
Los números aleatorios son fundamentales para muchas aplicaciones donde es necesario simular cierta impredecibilidad en los datos. Por ejemplo, a la hora de realizar un muestreo de datos o una simulación de Montecarlo. Por ello, la biblioteca NumPy de Python cuenta con diferentes funciones con las que se pueden crear número aleatorios de forma rápida y eficiente. En esta … [Leer más...] acerca de Generación y manipulación de números aleatorios en NumPy
Python
Python es un lenguaje de programación interpretado con una filosofía basada en la legibilidad del código. Un lenguaje que gracias posee un gran ecosistema de librerías para la ciencia de datos. Por lo que es uno de los más populares en la actualidad entre los científicos de datos. Además, es uno de los lenguajes más deseados y adorados por los programadores según las encuestas de Stack Overflow.
Python es un lenguaje de programación interpretado de propósito general que obliga al uso de una sintaxis clara, gracias a la cual el código es altamente legible. Siendo un lenguaje potente y fácil de aprender. Además, permite utilizar múltiples paradigmas de programación. Lo que permite usar desde programación orientada a objetos, pasando por programación imperativa o funcional.
Los paquetes de Python más utilizados por los científicos son:
- NumPy: permite el tratamiento de datos basados en matrices,
- Pandas: ideal para la manipulación de datos heterogéneos mediante objetos DataFrame,
- SciPy: implementa tareas habituales en computación científica,
- Matplotlib: facilita la visualización de datos y scikit-learn creación de modelos de aprendizaje automático.
Las publicaciones de esta sección versan sobre estas librerías y las bases del lenguaje.
Indexación avanzada en NumPy: cómo simplificar la manipulación de arrays
La indexación es una técnica usada en NumPy para acceder y manipular los valores de los arrays. A pesar de esto, cuando se trabaja con grandes volúmenes de datos la indexación básica puede no ser suficiente. En estos casos es cuando se puede recurrir a la indexación avanzada en NumPy. La indexación avanzada facilita la selección y manipulación de subarrays de una manera … [Leer más...] acerca de Indexación avanzada en NumPy: cómo simplificar la manipulación de arrays
Cómo buscar y reemplazar texto con expresiones regulares en pandas

El análisis y limpieza de datos son tareas clave para el éxito en cualquier proyecto de análisis de datos. En el caso de que algunos de los datos a analizar sean de tipo texto, las expresiones regulares se vuelven una herramienta imprescindible para poder manipular estos de forma precisa y eficiente. Tarea que se puede realizar directamente en Pandas. En Python, la biblioteca … [Leer más...] acerca de Cómo buscar y reemplazar texto con expresiones regulares en pandas
Cómo validar nombres de hojas (sanitizar) y archivos Excel con Python

Al trabajar con archivos Excel en Python, es posible encontrarse con problemas relacionados con los nombres de las hojas o de los archivos. Especialmente cuando estos los introduce un usuario. Por ejemplo, los nombres de las hojas en Excel tienen restricciones de longitud y no permiten ciertos caracteres. Lo mismo que los nombres de archivos. En esta entrada, se explicará cómo … [Leer más...] acerca de Cómo validar nombres de hojas (sanitizar) y archivos Excel con Python
Crear dos gráficos de tarta para ofrecer información detallada de subcategorías en Python
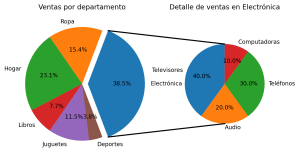
En una entrada hace dos semanas se explicó cómo combinar un gráfico de tarta con uno de barras apiladas para mostrar el detalle de una de las categorías de la tarta. Lo que permite crear representaciones que muestran en detalle los datos. En esta entrada, se verá cómo combinar dos gráficos de tarta para ofrecer información detallada de subcategorías de datos en Python con … [Leer más...] acerca de Crear dos gráficos de tarta para ofrecer información detallada de subcategorías en Python
Uso de contextlib para la gestión de contextos en Python

La seguridad del código es una parte cada vez más importante a la hora de escoger una tecnología. En Python, uno de los mecanismos que facilitan la escritura de código seguro, al mismo tiempo que lo hacen eficiente, son los context managers. Mediante el cual se hace más sencilla la gestión de los recursos. Con este mecanismo se puede garantizar la liberación adecuada de los … [Leer más...] acerca de Uso de contextlib para la gestión de contextos en Python
Cómo eliminar caracteres inválidos en nombres de archivos en Windows y Linux usando Python

Antes de escribir un archivo en disco es importante asegurarse de que este es válido. En Windows, Linux y macOS existen restricciones sobre los caracteres que pueden formar parte del nombre de un archivo. Si un usuario introduce algún carácter no válido, al intentar guardar el archivo este no se podrá crear y se producirá un error en el tiempo de ejecución. Por lo que es una … [Leer más...] acerca de Cómo eliminar caracteres inválidos en nombres de archivos en Windows y Linux usando Python
Crear un gráfico de tarta con subcategorías detalladas mediante barras apiladas en Python
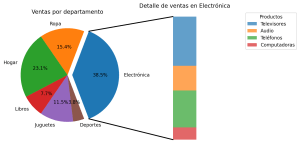
A la hora de representar datos complejos en los que existen categorías y subcategorías puede ser necesario mostrar la distribución general y el detalle de una categoría en específico. Por ejemplo, las ventas de una tienda por departamento y el detalle de un departamento en específico. Una opción para conseguir esto es combinar un gráfico de tarta, con la que se puede mostrar la … [Leer más...] acerca de Crear un gráfico de tarta con subcategorías detalladas mediante barras apiladas en Python
Trabajando con números de alta precisión en Python: El módulo decimal

El tipo de dato más habitual para trabajar con número en Python es float. Este tipo permite almacenar números reales positivos o negativos con precisión doble, el equivalente al tipo double de C u otros lenguajes. Sin embargo, en situaciones es necesario contar con una mayor precisión, como en cálculos financieros donde los errores de redondeo pueden tener consecuencias … [Leer más...] acerca de Trabajando con números de alta precisión en Python: El módulo decimal
Cómo calcular el rango de red y convertir máscaras CIDR en Python

Al configurar redes de ordenadores, el rango de red es uno de los parámetros claves. El rango de red se puede representar usando la notación clásica de máscara de subred o el formato CIDR (Classless Inter-Domain Routing). En esta entrada, se explicará el formato CIDR y cómo traducirlo a la notación clásica de máscara de subred. Incluyendo el código Python para realizar estos … [Leer más...] acerca de Cómo calcular el rango de red y convertir máscaras CIDR en Python
Introducción a las gráficas de tarta en Matplotlib

Junto a las gráficas de barras, una de las mejores opciones para visualizar datos categóricos son las gráficas de tarta. Mediante las cuales se puede mostrar el peso que tienen cada una de las categorías en el total de los datos. En esta entrada se explicarán las bases para la creación de gráficas de tarta en Matplotlib y algunas de las opciones más interesantes.Creación de … [Leer más...] acerca de Introducción a las gráficas de tarta en Matplotlib
Decoradores en Python: Qué son, cómo crear uno y ejemplos

Python es un lenguaje de programación que destaca por su simplicidad, flexibilidad y con el que es fácil escribir código limpio. Siendo los decoradores una de las características del lenguaje que más ayudan a esto. Los decoradores permiten extender el comportamiento de las funciones y métodos de una manera elegante, facilitando la reutilización del código. En esta entrada, se … [Leer más...] acerca de Decoradores en Python: Qué son, cómo crear uno y ejemplos