
Localizar la posición de un elemento dado en una lista es una tarea bastante habitual. Por ejemplo, cuando necesitamos localizar los valores máximo o mínimo. Para esta tarea se puede usar el método index() de las listas de Python o, cuando estamos trabajando con vectores de NumPy existe el método where(). Veamos a continuación cómo encontrar la posición de elementos en una … [Leer más...] acerca de Cómo encontrar la posición de elementos en una lista de Python
Python
Python es un lenguaje de programación interpretado con una filosofía basada en la legibilidad del código. Un lenguaje que gracias posee un gran ecosistema de librerías para la ciencia de datos. Por lo que es uno de los más populares en la actualidad entre los científicos de datos. Además, es uno de los lenguajes más deseados y adorados por los programadores según las encuestas de Stack Overflow.
Python es un lenguaje de programación interpretado de propósito general que obliga al uso de una sintaxis clara, gracias a la cual el código es altamente legible. Siendo un lenguaje potente y fácil de aprender. Además, permite utilizar múltiples paradigmas de programación. Lo que permite usar desde programación orientada a objetos, pasando por programación imperativa o funcional.
Los paquetes de Python más utilizados por los científicos son:
- NumPy: permite el tratamiento de datos basados en matrices,
- Pandas: ideal para la manipulación de datos heterogéneos mediante objetos DataFrame,
- SciPy: implementa tareas habituales en computación científica,
- Matplotlib: facilita la visualización de datos y scikit-learn creación de modelos de aprendizaje automático.
Las publicaciones de esta sección versan sobre estas librerías y las bases del lenguaje.
NumPy: La función reshape de NumPy con ejemplos

El método que podemos usar en NumPy para redimensionar los vectores es la función reshape. Una función que es clave conocer para trabajar de forma eficaz con NumPy. Veamos a continuación como se puede usar la función reshape de NumPy a través de diferentes ejemplos.La función reshape de NumPyEn la documentación de NumPy se pude ver que la función reshape tiene la … [Leer más...] acerca de NumPy: La función reshape de NumPy con ejemplos
Imputación de valores nulos en Python

Uno de los problemas más habituales con el que podemos encontrarnos a la hora de trabajar con un conjunto de datos es la existencia de registros con valores nulos. Pudiendo ser necesario imputar un valor a estos registros para poder usarlos en un posterior análisis. Por eso en Scikit-learn existen varias clases con las que se puede realizar la imputación de valores nulos en … [Leer más...] acerca de Imputación de valores nulos en Python
Truco Python: Importar todas las hojas de un libro Excel con Pandas

Recientemente en los comentarios del blog se ha planteado el problema de cargar todas las hojas de un libro Excel en un único paso. Algo que no se puede hacer con Pandas, ya que el método read_excel() solamente puede importar una hoja. Algo que tiene sentido, ya que en un DataFrame es difícil combinar el contenido de más de una hoja de forma automática. En esta ocasión vamos a … [Leer más...] acerca de Truco Python: Importar todas las hojas de un libro Excel con Pandas
Pandas: Seleccionar las primeras o últimas filas de un DataFrame Pandas con head() o tail()

Hoy vamos a explicar cómo seleccionar las primeras o últimas filas de un DataFrame, para lo que usaremos las métodos head() y tail().Conjunto de datos de ejemploEn esta ocasión vamos a utilizar el conjunto de datos planets que podemos encontrar en la librería Seaborn. Para importarlos solamente hay que utilizar la función load_dataset() con el nombre de conjunto de … [Leer más...] acerca de Pandas: Seleccionar las primeras o últimas filas de un DataFrame Pandas con head() o tail()
Uso de las f-string de Python para mejorar el formato de textos

Los literales de cadenas formateados o f-string de Python es una herramienta que facilita crear interpolaciones en cadenas de texto. Simplificando de este modo tanto la lectura como la escritura de estas. Las f-string se introdujo en la versión 3.6 de Python, por lo que es algo relativamente nuevo. Veamos cómo se pueden usar para crear mensajes de una forma más fácil.¿Qué … [Leer más...] acerca de Uso de las f-string de Python para mejorar el formato de textos
Combinar diagramas de caja e histogramas en Python con Seaborn
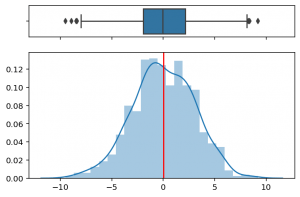
Los diagramas de caja ("boxplot") o diagramas de bigote son una excelente herramienta para representar características de un conjunto de datos como la dispersión y la simetría. Otro gráfico que también nos permite observar estas características en los conjuntos de datos son los histogramas. Por lo que, en ciertas ocasiones, puede ser una buena idea combinar ambos en un único … [Leer más...] acerca de Combinar diagramas de caja e histogramas en Python con Seaborn
Pandas: El método merge de Pandas
Hace tiempo hemos visto una entrada en la que se explicaba cómo unir y combinar objetos DataFrame en Pandas. Una entrada en la que se había utilizado los métodos concat y merge. El método merge de Pandas ofrece muchas posibilidades, por lo que vamos a ver las opciones que nos ofrece.El método merge de PandasEn Pandas existe el método merge() con el que se pueden … [Leer más...] acerca de Pandas: El método merge de Pandas
Acelerar el código Python con Numba

Posiblemente Python sea uno de nuestros leguajes de programación favoritos debido a su sencillez y potencia. Pero hay que reconocer que es lento al compararlos con otros como pueden ser C, Julia o JavaScript. Por eso existen múltiples soluciones para aumentar el rendimiento del código Python. Algunas que hemos visto en entradas anteriores son el uso de cauces con lru_cache o la … [Leer más...] acerca de Acelerar el código Python con Numba
Pandas: Omitir filas de un archivo CSV
Las funciones de Pandas para trabajar con archivos CSV nos ofrecen múltiples posibilidades que nos pueden facilitar las tareas con estos documentos. Una de estas funciones es la que permite eliminar algunas filas de un archivo CSV en Pandas.Propiedades para omitir filas de un archivo CSV en PandasBásicamente existen dos propiedades con las que se pueden indicar a la … [Leer más...] acerca de Pandas: Omitir filas de un archivo CSV
Convertir números en cadenas y cadenas en números en Python

Python ofrece múltiples posibilidades para convertir las cadenas de texto en números y viceversa. Una tarea que es bastante habitual por ejemplo cuando se interactúa con usuarios, ya que estos siempre usan cadenas de texto para comunicarse. Por eso vamos a ver en esta ocasión cómo se pueden convertir los números en cadenas de texto y las cadenas en números en Python. Aunque en … [Leer más...] acerca de Convertir números en cadenas y cadenas en números en Python
SQLite en Python

En el caso de que necesitemos una base de datos SQL para guardar datos en nuestra aplicación podemos recurrir a SQLite. Una base de datos ligera que se puede utilizar sin la necesidad de descargar, instalar y configurar ningún software. Solamente es necesario importar el paquete sqlite3, incluido en la instalación de Python. Así que veamos la forma de trabajar con SQLite en … [Leer más...] acerca de SQLite en Python