
Contar con unos datos de calidad es clave para que los resultados de un análisis de datos sean válidos. Sin embargo, en la mayoría de las ocasiones, los conjuntos de datos suelen tener múltiples problemas de calidad. Por ejemplo, la presencia de valores nulos, nombres de columnas no estandarizados y datos mal formateados. En esta entrada se analizará las opciones existentes … [Leer más...] acerca de Limpieza de datos con Pyjanitor: Optimizando los flujos de trabajo
Python
Python es un lenguaje de programación interpretado con una filosofía basada en la legibilidad del código. Un lenguaje que gracias posee un gran ecosistema de librerías para la ciencia de datos. Por lo que es uno de los más populares en la actualidad entre los científicos de datos. Además, es uno de los lenguajes más deseados y adorados por los programadores según las encuestas de Stack Overflow.
Python es un lenguaje de programación interpretado de propósito general que obliga al uso de una sintaxis clara, gracias a la cual el código es altamente legible. Siendo un lenguaje potente y fácil de aprender. Además, permite utilizar múltiples paradigmas de programación. Lo que permite usar desde programación orientada a objetos, pasando por programación imperativa o funcional.
Los paquetes de Python más utilizados por los científicos son:
- NumPy: permite el tratamiento de datos basados en matrices,
- Pandas: ideal para la manipulación de datos heterogéneos mediante objetos DataFrame,
- SciPy: implementa tareas habituales en computación científica,
- Matplotlib: facilita la visualización de datos y scikit-learn creación de modelos de aprendizaje automático.
Las publicaciones de esta sección versan sobre estas librerías y las bases del lenguaje.
Introducción a Pyjanitor: Simplificando la limpieza y transformación de datos en Python
El proceso de limpieza y transformación de datos es una fase clave que se debe realizar antes de cualquier análisis en un proyecto de ciencia de datos. Siendo una fase clave para el éxito del proyecto. Generalmente, trabajar con datos desordenados o mal formateados es una tarea ardua que puede llegar a consumir mucho tiempo. Para solucionar esto existen bibliotecas como … [Leer más...] acerca de Introducción a Pyjanitor: Simplificando la limpieza y transformación de datos en Python
Uso del método df.describe() de Pandas para el análisis de datos

Pandas es la biblioteca de referencia para el análisis de datos en Python. Lo que es debido a ofrecer una gran cantidad de funciones para la manipulación y análisis altamente eficientes y fáciles de utilizar. Posiblemente uno de los mejores ejemplos de estos es el método df.describe(). Una función que produce un resumen estadístico del contenido de un DataFrame que permite … [Leer más...] acerca de Uso del método df.describe() de Pandas para el análisis de datos
Inclusión de valores y variables en las f-strings de Python

Las f-strings, o formatted string literals, son una característica introducida en Python 3.6 con la que se simplifica la tarea de dar formato a las cadenas de texto. Facilitando interpolar variables y expresiones dentro de las cadenas de texto. Sin embargo, ¿sabías que las f-strings tienen una función especial que permite incluir tanto el nombre de la variable como su valor en … [Leer más...] acerca de Inclusión de valores y variables en las f-strings de Python
Introducción a SQLite 3 en Python

Las bases de datos son una parte clave de los programas que necesitan persistir información. Para pequeñas aplicaciones, donde solo se guardan unos pocos registros, recurrir a una gran base de datos relacional como pueden ser PostgreSQL, MariaDB o SQL Server no es una buena opción debido que pueden ser difíciles de configurar. En estos casos una mejor opción es un sistema … [Leer más...] acerca de Introducción a SQLite 3 en Python
Mejorando la calidad de las imágenes en Jupyter Notebook: Un enfoque completo

Jupyter Notebook se ha vuelto una herramienta fundamental para el análisis y la visualización de datos en múltiples entornos. Sin embargo, la calidad por defecto de las imágenes puede no ser adecuada en muchas aplicaciones. Por eso, en una entrada anterior, expliqué cómo cambiar esa resolución por defecto por una más adecuada en los monitores de alta resolución (HiDPI o Retina … [Leer más...] acerca de Mejorando la calidad de las imágenes en Jupyter Notebook: Un enfoque completo
El operador morsa de Python (:=): Todo lo que necesitas saber

Una buena práctica en Python, y en cualquier otro lenguaje de programación, es buscar la forma de hacer el código más limpio, conciso y legible. El operador morsa de Python (:=) es un avance significativo en este sentido. Introducido en la versión 3.8 de Python, permite asignar valor a variables donde antes no era posible. En esta publicación se explicará qué es el operador … [Leer más...] acerca de El operador morsa de Python (:=): Todo lo que necesitas saber
Eliminación de duplicados en DataFrames de Pandas
Los DataFrames de Pandas es uno de los principales objetos para el análisis de datos en Python. Al trabajar con datos reales, uno de los problemas más comunes es la presencia de valores duplicados, lo que puede afectar tanto a la integridad como a la precisión de los análisis. Afortunadamente, en los DataFrames de Pandas existen herramientas para la eliminación de duplicados de … [Leer más...] acerca de Eliminación de duplicados en DataFrames de Pandas
Comprender los parámetros *args y **kwargs de las funciones Python

Al revisar funciones de Python es habitual encontrar que estas tienen los parámetros *args y **kwargs. Unos parámetros especiales que permiten a las funciones manejar un número variables de argumentos de una forma flexible. Aunque puede parecer algo confuso al principio, cuando se comprende cómo funcionan estos parámetros es posible crear fácilmente funciones versátiles y … [Leer más...] acerca de Comprender los parámetros *args y **kwargs de las funciones Python
Cómo convertir una lista de diccionarios en un DataFrame de Pandas en Python
Al trabajar con datos en Python, es común encontrarse con la necesidad de convertir diferentes estructuras de datos en otros que sean más fáciles de manipular y analizar. Uno de estos problemas más comunes es el de convertir una lista de diccionarios en un DataFrame de Pandas. En esta entrada, se explicará cómo transformar una lista de diccionarios en un DataFrame de Pandas en … [Leer más...] acerca de Cómo convertir una lista de diccionarios en un DataFrame de Pandas en Python
Creación de Ridge Plots en Python con Seaborn: Guía completa paso a paso
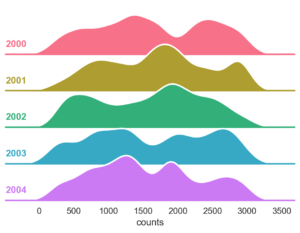
Una de las mejores opciones para poder visualizar la forma de la distribución de un conjunto de datos son los gráficos de densidad (KDE, Kernel Density Estimation). Especialmente cuando se desconoce la distribución subyacente. Si, además, para un conjunto de datos, se desea analizar cómo evoluciona la distribución a lo largo de una dimensión categórica, como puede ser el tiempo … [Leer más...] acerca de Creación de Ridge Plots en Python con Seaborn: Guía completa paso a paso
Cómo seleccionar elementos entre dos fechas con Pandas

La manipulación de datos con fechas es una parte crucial del análisis de datos, por lo que es de extrañar que en Pandas existan herramientas para ello. Uno de los problemas que nos podemos encontrar a la hora de preparar los datos es cómo seleccionar elementos entre dos fechas. En esta entrada se mostrarán los pasos para conseguirlo, utilizando para ello un conjunto de datos de … [Leer más...] acerca de Cómo seleccionar elementos entre dos fechas con Pandas