
En un notebook de Jupyter cuando se están ejecutando las celdas en modo y una de estas contiene un error el proceso de ejecución se para. Ignorando el resto de las celdas a partir de aquella en la que produjo el error. Generalmente este es el comportamiento que esperaríamos. Si una celda tiene un error, posiblemente el resto tampoco puedan funcionar. Pero qué pasaría si justamente lo que se desea es enseñar ese error. En este caso se pueden ignorar los errores en las celdas de Jupyter mediante el uso del uso del tag raises-exception.
Agregar tags en las celdas de Jupyter
Es posible que algunos lectores no conozcan que se pueden incluir tags en las celdas de Jupyter para modificar el comportamiento. Para lo que se tiene que ir a menú View y dentro del submenú Cell Toolbar seleccionar la opción Tags. Al hacer esto en cada una de las celdas del notebook aparecerá una opción para incluir tags.

Ignorar errores en las celdas de Jupyter
Ahora que sabemos cómo agregar un tag a una celda de un Notebook se puede ver como funciona el tag raises-exception. Si se ejecuta una celda con errores, puede verse que una vez se alcanza esta el código deja de ejecutarse. Por ejemplo, si se usa una variable o función que no ha sido definida.

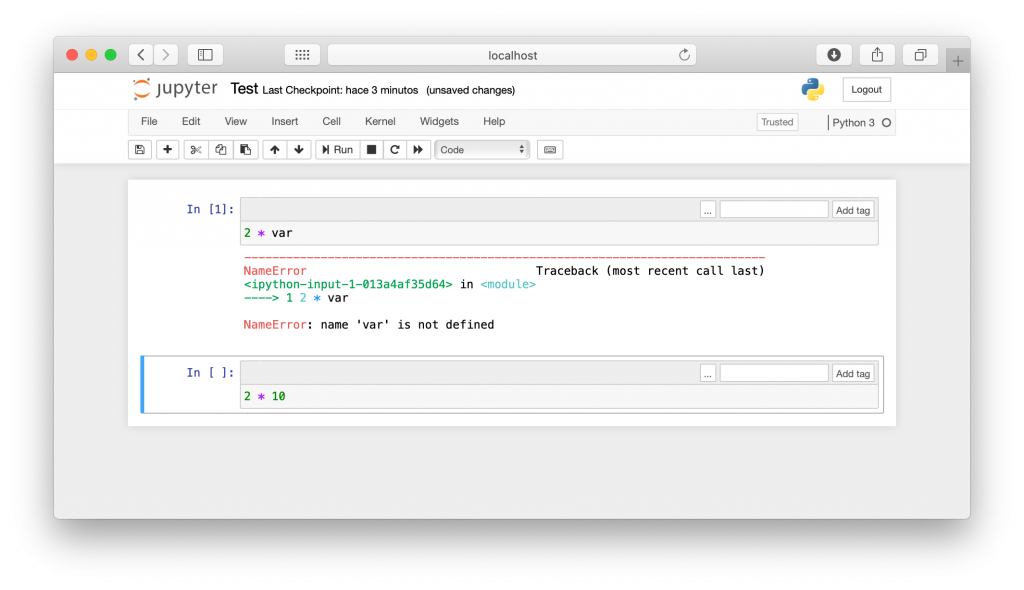
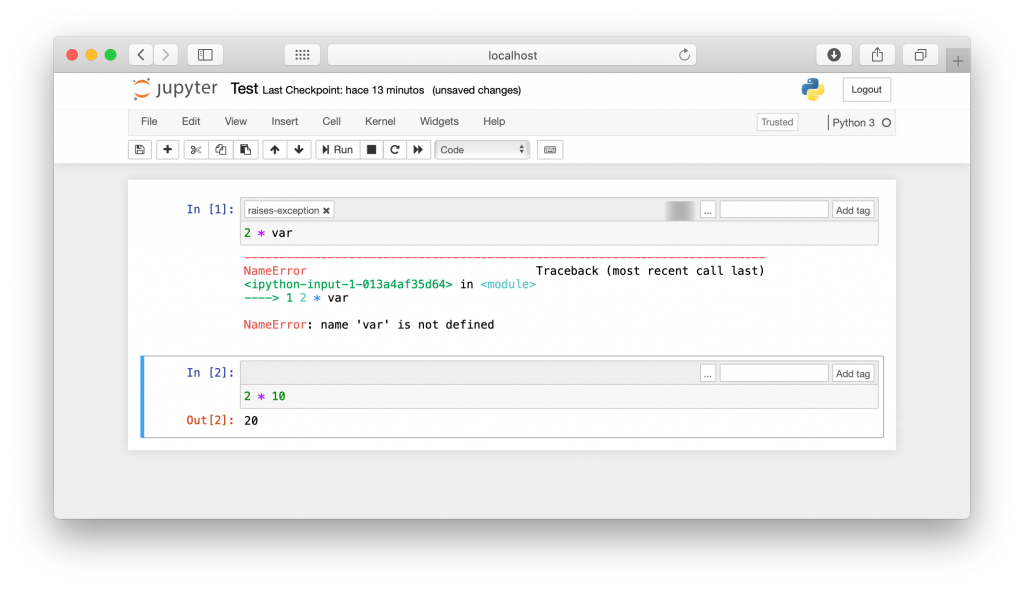
Por otro lado, si a esta celda se le agrega el tag raises-exception, vermos que, a pesar del error, el código continúa ejecutándose sin problema.
Conclusiones
Si por algún motivo necesitamos ignorar errores en las celdas de Jupyter Notebook se puede utilizar la etiqueta raises-exception para esto. Algo que puede ser de utilidad en algunas situaciones, como en los casos en los que deseamos enseñar cómo se produce un error en el código.
Imagen de Theodor Moise en Pixabay
Deja una respuesta