
El método empty() permite crear matrices en NumPy sin la necesidad de inicializar los valores de estos. Esto es, crea matrices con los valores que en ese momento se encuentren en memoria. Aunque también se pueden crear matrices varias sin elementos en una dimensión. Junto a este método se puede utilizar el método append() para ir agregando poco a poco los valores de las … [Leer más...] acerca de NumPy: Crear matrices vacías en NumPy y adjuntar filas o columnas
Python
Python es un lenguaje de programación interpretado con una filosofía basada en la legibilidad del código. Un lenguaje que gracias posee un gran ecosistema de librerías para la ciencia de datos. Por lo que es uno de los más populares en la actualidad entre los científicos de datos. Además, es uno de los lenguajes más deseados y adorados por los programadores según las encuestas de Stack Overflow.
Python es un lenguaje de programación interpretado de propósito general que obliga al uso de una sintaxis clara, gracias a la cual el código es altamente legible. Siendo un lenguaje potente y fácil de aprender. Además, permite utilizar múltiples paradigmas de programación. Lo que permite usar desde programación orientada a objetos, pasando por programación imperativa o funcional.
Los paquetes de Python más utilizados por los científicos son:
- NumPy: permite el tratamiento de datos basados en matrices,
- Pandas: ideal para la manipulación de datos heterogéneos mediante objetos DataFrame,
- SciPy: implementa tareas habituales en computación científica,
- Matplotlib: facilita la visualización de datos y scikit-learn creación de modelos de aprendizaje automático.
Las publicaciones de esta sección versan sobre estas librerías y las bases del lenguaje.
Tema oscuro en Jupyter Notebook
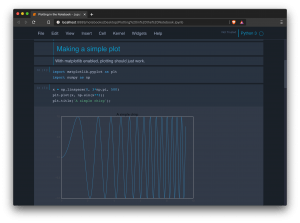
Personalmente me gusta trabajar con temas oscuros en las aplicaciones. Lo que hace que la pantalla brille menos y, por lo menos desde mi punto de vista, es más agradable. Algo que posiblemente ya habréis notado los lectores habituales en las diferentes capturas de pantalla. Una de las aplicaciones que más uso es Jupyter Notebook, en el que no existe un gestor de temas por … [Leer más...] acerca de Tema oscuro en Jupyter Notebook
NumPy: Ordenar matrices de NumPy por fila o columna
Cuando estamos trabajando en NumPy con matrices, arrays 2D, nos podemos plantear cómo reordenar estas en base a los valores de las filas o las columnas. Una operación que se puede realizar fácilmente utilizando el método argsort() presente en los array de NumPy. En esta entrada veremos los métodos para ordenar matrices de NumPy por fila o columna.Creación de una … [Leer más...] acerca de NumPy: Ordenar matrices de NumPy por fila o columna
Pandas: Obtener el nombre de las columnas y filas en Pandas

En esta pequeña entrada vamos a ver cómo se pueden obtener el nombre de las columnas y filas en Pandas. Una tarea que parece trivial, pero es importante cuando se importan datos desde archivos externos.Creación de un DataFramePara obtener el nombre de las columnas y filas en un DataFrame Pandas es necesario disponer de una en memoria. En esta ocasión crearemos … [Leer más...] acerca de Pandas: Obtener el nombre de las columnas y filas en Pandas
Pandas: Leer archivos CSV con diferentes delimitadores en Pandas.
La función read_csv() de Pandas permite importar archivos en formato CSV de una forma fácil. Por defecto, la función asume que el separador de los valores es la coma (,), pero este es un comportamiento que se puede cambiar. Incluso para usar más de un delimitado en el mismo archivo. En esta entrada vamos a ver cómo trabajar con archivos CSV con diferentes delimitadores en … [Leer más...] acerca de Pandas: Leer archivos CSV con diferentes delimitadores en Pandas.
NumPy: Cómo ordenar una matriz NumPy en Python
En NumPy existe el método np.sort() con el que se puede ordenar una matriz NumPy. Un método que ofrece varias opciones las que discutiremos a continuación.Ordenar un vectorEn primer lugar, podemos crear un vector de números enteros ordenados aleatoriamente. Lo que se puede conseguir utilizando el método np.random.shuffle() sobre un vector que se ha creado con … [Leer más...] acerca de NumPy: Cómo ordenar una matriz NumPy en Python
Pandas: Cómo crear un DataFrame vacío y agregar datos
El objeto DataFrame es uno de los elementos clave de la librería Pandas. En esta entrada vamos a ver las opciones que existen para crear un DataFrame vacío y agregar datos. Lo que nos enseñara además algunos de los métodos que existen para modificar el contenido de un DataFrame.Creación de un DataFrame vacíoUn DataFrame vacío se puede crear utilizando el constructor … [Leer más...] acerca de Pandas: Cómo crear un DataFrame vacío y agregar datos
Pandas: Cómo convertir listas en DataFrames
Posiblemente una de las operaciones más habituales con Pandas sea convertir listas en DataFrames. Lo que se puede hacer con el constructor DataFrame de la librería.Creación de DataFrames desde una lista de listas o de tuplasPosiblemente la forma más sencilla para crear un DataFrame a partir de una lista es cuando tenemos una lista de listas, o una lista de tuplas. Por … [Leer más...] acerca de Pandas: Cómo convertir listas en DataFrames
Trucos para comprensión de listas en Python
La comprensión de listas en Python hace referencia a los procedimientos que se puede utilizar para crear nuevas listas a partir de otras. Algo que también se puede aplicar a otros tipos de colecciones. Para los que usamos Python de forma habitual esta es una técnica habitual con la que se pueden realizar tareas complejas con poco código. Por ejemplo, se puede crear un vector … [Leer más...] acerca de Trucos para comprensión de listas en Python
Redondear la hora en Python para agrupar datos
Un problema con el que nos podemos encontrar: tenemos un conjunto de datos que se captura con la hora y queremos calcular el total o la media cada 10 o 15 minutos. Por ejemplo, para crear un informe de las ventas de una tienda on-line. Este problema es fácil de resolver si sabemos redondear los datos de horas y crear tablas dinámicas. Para redondear la hora el Python se puede … [Leer más...] acerca de Redondear la hora en Python para agrupar datos
Separar texto en columnas con Pandas en Python

Cuando importamos un conjunto de datos para un análisis es habitual que los registros no estén como los necesitamos. Uno de estos casos es cuando en alguna de las columnas contiene más de un valor que necesitamos procesar por separados. Como puede ser el nombre completo o una lista de características. En esto casos se pueden utilizar el método .str.split que se puede encontrar … [Leer más...] acerca de Separar texto en columnas con Pandas en Python
Mejorar el rendimiento de Pandas con swifter

A la hora de trabajar con datos en rendimiento es un factor clave. No es lo mismo procesar un conjunto de datos en un minuto que en un segundo. A pesar de que pandas ofrece un rendimiento razonable en la mayoría de las situaciones, no es así con conjunto de datos muy grandes. Por lo existe soluciones para mejorar su rendimiento como Modin o Cython que ya hemos visto en este … [Leer más...] acerca de Mejorar el rendimiento de Pandas con swifter