
Para muchas aplicaciones puede ser necesario explicar cómo se relacionan entre sí diferentes variables aleatorias de cara a comprender en detalle fenómenos complejos. Algo que es clave para la toma de decisiones informadas. Para lo que la estadística ofrece herramientas como las Cópulas. Las cópulas son unas herramientas matemáticas con las que es posible modelar la estructura … [Leer más...] acerca de Entendiendo las Cópulas en estadística
Ciencia de datos
La ciencia de datos es un área de conocimiento interdisciplinar en el cual se utilizan procesos para recopilar, preparar, analizar, visualizar y modelar datos para extraer todo su valor. Pudiéndose emplear tanto con conjuntos de datos estructurados como no estructurados. Los científicos de datos, los profesionales de esta área deben poseer grandes conocimientos de estadística e informática. Además de conocimiento de los procesos que están modelando.
Con la ciencia de datos es posible revelar tendencias y obtener información para que tanto las empresas como las instituciones puedan tomar mejores decisiones. Basando estas así en conocimiento validado no en intuiciones.
Las publicaciones de esta sección abarca diferentes temas de áreas como la estadística, la minería de datos, el aprendizaje automático y la analítica predictiva.
Explorando Clustering-Based Local Outlier Factor (CBLOF) para la detección de anomalías

La detección de anomalías es una parte del aprendizaje automático resulta clave en múltiples aplicaciones. Poder saber qué registros son atípicos de un conjunto de datos resulta fundamental en sectores como la seguridad informática, el mantenimiento predictivo o la detección de fraudes. Uno de los algoritmos que se pueden emplear en estos casos es Clustering-Based Local Outlier … [Leer más...] acerca de Explorando Clustering-Based Local Outlier Factor (CBLOF) para la detección de anomalías
Análisis de correlación para modelos de regresión: Cómo eliminar la multicolinealidad y mejorar la robustez

Los modelos de regresión son una de las técnicas estadísticas más utilizadas para comprender y predecir las relaciones entre las variables. Siendo ampliamente utilizadas en análisis de datos y aprendizaje automático. Sin embargo, cuando las variables que se desean utilizar para la construcción del modelo están altamente correlacionadas, aparece el problema de la … [Leer más...] acerca de Análisis de correlación para modelos de regresión: Cómo eliminar la multicolinealidad y mejorar la robustez
La correlación de Pearson

La correlación de Pearson es una medida estadística que evalúa la relación lineal entre dos variables continuas. Su valor puede variar entre -1 y 1, donde -1 indica una correlación negativa perfecta, 0 ninguna correlación, y 1 una correlación positiva perfecta. Siendo una herramienta fundamental en el campo de la estadística para determinar la fuerza y la dirección de la … [Leer más...] acerca de La correlación de Pearson
Descubriendo anomalías con HBOS (Histogram-Based Outlier Score)

Las anomalías, también conocidas como ”outliers”, son puntos que se desvían significativamente de la mayoría de los otros puntos en un conjunto de datos. Por lo que saber detectarlas es una tarea clave en múltiples aplicaciones. Empezando por la seguridad informática, donde los ataques tienen un patrón diferente al uso legítimo de los recursos, hasta en mantenimiento … [Leer más...] acerca de Descubriendo anomalías con HBOS (Histogram-Based Outlier Score)
Introducción al Análisis de Componentes Principales (PCA)

El Análisis de Componentes Principales (PCA) es una técnica ampliamente utilizado en aprendizaje automático. Se utiliza para reducir la dimensionalidad (el número de variables o columnas) de los conjuntos de datos manteniendo al mismo tiempo la mayor cantidad de información posible. PCA transforma las variables originales en otras nuevas, llamadas componentes principales, … [Leer más...] acerca de Introducción al Análisis de Componentes Principales (PCA)
Desmitificando Elliptic Envelope: Una exploración de la detección de anomalías con estimación de covarianza elíptica

Entre los algoritmos de Machine Learning para la detección de anomalías Elliptic Envelope destaca por su capacidad para modelar la distribución de los datos utilizando una elipse en el espacio de características. Un enfoque efectivo para identificar anomalías en conjuntos de datos multivariados donde la mayoría de los datos se distribuyen de manera normal. Lo que lo convierte … [Leer más...] acerca de Desmitificando Elliptic Envelope: Una exploración de la detección de anomalías con estimación de covarianza elíptica
La distancia de Mahalanobis

Dentro del aprendizaje automático, es habitual tener que trabajar con conjuntos de datos multidimensionales donde las variables están interrelacionadas. En estos casos, para cuantificar la similitud entre puntos, es aconsejable tener en cuenta la estructura de los propios datos. Algo que no sucede en las distancias usadas habitualmente como la Euclídea. Una métrica que si tiene … [Leer más...] acerca de La distancia de Mahalanobis
Explorando Local Outlier Factor (LOF): Un enfoque eficaz para la detección de anomalías

Los modelos de detección de anomalías es una parte del aprendizaje automático en la que cada vez existe un mayor interés. Siendo una tarea crítica en diferentes áreas como la seguridad informática, el mantenimiento predictivo o el monitoreo de la salud. Uno de los algoritmos más populares para esta tarea es Local Outlier Factor (LOF). Este algoritmo identifica las anomalías de … [Leer más...] acerca de Explorando Local Outlier Factor (LOF): Un enfoque eficaz para la detección de anomalías
Introducción a XGBoost: Instalación y primeros pasos

XGBoost (Extreme Gradient Boosting) es un algoritmo que ha ganado popularidad entre los científicos de datos debido a su potencia y eficiencia. En esta entrada se explicará qué es XGBoost, cómo instalarlo en Python y un cómo se puede usar en un caso práctico.¿Qué es XGBoost?XGBoost es un algoritmo de aprendizaje supervisado basado en árboles de decisión, diseñado para … [Leer más...] acerca de Introducción a XGBoost: Instalación y primeros pasos
Normalización de datos: Maximizando el rendimiento de los modelos de Aprendizaje Automático

La preparación de los datos es una parte clave del éxito de los modelos de aprendizaje automático o Machine Learning. Siendo una parte fundamental del trabajo para garantizar que los modelos puedan aprender de manera efectiva y eficiente. Una de las técnicas más sencillas y utilizadas durante la fase de preparación de los datos es la normalización de datos. En esta entrada, se … [Leer más...] acerca de Normalización de datos: Maximizando el rendimiento de los modelos de Aprendizaje Automático
One-Class SVM: Detección de anomalías con máquinas de vector soporte
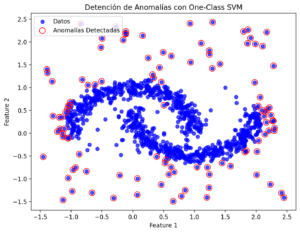
La detección de anomalías es una de las aplicaciones del aprendizaje no supervisado más utilizadas. Siendo una técnica que se emplea en casos tan diferentes como la detección de ataques cibernéticos, la detección de problemas de salud o la identificación de aplicaciones fraudulentas en servicios financieros o seguros. En todos los casos, identificar anomalías requiere localizar … [Leer más...] acerca de One-Class SVM: Detección de anomalías con máquinas de vector soporte