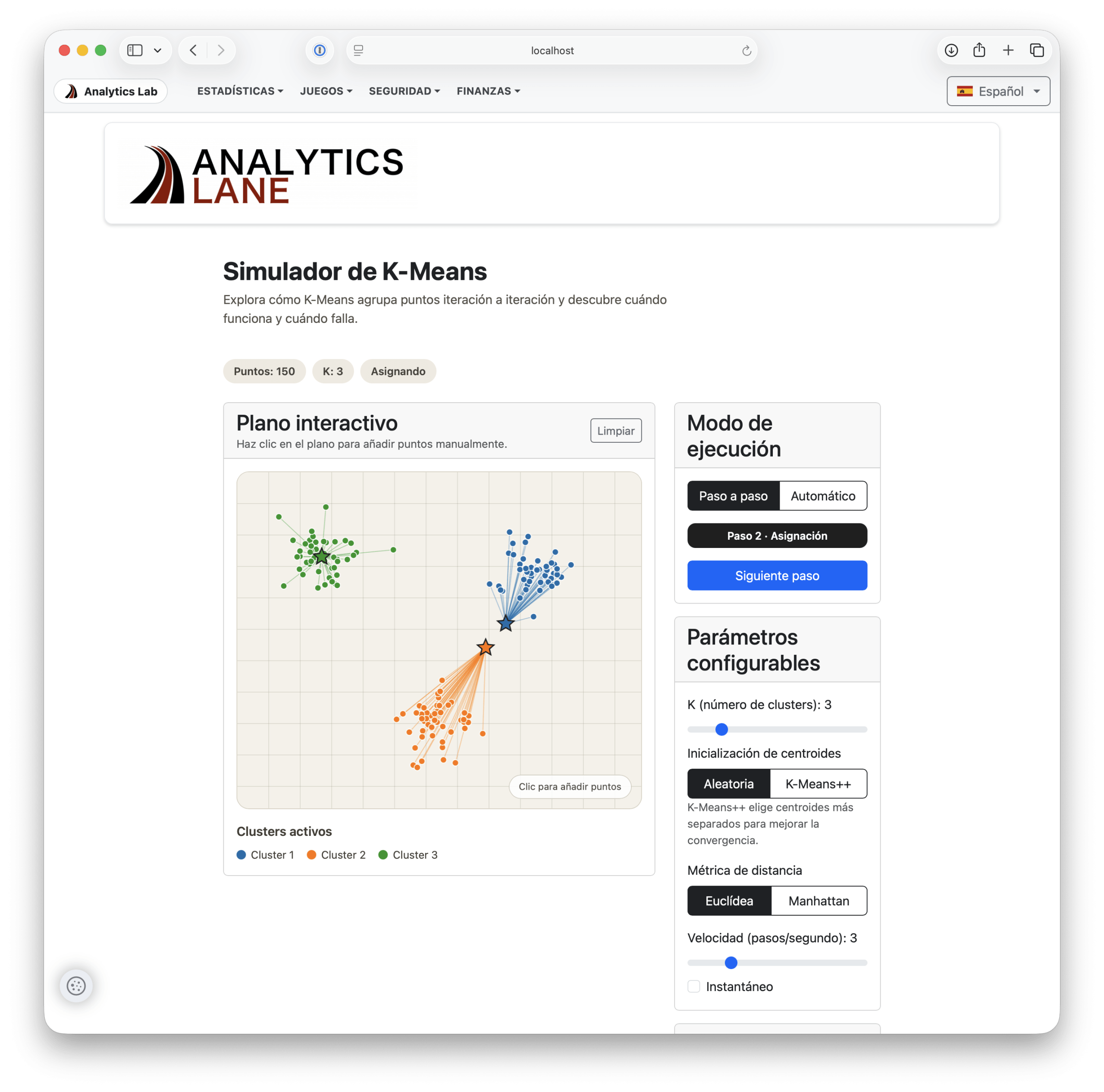
El laboratorio de aplicaciones interactivas de Analytics Lane continúa ampliándose con nuevas herramientas orientadas a la exploración visual de algoritmos de ciencia de datos. En esta ocasión se incorpora un simulador interactivo del algoritmo de clustering K-Means, diseñado para mostrar de forma intuitiva cómo funciona este método de aprendizaje no supervisado.
La aplicación permite observar paso a paso cómo el algoritmo converge, desde la inicialización de los centroides hasta la asignación final de los puntos a sus respectivos clusters. El objetivo es facilitar una comprensión visual de uno de los algoritmos más utilizados en análisis de datos y aprendizaje automático.
Puedes utilizar el simulador online accediendo desde el menú principal del Laboratorio de Analytics Lane o directamente a través del siguiente enlace.
Tabla de contenidos
Comprender K-Means de forma visual
El algoritmo K-Means busca dividir un conjunto de datos en K grupos o clusters, de manera que los puntos dentro de cada grupo sean lo más similares posible entre sí y lo más diferentes posible de los de otros grupos.
Para ello, el algoritmo sigue un proceso iterativo relativamente simple:
- Se colocan K centroides iniciales.
- Cada punto del dataset se asigna al centroide más cercano.
- Los centroides se recalculan como la media de los puntos asignados a cada cluster.
- El proceso se repite hasta que los centroides dejan de cambiar de posición.
Aunque el procedimiento es sencillo (véase la entrada “Cómo funciona k-means e implementación en Python” para mas detalles), su comportamiento puede resultar difícil de imaginar sin una representación visual. Este simulador permite ver exactamente cómo evolucionan los clusters en cada iteración.

Diferentes formas de generar datos
Para experimentar con distintos escenarios, la herramienta permite poblar el plano interactivo de varias maneras:
- Clic manual: el usuario puede añadir puntos libremente en el plano.
- Datasets predefinidos: ejemplos preparados que ilustran distintos casos, como grupos bien separados, clusters solapados, distribuciones circulares o datos alineados.
- Generación aleatoria: creación automática de puntos mediante distribuciones gaussianas alrededor de centros aleatorios.
- Reinicio del plano: opción para limpiar todos los puntos y comenzar una nueva simulación.
Estos modos permiten analizar tanto situaciones donde K-Means funciona bien como otras donde presenta limitaciones.
Parámetros configurables
El simulador permite ajustar distintos parámetros del algoritmo para observar cómo influyen en el resultado final:
- Número de clusters (K): configurable entre 2 y 8.
- Inicialización de centroides: aleatoria o mediante K-Means++, un método que mejora la selección inicial de centros.
- Métrica de distancia: Euclídea o Manhattan.
- Velocidad de ejecución: desde un paso por segundo hasta ejecución instantánea.
Modificar estos parámetros permite explorar cómo cambian las particiones obtenidas y cómo afecta la elección inicial de los centroides.
Ejecución paso a paso
Uno de los modos más didácticos de la aplicación es el modo paso a paso, donde el usuario puede avanzar manualmente por cada etapa del algoritmo.
Cada fase se muestra claramente en pantalla:
- Inicialización: colocación de los centroides iniciales.
- Asignación: cada punto se asigna al centroide más cercano y se colorea según su cluster.
- Actualización: los centroides se desplazan hacia la media de los puntos asignados.
- Comprobación de convergencia: si los centroides dejan de moverse, el algoritmo termina.
Las animaciones permiten observar cómo los centroides se desplazan gradualmente hasta estabilizarse.
Modo automático
También es posible ejecutar el algoritmo en modo automático, donde el sistema avanza por las iteraciones a la velocidad seleccionada hasta alcanzar la convergencia.
El usuario dispone de controles para iniciar, pausar o reiniciar la simulación, lo que facilita experimentar con distintos datasets y configuraciones.
Visualización del proceso
La aplicación incluye varios elementos visuales que ayudan a interpretar el funcionamiento del algoritmo:
- Los puntos se colorean según el cluster asignado.
- Los centroides se representan con símbolos diferenciados, más grandes que los puntos.
- Durante la asignación se pueden mostrar líneas que conectan cada punto con su centroide.
- Una vez alcanzada la convergencia, se dibujan regiones de Voronoi que muestran los límites de decisión entre clusters.
Estas representaciones permiten entender cómo se estructura el espacio de datos en torno a los centroides.
Información del estado del algoritmo
El simulador incluye un panel que muestra información en tiempo real sobre la ejecución:
- Número de iteraciones realizadas.
- Cambio total en la posición de los centroides entre iteraciones.
- Inercia (WCSS), que mide la suma de distancias cuadráticas dentro de cada cluster.
- Estado actual del algoritmo: inicializando, asignando puntos, actualizando centroides o convergido.
Observar cómo disminuye la inercia ayuda a comprender cómo el algoritmo optimiza progresivamente la partición de los datos.
El problema de elegir K
Uno de los desafíos más conocidos al utilizar K-Means es decidir cuántos clusters deben utilizarse.
Para ilustrar este problema, la aplicación incluye un modo especial que ejecuta automáticamente el algoritmo para distintos valores de K y construye la llamada curva del codo (elbow curve) (véase la entrada “Método del codo (Elbow method) para seleccionar el número óptimo de clústeres en K-means” para mas detallaes). En esta gráfica se representa la inercia obtenida para cada número de clusters, permitiendo identificar visualmente el punto donde añadir más clusters deja de mejorar significativamente el modelo.
Este experimento ayuda a entender cómo se selecciona K en muchos análisis de datos reales.
Un laboratorio para explorar algoritmos de aprendizaje automático
Con este nuevo simulador, Analytics Lane continúa ampliando su laboratorio de aplicaciones interactivas con herramientas diseñadas para experimentar visualmente con algoritmos de ciencia de datos y aprendizaje automático.
La posibilidad de manipular los datos, observar cada iteración del algoritmo y comparar distintos escenarios convierte a esta aplicación en una forma accesible y práctica de comprender cómo funciona realmente K-Means y cuáles son sus limitaciones.
Recuerda visitar el Laboratorio de Analytics Lane y descubrir todas las herramientas disponibles para analizar datos de forma rápida, precisa y accesible.
Deja una respuesta