
La paradoja de San Petersburgo es un dilema que ha fascinado a los matemáticos, filósofos y economistas a lo largo de los siglos. Un juego aparentemente sencillo cuya solución tiene grandes implicaciones. Cuando se analiza en detalle el juego este obliga a plantearse profundas cuestiones sobre la teoría de probabilidad, la toma de decisiones y la percepción del riesgo. El … [Leer más...] acerca de Explorando la paradoja de San Petersburgo: un juego con recompensa infinita
Ciencia de datos
La ciencia de datos es un área de conocimiento interdisciplinar en el cual se utilizan procesos para recopilar, preparar, analizar, visualizar y modelar datos para extraer todo su valor. Pudiéndose emplear tanto con conjuntos de datos estructurados como no estructurados. Los científicos de datos, los profesionales de esta área deben poseer grandes conocimientos de estadística e informática. Además de conocimiento de los procesos que están modelando.
Con la ciencia de datos es posible revelar tendencias y obtener información para que tanto las empresas como las instituciones puedan tomar mejores decisiones. Basando estas así en conocimiento validado no en intuiciones.
Las publicaciones de esta sección abarca diferentes temas de áreas como la estadística, la minería de datos, el aprendizaje automático y la analítica predictiva.
La paradoja de los dos niños: desafiando la intuición

La probabilidad es un terreno fértil para las paradojas. Una de estas es la conocida como la paradoja de los dos niños, un problema cuyo resultado suele ser inicialmente desconcertante para nuestra intuición sobre probabilidad. En esta entrada se plantea el problema que produce la paradoja y se explicará el resultado.Planteamiento de la paradojaSupongamos que alguien … [Leer más...] acerca de La paradoja de los dos niños: desafiando la intuición
Comprobar si una matriz es definida positiva en Excel sin macros
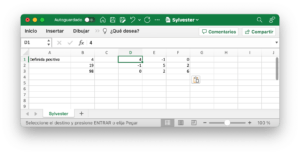
Saber identificar si una matriz es definida positiva o no es clave para muchas aplicaciones. Al igual que poder identificar si es semidefinida positiva. Por lo que contar con un método rápido para ello puede ser de gran ayuda. En esta publicación se va a explicar cómo crear una hoja de cálculo para probar si una matriz es semidefinida positiva o definida positiva en Excel sin … [Leer más...] acerca de Comprobar si una matriz es definida positiva en Excel sin macros
Atribución de escaños en Excel
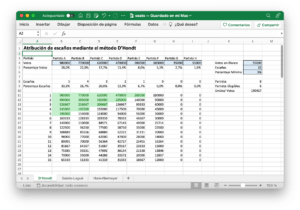
Los sistemas electorales de representación proporcional requieren traducir los votos emitidos por los electores en escaños. Algo que se puede hacer mediante diferentes métodos como pueden ser D'Hondt, Sainte-Laguë y Hare-Niemeyer. Siendo cada uno de los métodos explicado en profundidad en publicaciones anteriores, en las que además se implementaron funciones en Python para cada … [Leer más...] acerca de Atribución de escaños en Excel
Cómo analizar la proporcionalidad de un sistema de asignación de escaños

Evaluar si el reparto de escaños en un sistema electoral es justo o no es una tarea complicada. La justicia electoral es un concepto complejo, en el que se pueden dar diferentes interpretaciones que pueden cambiar según los resultados obtenidos por cada uno de los partidos. Aun así, es posible usar algunas métricas para ayudar a objetivar si el reparto es justo o no. En esta … [Leer más...] acerca de Cómo analizar la proporcionalidad de un sistema de asignación de escaños
El método de Hare-Niemeyer y su implementación en Python
En los sistemas electorales de representación proporcional distribuir los escaños entre los diferentes partidos o listas es una tarea clave. Uno de los algoritmos que se suelen utilizar para ellos es el método Haré-Niemeyer. Este método tiene como objetivo distribuir los escaños de manera proporcional a los votos obtenidos por cada partido, sin utilizar divisores como en los … [Leer más...] acerca de El método de Hare-Niemeyer y su implementación en Python
El método Sainte-Laguë y su implementación en Python
En los sistemas electorales de representación proporcional es necesario utilizar un algoritmo para asignar los escaños de las circunscripciones a los partidos o listas electorales. Convirtiendo así los votos en escaños. El método Sainte-Laguë, también conocido como el método Webster o el método de cociente y resto, es la opción que se utiliza en países como Alemania, Noruega, … [Leer más...] acerca de El método Sainte-Laguë y su implementación en Python
El método D’Hondt y su implementación en Python
En los sistemas de representación proporcional es necesario asignar a cada uno de los partidos o listas electorales un número de escaños en función de los votos recibidos. Uno de los métodos más utilizados es el método D'Hondt. Su objetivo es distribuir los escaños de manera proporcional a los votos obtenidos por cada partido o lista electoral. En esta entrada se verá en qué … [Leer más...] acerca de El método D’Hondt y su implementación en Python
Cuatro aplicaciones de la Inteligencia Artificial en la Agricultura

La agricultura es un sector clave para garantizar la subsistencia de la civilización. Actualmente, la combinación del aumento de la población y el cambio climático hace que sea necesario mejorar la producción de alimentos de forma sostenible, para garantizar el suministro actual y futuro. Siendo la inteligencia artificial (IA) una herramienta indispensable para abordar estos … [Leer más...] acerca de Cuatro aplicaciones de la Inteligencia Artificial en la Agricultura
El índice de Davies-Bouldinen para estimar los clústeres en k-means e implementación en Python

Uno de los mayores problemas a la hora de trabajar con el algoritmo de k-means es la necesidad de conocer el número de clústeres en los que se debe dividir el conjunto de datos. Para lo que existen diferentes métodos como el del codo, la Silhouette, Gap Statistics o Calinski-Harabasz. En esta ocasión se va a ver otro método bastante popular, el braseado en el índice de … [Leer más...] acerca de El índice de Davies-Bouldinen para estimar los clústeres en k-means e implementación en Python
Cuatro aplicaciones de la Inteligencia Artificial en Política

Aunque la política es una actividad puramente humana, el rápido avance de la inteligencia artificial (IA) también ha traído aplicaciones a esta área. Lo que ha dejado claro la IA es su capacidad para mejorar la eficiencia de los procesos, realizar análisis de datos sofisticados y ofrecer soluciones a problemas complejos. Necesidades que no escapan a la política. En este ensayo … [Leer más...] acerca de Cuatro aplicaciones de la Inteligencia Artificial en Política
Número óptimo de clústeres con Silhouette e implementación en Python

La Silhouette es una métrica que permite evaluar la calidad de los clústeres generados mediante algoritmos de clustering basados en la distancia euclídea. Como es el caso de k-means. Cuantificando la relación que existe entre la separación de los diferentes clústeres y la similitud entre los puntos de un mismo clúster en un valor que varía entre -1 y 1. Los valores cercanos a 1 … [Leer más...] acerca de Número óptimo de clústeres con Silhouette e implementación en Python